多车跟随仿真(强化学习)
本教程将会引导读者完成 多车跟随仿真(强化学习) 的演示。在使用此功能之前,确保已经完成了 仿真系统搭建
提示
除第一辆小车以外,每一辆小车都可以根据视轴前方的小车做跟随机动
提示
在某些电脑环境中,即使按照仿真系统搭建步骤完成搭建,在运行
rosinit时,可能会出现Cannot connect to ROS master at http://localhost:11311. Check the specified address or hostname字样。解决的办法是,将
rosinit命令改为,rosinit("ip",端口)。如下图所示: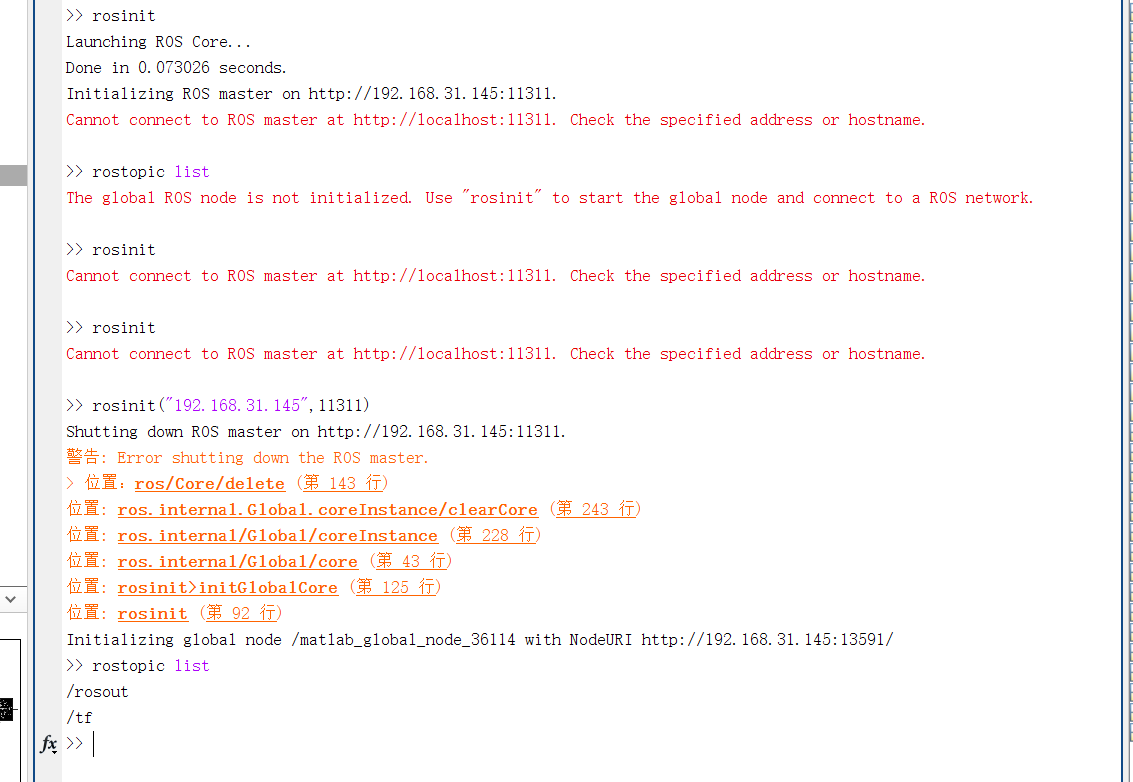
解决办法
多车跟随策略训练与评估
- 打开
kk-robot-swarm/src/matlab/pfc_rl/train_a2_pfc_td3.m多车跟随策略训练脚本文件。
提示
文件名
a2表示只有1台车跟随前车,td3表示所使用的强化学习算法名称——双延迟深度确定性策略梯度(Twin Delayed Deep Deterministic Policy Gradient)
部分代码说明:
% 设置打开的多车跟随策略仿真训练环境
mdl = "a2_pfc_rl";
open_system(mdl);
% 加载强化学习训练模块
blks = mdl + ["/RL Agent"];
env = rlSimulinkEnv(mdl,blks,obsInfo,actInfo);
% 重置仿真训练环境的部分参数,如小车的位置,具体详见a2pfcResetFcn.m脚本文件
env.ResetFcn = @a2pfcResetFcn;
% 创建跟随策略训练智能体-TD3算法
agent = createPFCAgent(obsInfo,actInfo);
% 设置仿真结束时间Tf为120秒,采样时间Ts为0.1秒,最大训练回合数maxepisodes为30000,每个回合的仿真步长为maxsteps
Tf = 120;
Ts = 0.1;
maxepisodes = 30000;
maxsteps = ceil(Tf/Ts);
% 不会根据跟随仿真设置的奖励值(如某个回合的奖励值达到100以上)中途停止训练
trainingOpts = rlTrainingOptions(...
'MaxEpisodes',maxepisodes,...
'MaxStepsPerEpisode',maxsteps,...
'Verbose',false,...
'Plots','training-progress',...
'StopTrainingCriteria','EpisodeReward',... % 中止训练条件为回合奖励值
'StopTrainingValue',100,... % 中止训练的奖励值为100
'ScoreAveragingWindowLength',10);
% 不根据跟随仿真设置的奖励值中途停止训练
trainingOpts = rlTrainingOptions(...
'MaxEpisodes',maxepisodes,...
'MaxStepsPerEpisode',maxsteps,...
'Verbose',false,...
'Plots','training-progress',...
'ScoreAveragingWindowLength',10);
% 是否开启异步分布式训练 硬件性能配置较高时建议开启
trainingOpts.UseParallel = true;
trainingOpts.ParallelizationOptions.Mode = "async";
trainingOpts.ParallelizationOptions.DataToSendFromWorkers = "Experiences";
trainingOpts.ParallelizationOptions.StepsUntilDataIsSent = 32;
% 是否开启训练模式 true为训练模式 false为评估模式
doTraining = false;
% 保存已训练好的神经网络策略数据
save('a2_pfc_rl.mat', 'agent');
% 评估模式查看仿真运行效果
simOptions = rlSimulationOptions('MaxSteps',1200);
experience = sim(env,agent,simOptions);
totalReward = sum(experience.Reward);
提示
在进行训练以前, 避免覆盖已经训练好的神经网络。还请在
train_a2_pcf_td3.m文件中做如下修改:
- 代码67行,
save('a2_pfc_rl.mat', 'agent');,将文件名称a2_pfc_rl.mat修改为自己训练的文件名称。例如:rl_training_xxx.mat- 代码56行,
doTraining = false;,改为true,进行训练- 代码62行,
load('a2_pfc_rl.mat','agent');,将文件名称改为自己训练的文件名称即可- 该强化学习对CPU和内存要求较高,大概需要
Intel i9-10700KCPU及以上,内存32GB及以上- 如果您的电脑硬件达不到要求,将代码 31-39行取消注释,同时将
'StopTrainingValue',100,...中的100,改为80,然后注释掉 42-47行。开始训练- 更多详情请见代码注释以及本教程前后部分wiki
- 将多车跟随策略训练脚本文件
train_a2_pfc_td3.m第56行代码改为doTraining = true;,即可开启运用强化学习方法训练多车跟随策略。
如图1所示,点击 运行 按钮,matlab会自动打开 a2_pfc_rl.slx 文件;
图1 运行多车跟随策略训练脚本文件
同时,matlab将自动打开 a2_pfc_rl.slx 文件,并且开启强化学习算法训练模式。如图2所示。
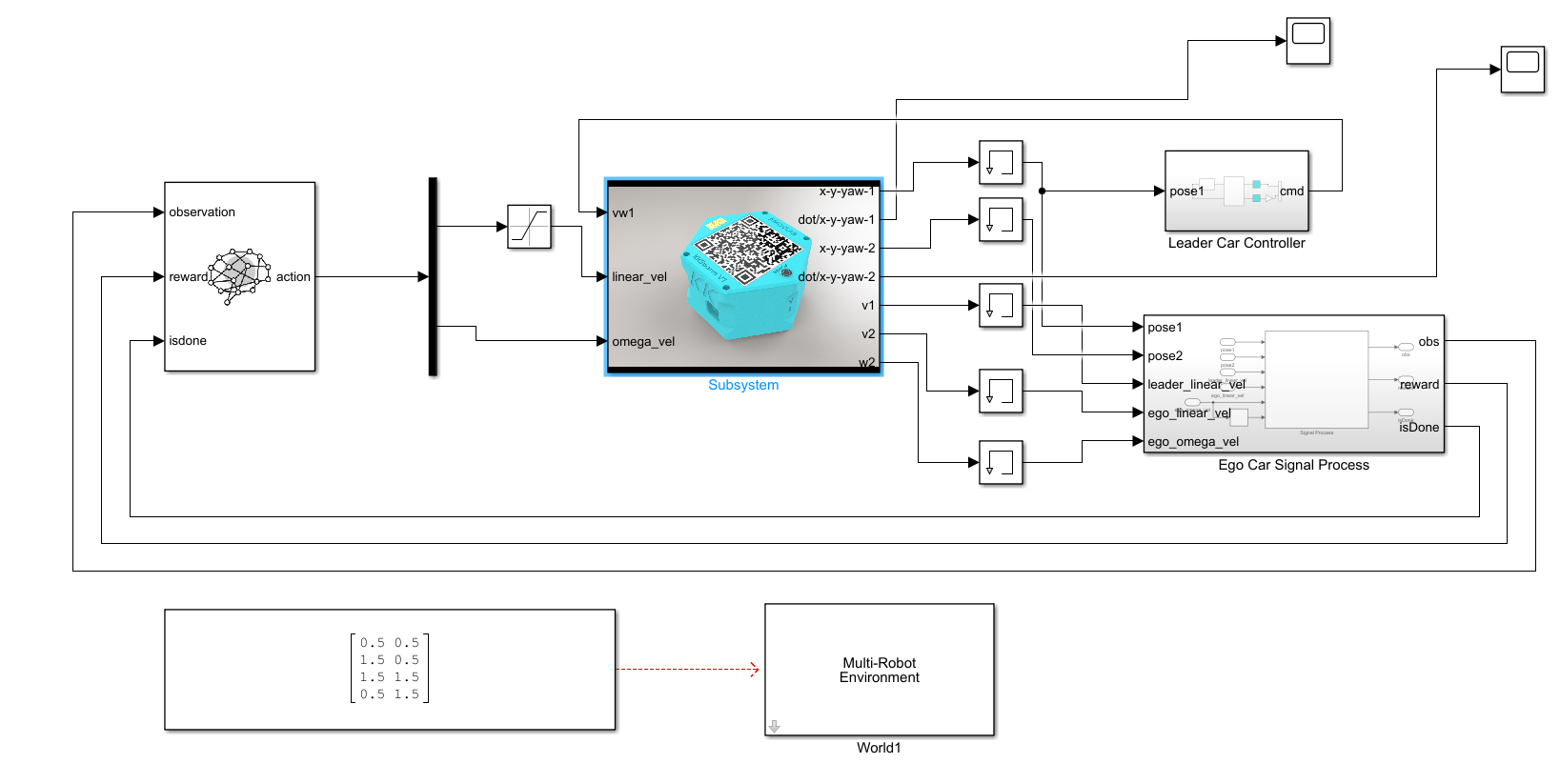
图2 a2_pfc_rl.slx文件
以及将会自动打开训练效果窗口和训练进程窗口(包括每次训练的奖励值情况),如图3所示。
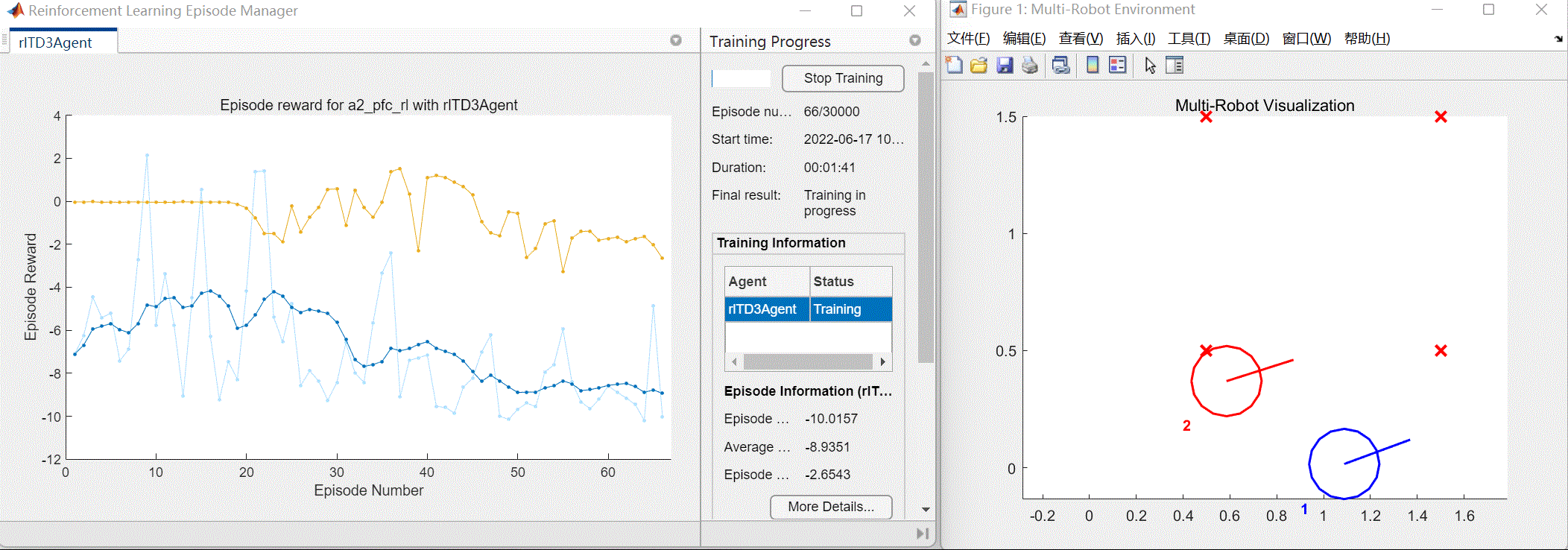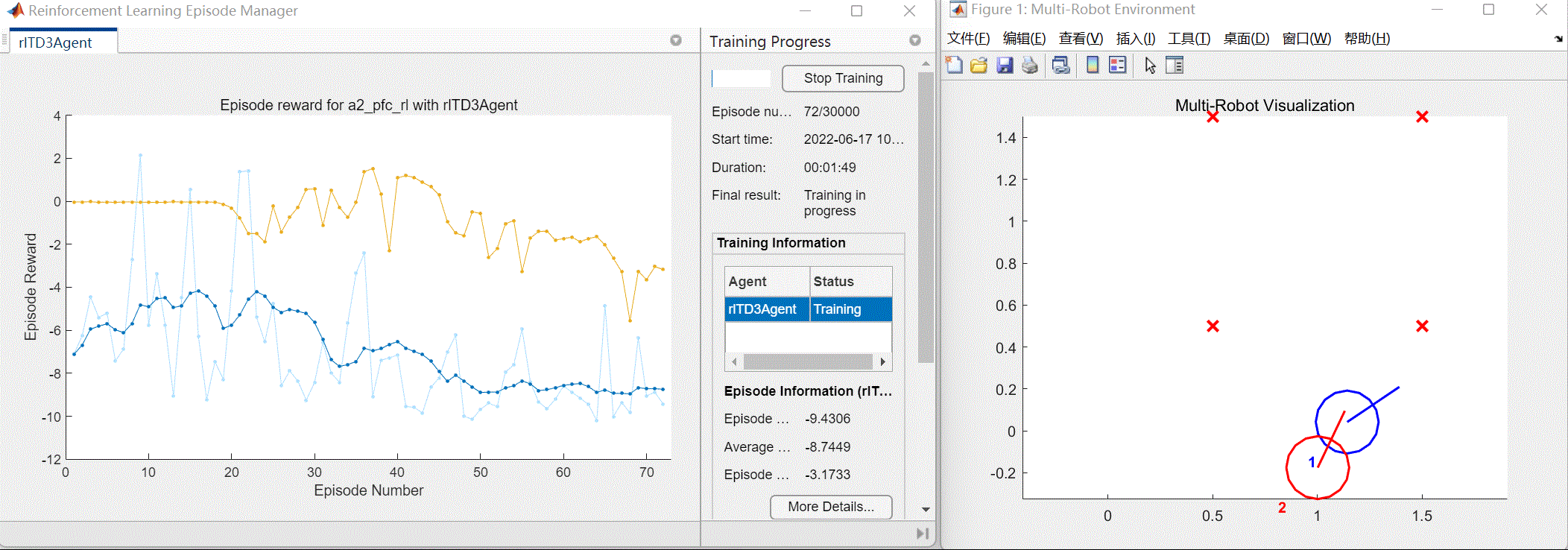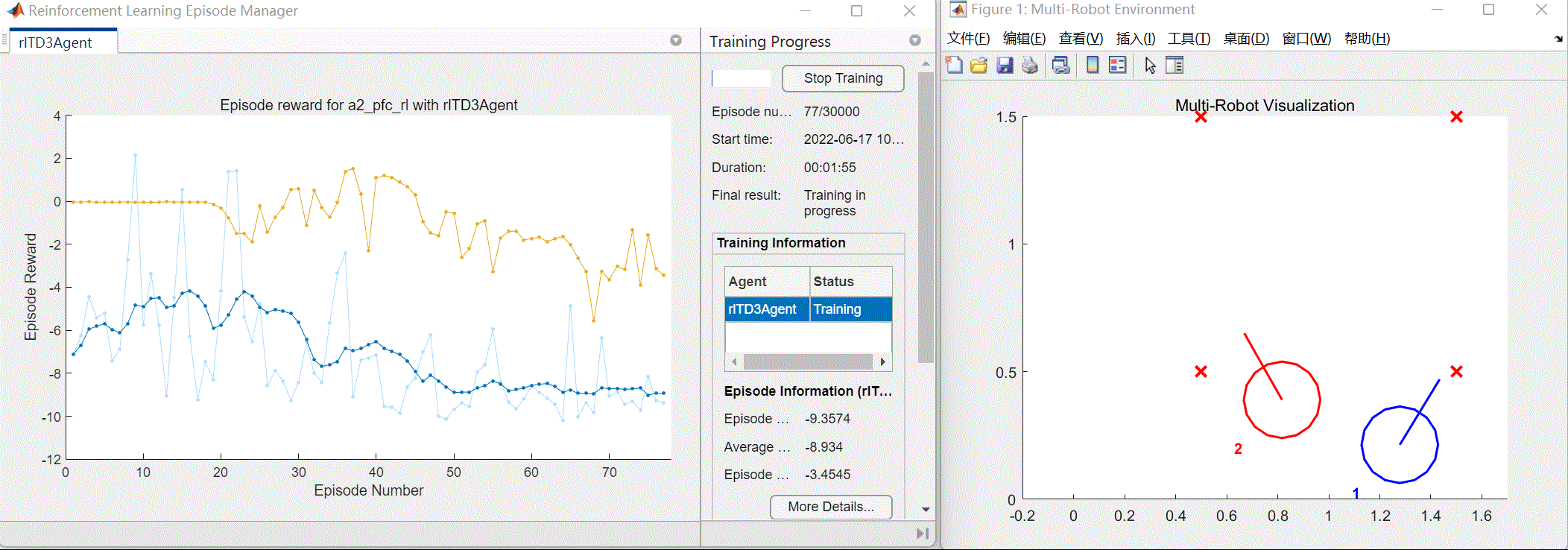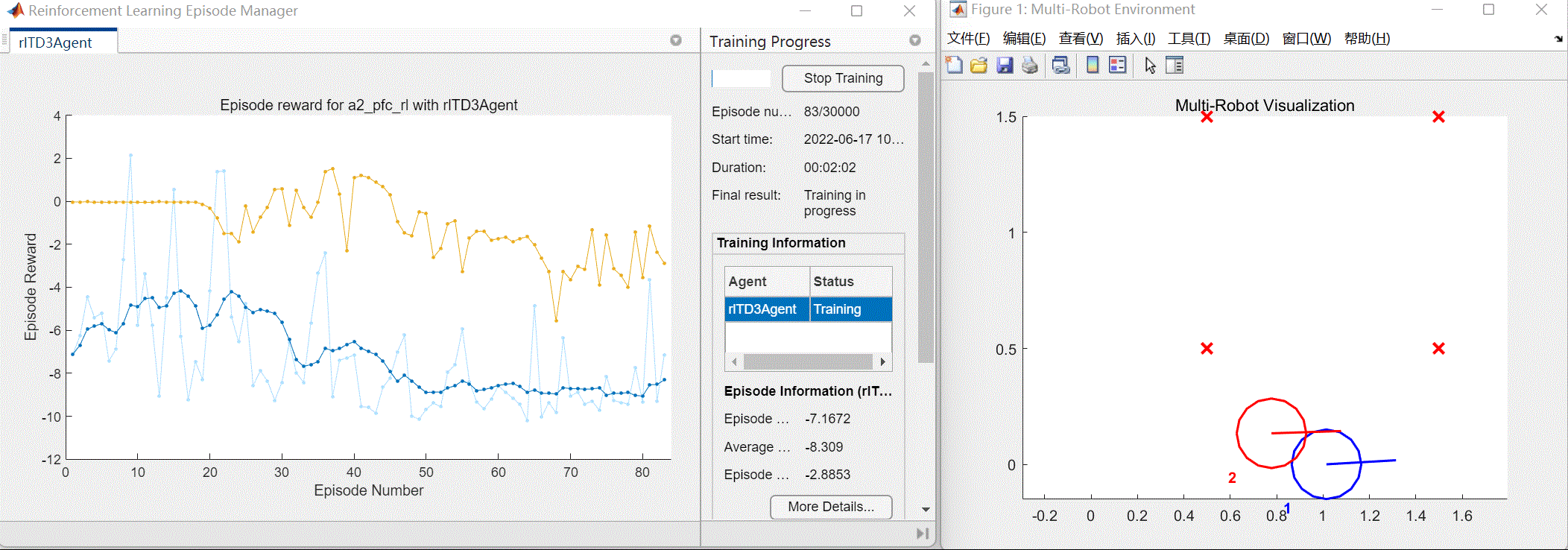
图3 训练效果与进程窗口
-
训练完成后,matlab会自动保存已训练好的神经网络策略数据文件,如
a2_pfc_rl.mat文件 -
将多车跟随策略训练脚本文件
train_a2_pfc_td3.m第56行代码改为doTraining =false,取消多车跟随策略训练。 同时将脚本第70-72行代码注释,然后点击运行按钮,将会打开a2_pfc_rl.slx文件,然后点击该文件菜单栏上的仿真--运行即可查看和评估当前使用强化学习算法训练的多车跟随效果。如图4所示。
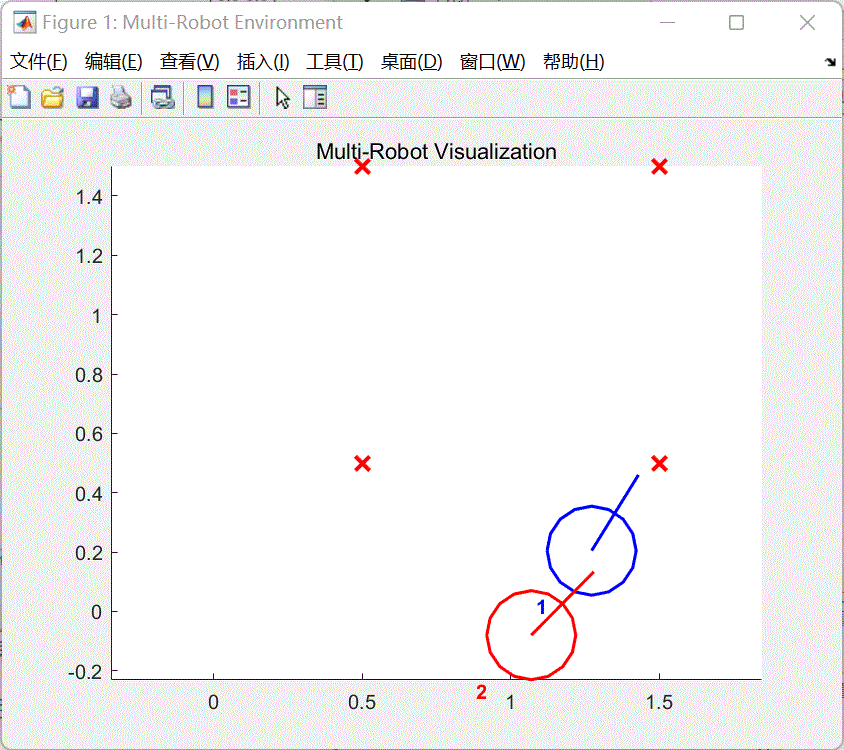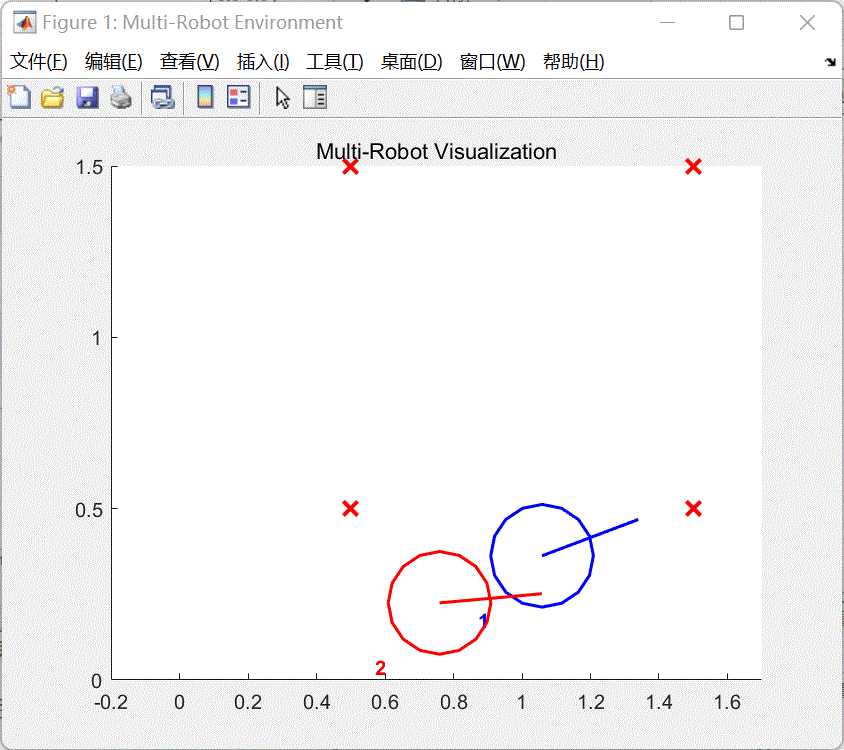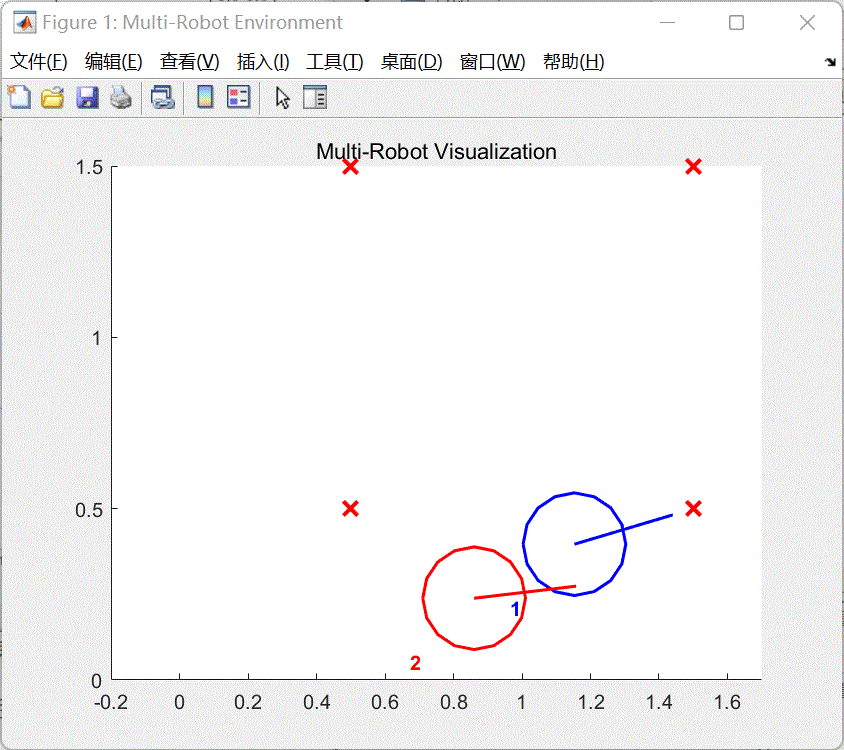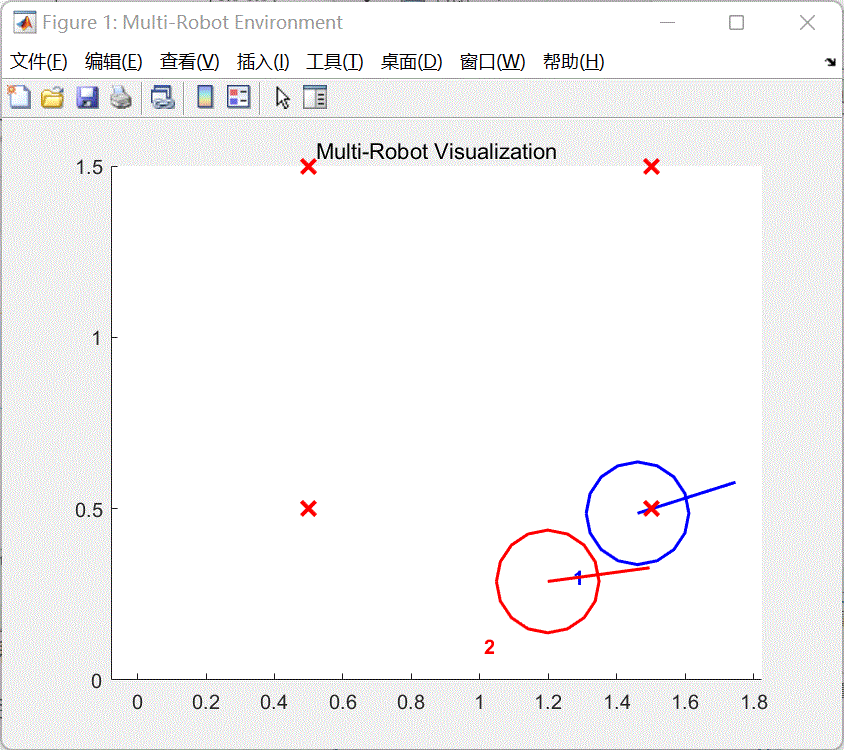
图4 训练效果
多车跟随策略生成与部署
- 打开
kk-robot-swarm/src/matlab/pfc_rl/gen_pfc_policy.m单车跟随策略生成脚本文件,如图5所示。点击运行按钮,matlab会自动生成PFC_Policy.m和PFC_Agent.mat两个文件,如图6所示。用户可以拷贝这两个文件,在自己的Simulink工程文件中按照正常脚本文件中的m函数调用多车跟随策略方法。
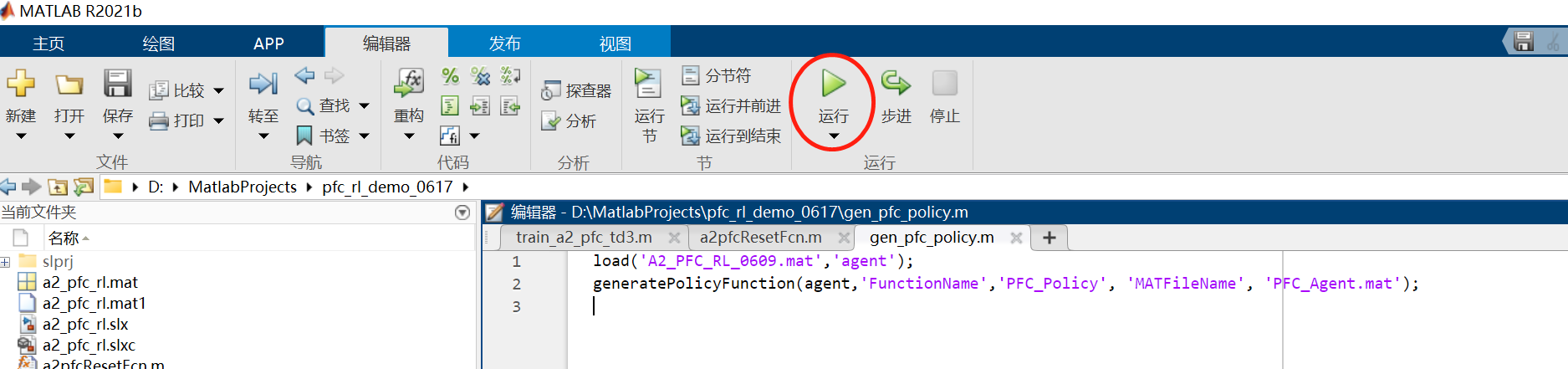
图5 运行单车跟随策略生成脚本文件
图6 matlab自动生成的单车跟随策略文件
- 打开
kk-robot-swarm/src/matlab/pfc_rl/b6_pfc_rl.slx文件,如图7所示。双击图7中的controller模块,可以看到跟随控制模块,名称为one_car_pfc,如图8所示。
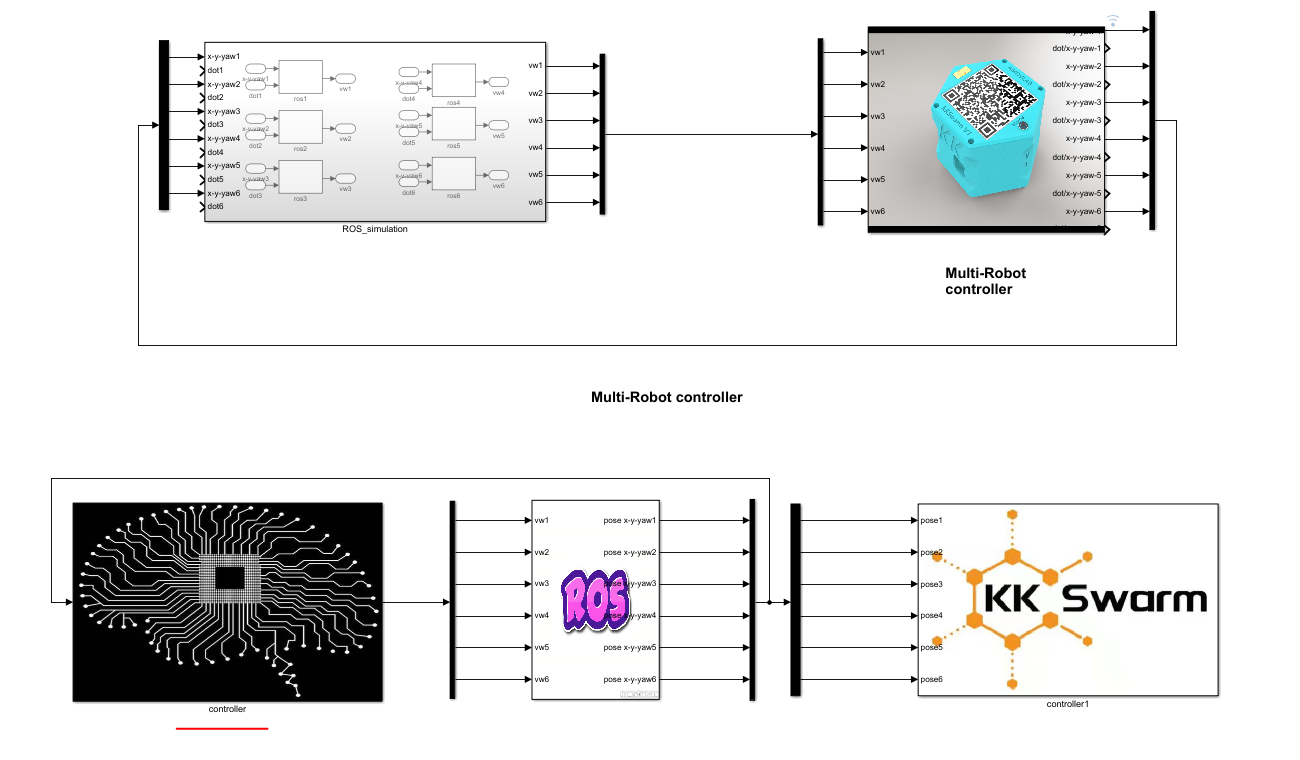
图7 运行多车跟随仿真环境
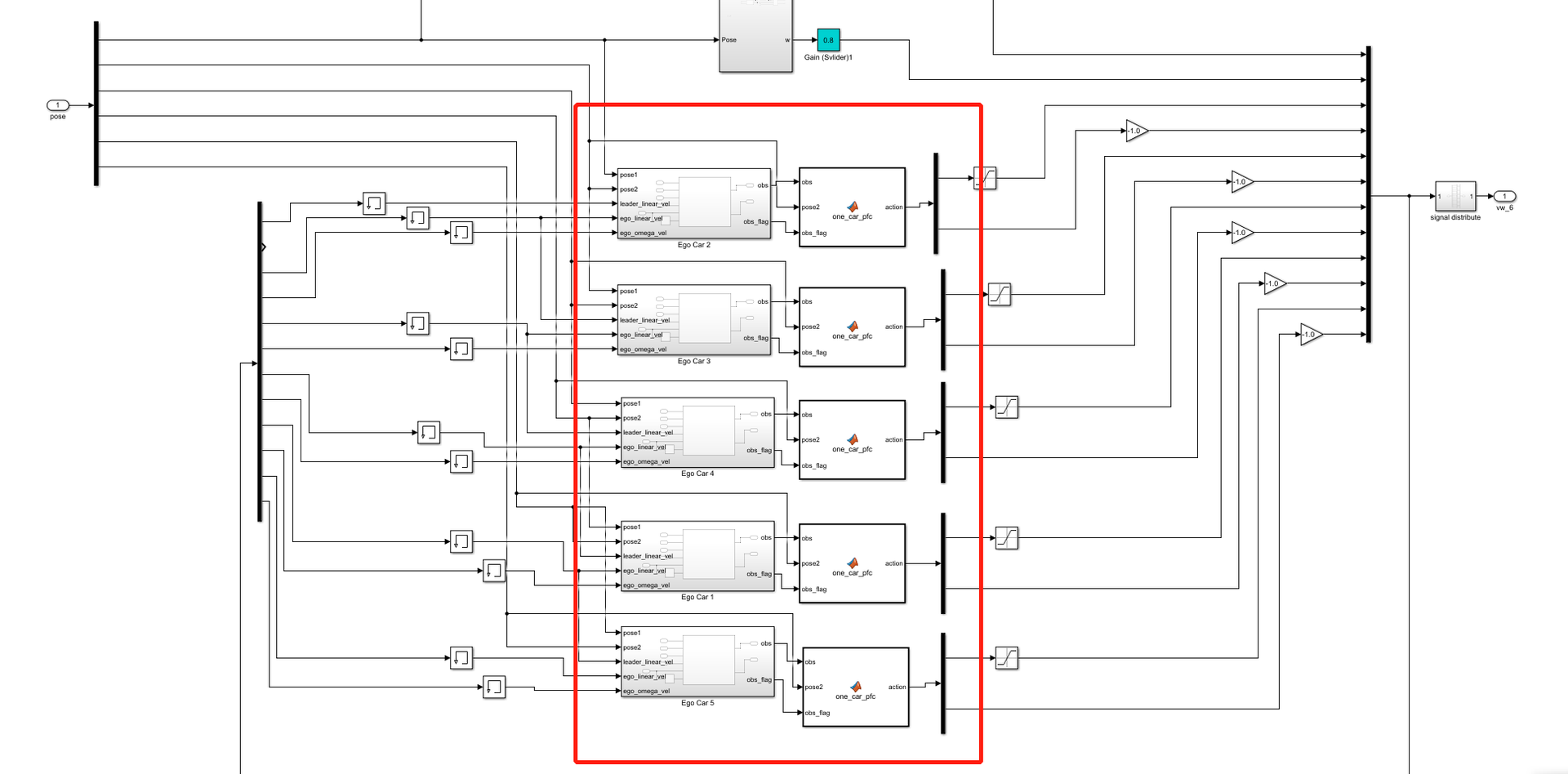
图8 多车跟随仿真环境的跟随控制模块
目前,跟随控制模块采用了 混合控制策略,考虑到前后车横距和纵距有时很大,可以采用比较简单的直线跟车策略。双击跟随控制模块,可以看到单车跟随的控制逻辑,示例代码如下:
function action = one_car_pfc(obs, pose2, obs_flag)
longitudinal_rel_dist = obs(3);
lateral_rel_dist = obs(6);
% 在前后车横距和纵距一定的情况下,使用强化学习训练的单车跟随策略
if longitudinal_rel_dist > -0.25 && abs(lateral_rel_dist) <=0.225 && longitudinal_rel_dist < 0
action = double(PFC_Policy(obs));
% 其它情况,使用直线跟车策略
else
action = simple_pfc(obs(1), obs(2), pose2(3));
end
if obs_flag==0
action = [0.0, 0.0];
end
end
% 直线跟车策略
function action = simple_pfc(x_delta, y_delta, yaw2)
kk = -1.0;
new_theta_cmd = atan2(y_delta, x_delta);
delta_theta = angdiff(yaw2, new_theta_cmd);
angular_speed = kk * delta_theta;
new_omega_cmd = angular_speed;
action = [0.225, new_omega_cmd];
end
- 在matlab命令行中输入
rosinit,启动ROS Master节点,如图9所示。
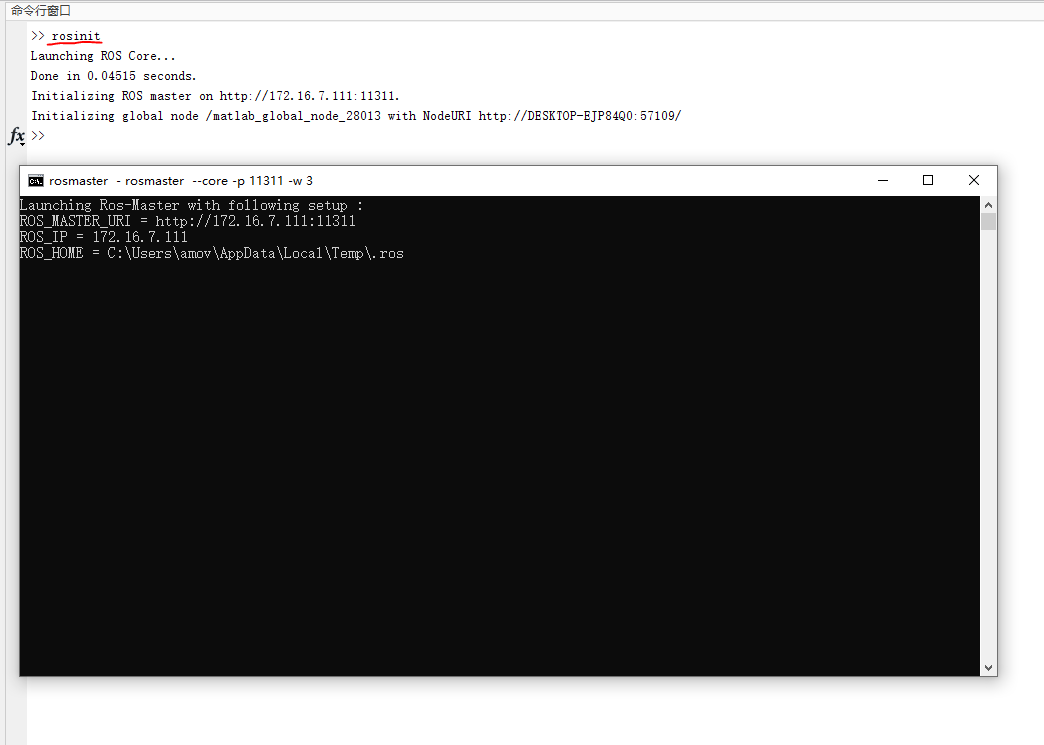
图9 rosinit
- 打开matlabR2021b,在命令行中输入命令
setenv('MW_MINGW64_LOC','C:\MinGW\'),然后再输入mex -setup C++。为matlab配置 MinGW 环境。如图10所示:

图10 Matlab配置MinGW
- 点击菜单栏上的
ROS--Deplay to Localhost。如图11所示
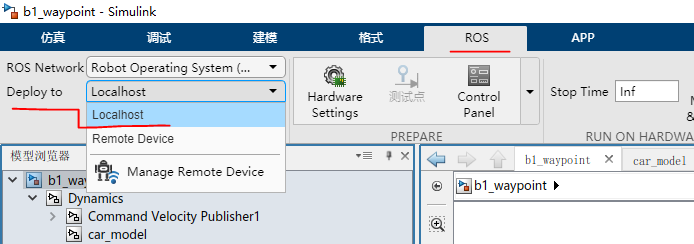
图11 deploy
-
接着点击菜单栏上的
仿真--运行。启动仿真, -
等待编译完成,系统将会运行仿真。如图12所示:
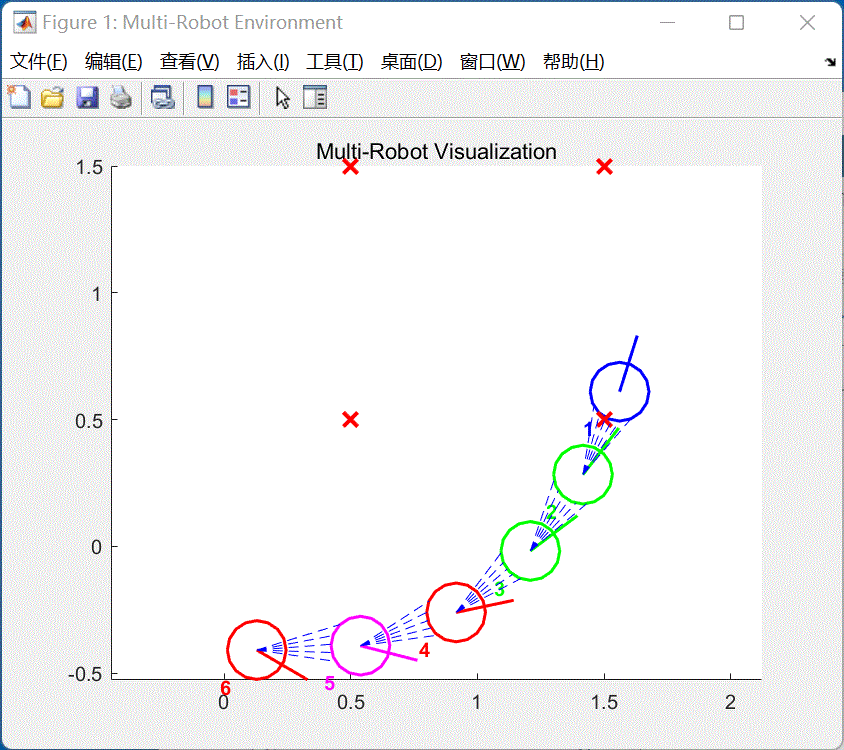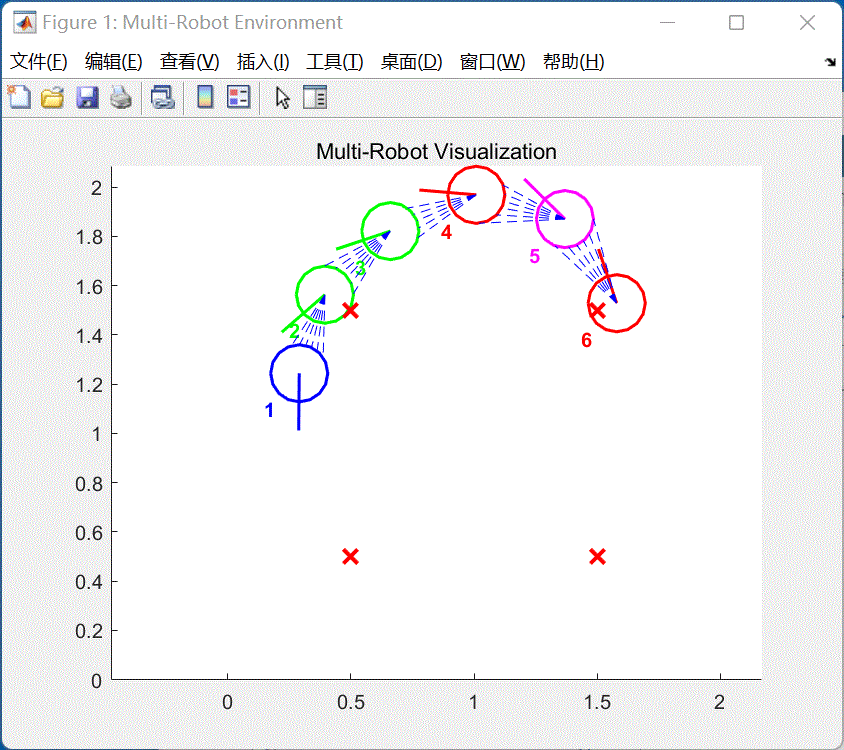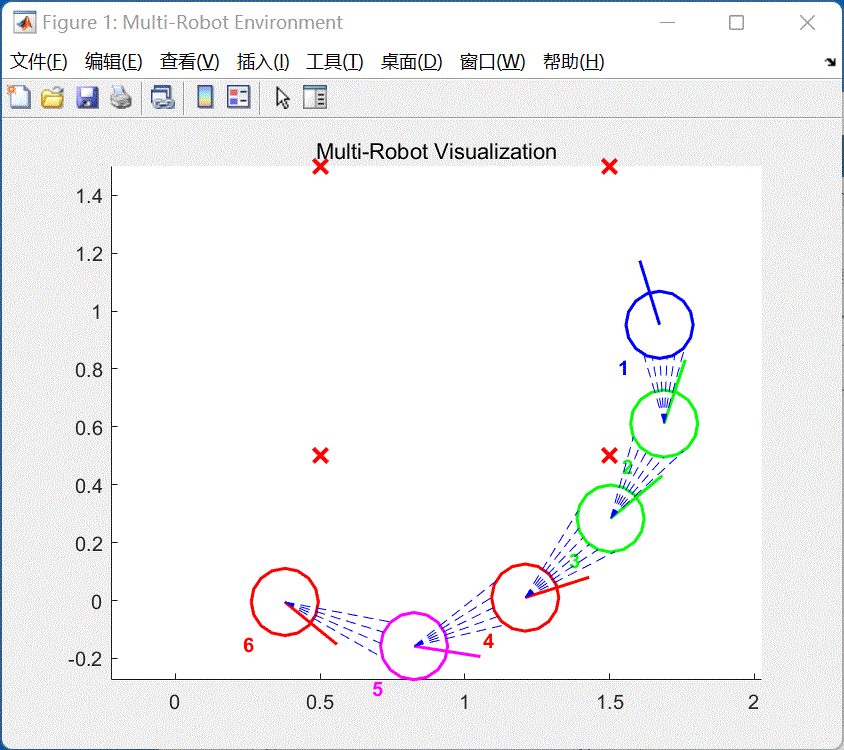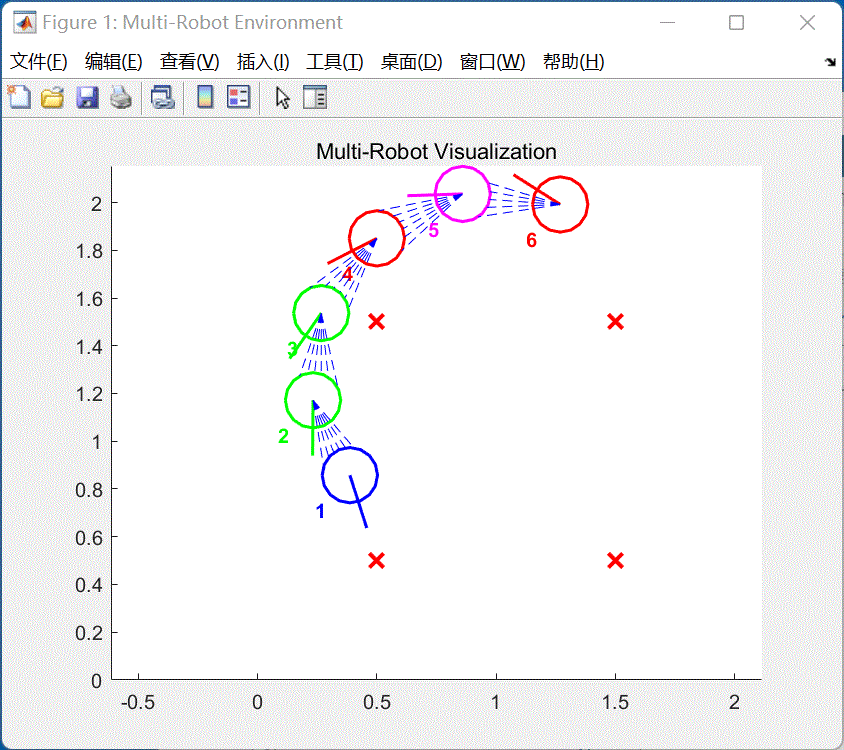
图12 运行
一键生成ROS代码
-
将多车跟随环境训练生成的
PFC_Policy.m和PFC_Agent.mat两个文件与kk-robot-swarm/src/matlab/pfc_rl/c6_pfc_rl.slx放在一起 -
在matlab命令行中输入
rosinit,启动ROS Master节点 -
打开
kk-robot-swarm/src/matlab/pfc_rl/c6_pfc_rl.slx文件,如图14所示。
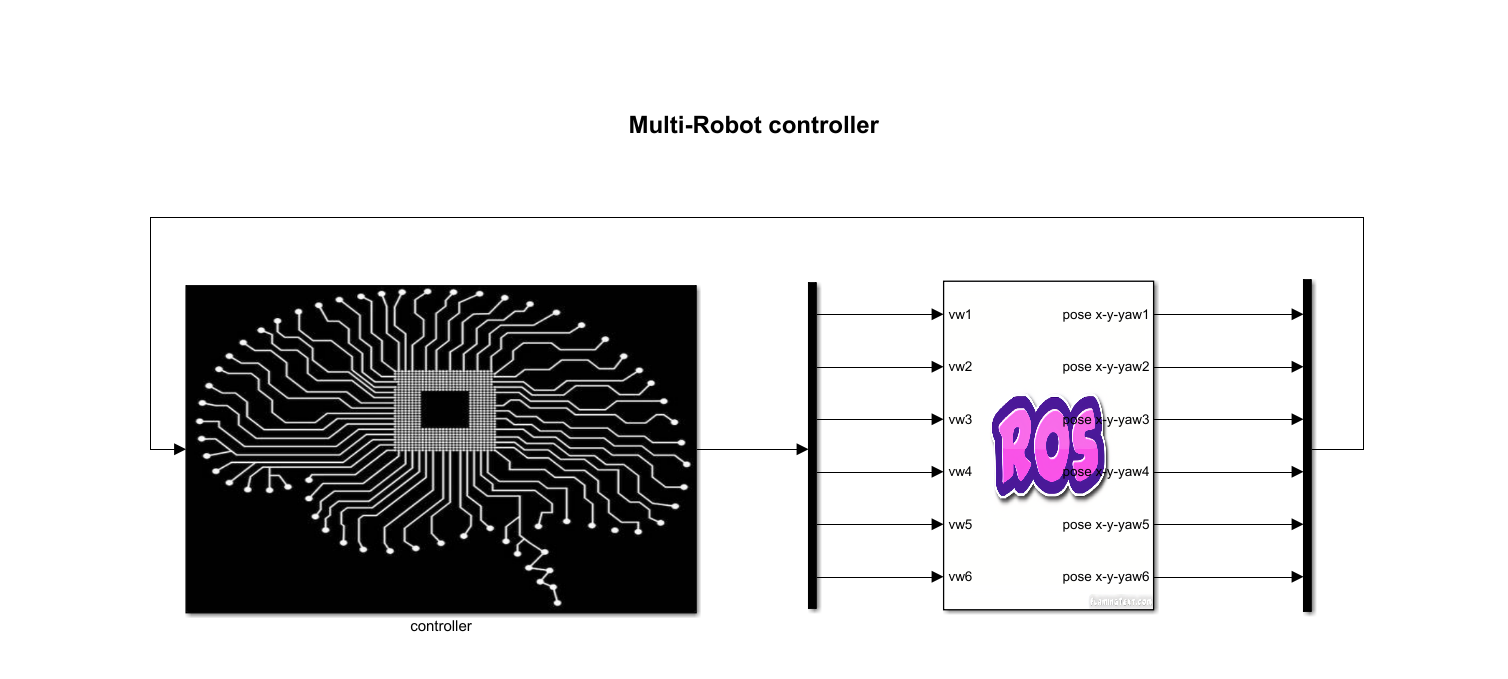
图12 c6_pfc_rl.slx
- 与
c6_pfc_rl.slx文件类似,双击图14中的controller模块,可以看到单车跟随控制模块,名称为one_car_pfc,如图15所示。
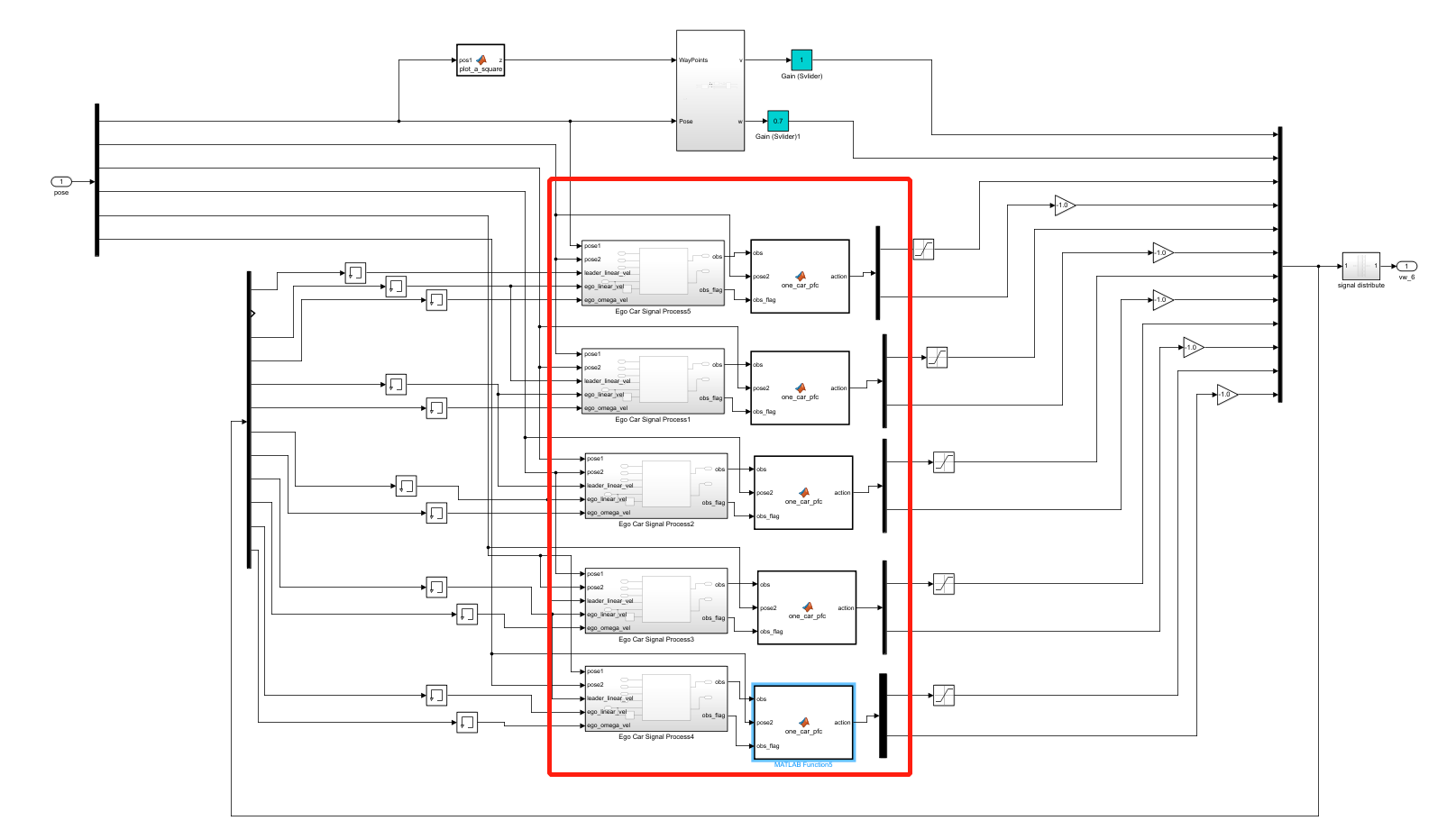
图15 controller模块
注意
多车跟随Demo在小车数量较多的时候(6车以上),存在甩尾和速度跟不上前车的情况
- 考虑到场地限制和甩尾情况,将5号车和6号车
one_car_pfc模块中的直线跟车策略的线速度参数增加了增益系数,分别为1.2和1.5,如图16、图17所示。
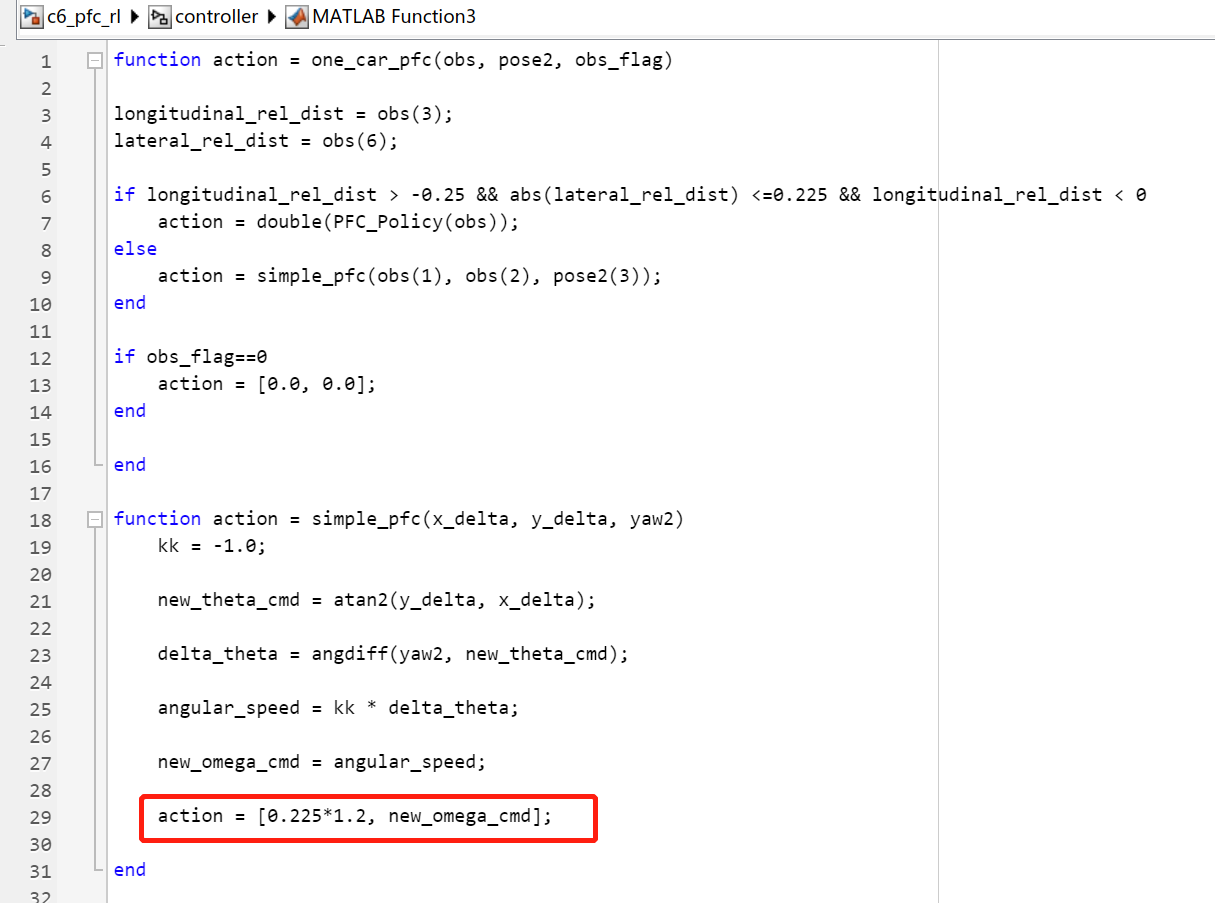
图16 增益系数1.2
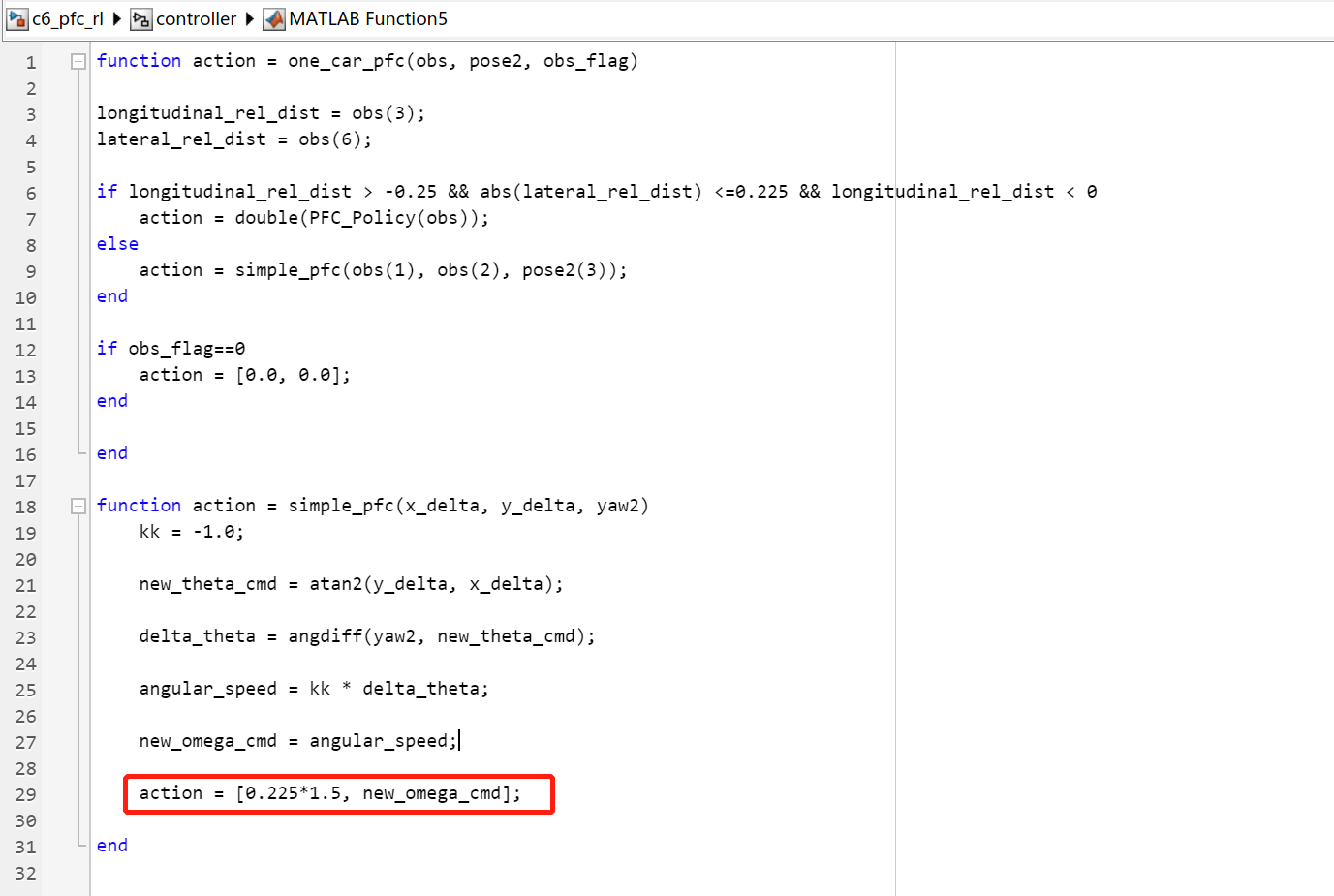
图17 增益系数1.5
-
在编译代码之前,确保启动了
rosinit -
然后在菜单栏上的
ROS--Deploy to Remote Device。如图18所示。
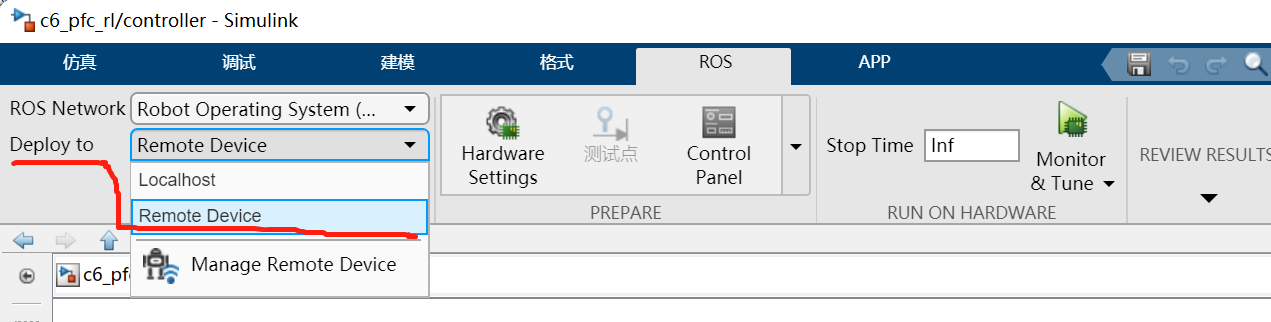
图18
- 然后点击菜单栏上的
ROS--Build Model--Build Model一键生成ROS代码,如图19所示
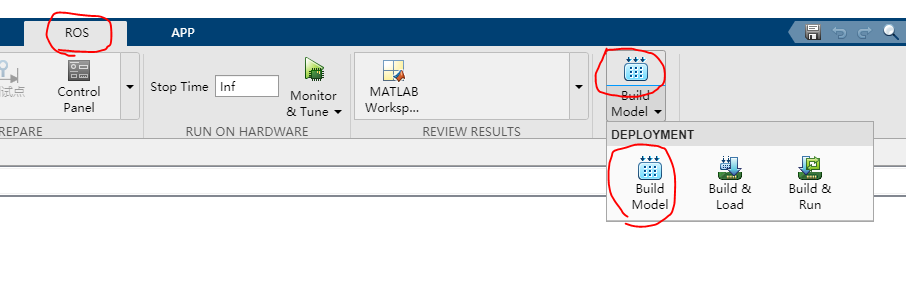
图19 生成ROS代码
-
等待编译完成以后,将会看到生成的压缩包文件,如
c6_pfc_rl.tgz。 -
将生成的 ROS 代码复制到Linux系统中,并解压至
kk-robot-swarm/src/swarm/下,然后编译整个工作空间即可。