KK-SWARM简介
项目简介
KK目标
开源机器人集群项目KKSwarm,由易科机器人实验室和阿木实验室联合匠心打造。
KKSwarm项目旨在为研究人员搭建一个高效、易用的集群研究平台。结合ROS强大的开源生态,让研究人员或者工程师能够快速上手开发。同时也兼顾到理论研究和工程落地之间的跨度,KKSwarm项目通过搭建轻量级的仿真环境,再通过参数拟合让仿真和真实环境一致,让仿真环境和真实环境高度匹配,可以实现多智能体等算法的直接过渡,配合上低成本的机器人集群,可以快速在物理环境中验证算法,以达到工程落地的目的。
KK由来
KK(Kilo Ken)Swarm,致敬Kevin Kelly机器社会进化论,一个奉行极简主义的自组织机器人集群,具有丰富的机器人功能,如视觉、控制、学习、协同。同时追求超低成本、超大规模,致力于使群 体智慧走进物理世界。众多低成本机器人互相连接,进而产生他们的信息交流和反馈,相互学习,产生 秩序,以达到集体目标,Kevin Kelly将其称为“群智涌现”。
项目功能
KKSwarm项目正在成长之中,目前已正式推出的功能有:
- 独创的全局视觉定位系统,为大规模机器人集群提供低成本、高精度定位服务;
- 提供基于
MATLAB/simulink仿真与算法开发环境,以及KKSwarm simulink模板,可一键生成ROS代码并部署至KKSwarm机器人系统; - 提供KKDeep深度强化学习Simulink模板,免去繁琐的环境配置,训练后控制器可一键生成代码部署至机器人集群;
- 提供ROS rviz在线可视化功能,直观展示集群运行情况;
- 提供Matlab ROS 日志分析功能,方便采集数据进行分析,提升研发效率;
- 支持虚拟雷达,低成本实现复杂分布式算法测试。
系统说明
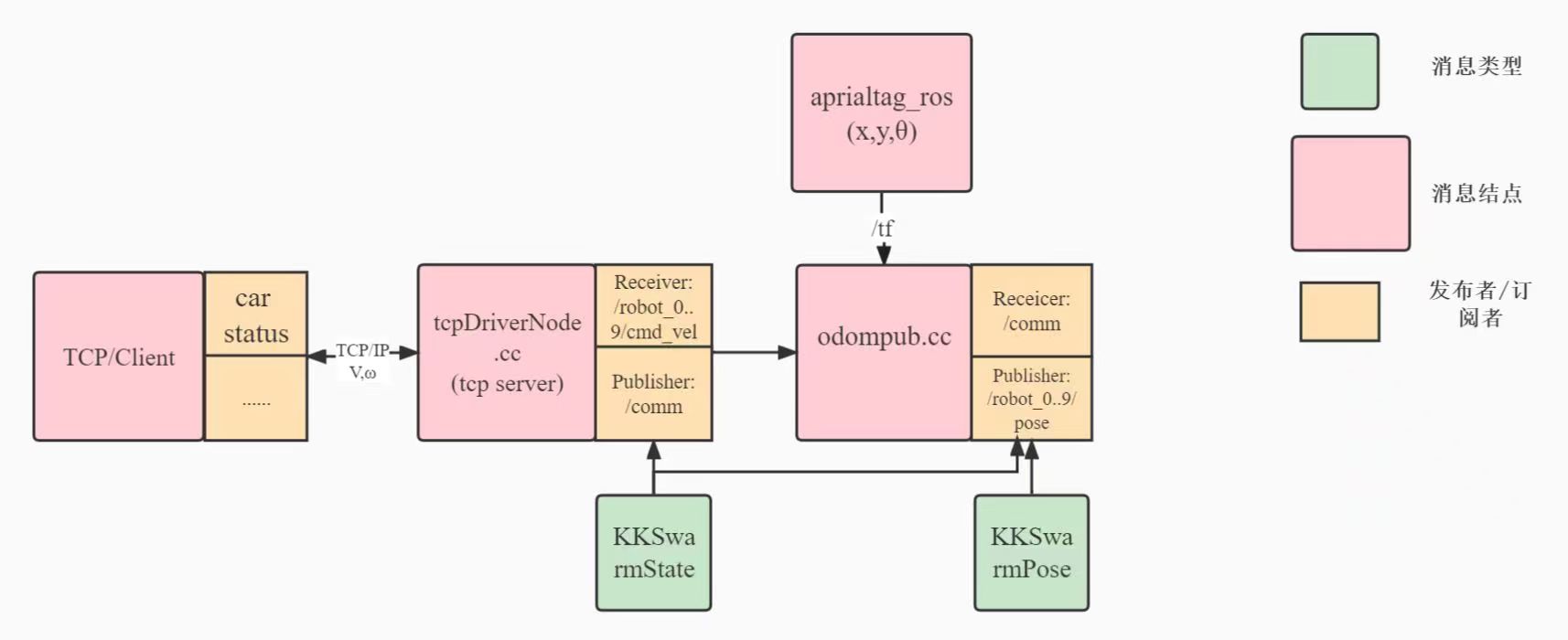
系统数据流向图
kkswarm项目通过路由器搭建局域网,集群小车为客户端。所有的算法和定位系统均在服务器主机上进行计算。然后通过TCP/IP协议,将控制指令发送给集群小车,从而控制小车的运动。同时主机服务器通过摄像机实时获取集群小车的位置和方向。
项目地址
https://github.com/kkswarm/kk-robot-swarm
KKSwarm软件框架
软件架构说明:
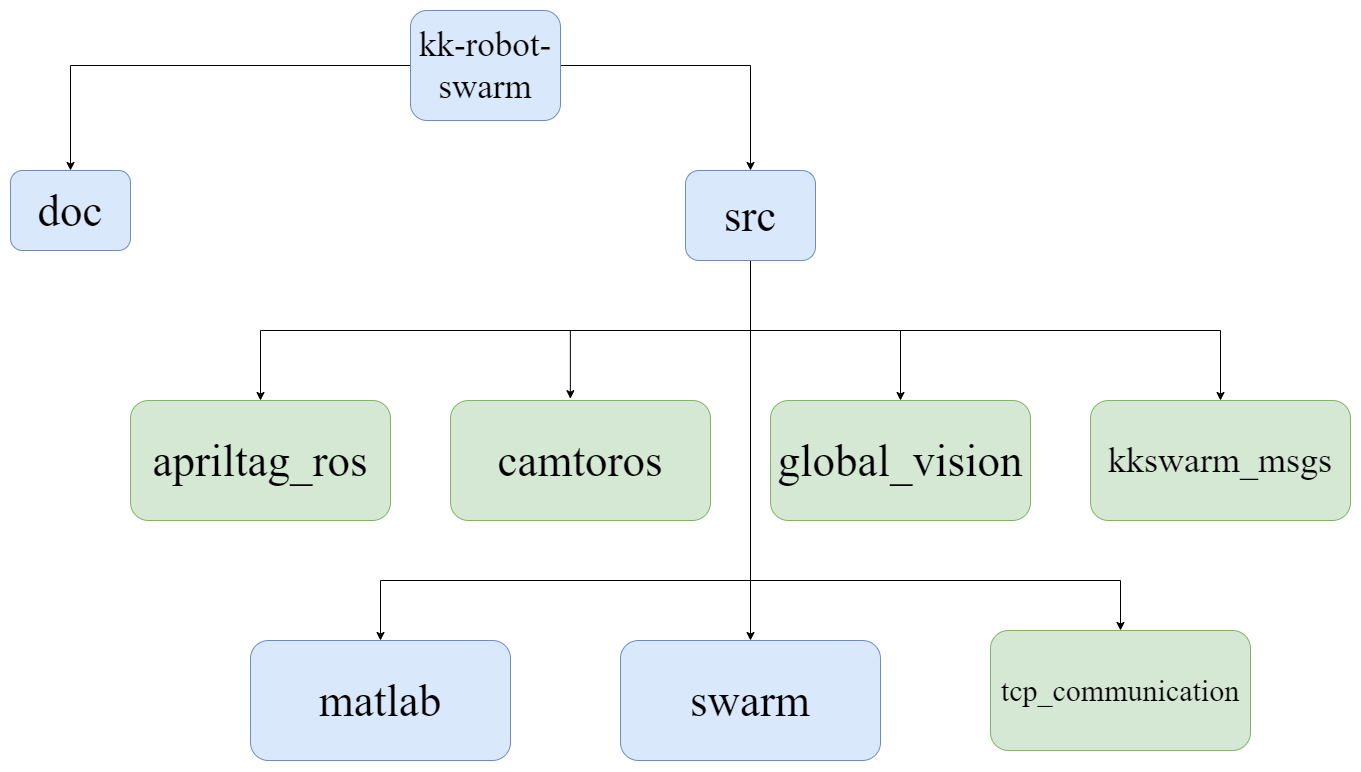
KKSWARM软件框架
- 图示说明:蓝色代表文件夹,绿色代表功能包
doc:该文件夹主要存放和kkswarm相关的论文以及其他文件和图片src:该文件夹主要存放ROS以及matlab代码apriltag_ros:功能包,提供AprilTag的ROS接口camtoros:功能包,提供海康威视相机的ROS接口global_vision:功能包,提供集群小车的位置和方向等数据kkswarm_msgs:功能包,提供kkswam项目使用的自定义ROS消息类型tcp_communcation:功能包,提供主机和集群小车的通信节点。用于接收小车状态信息和发送指令matlab:该文件夹下主要存放matlab相关仿真模块以及代码swram:该文件夹下主要存放由matlab生成的ROS功能包
产品参数
外形及尺寸
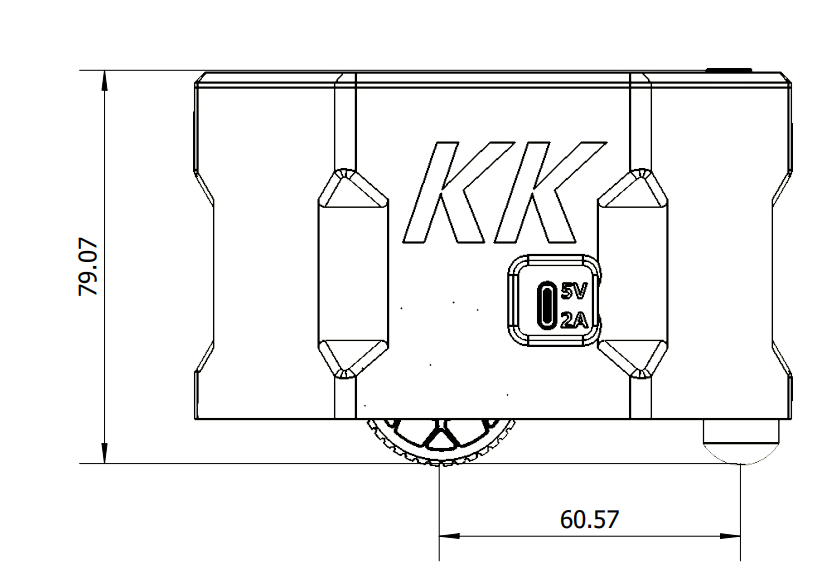
侧视图
俯视图
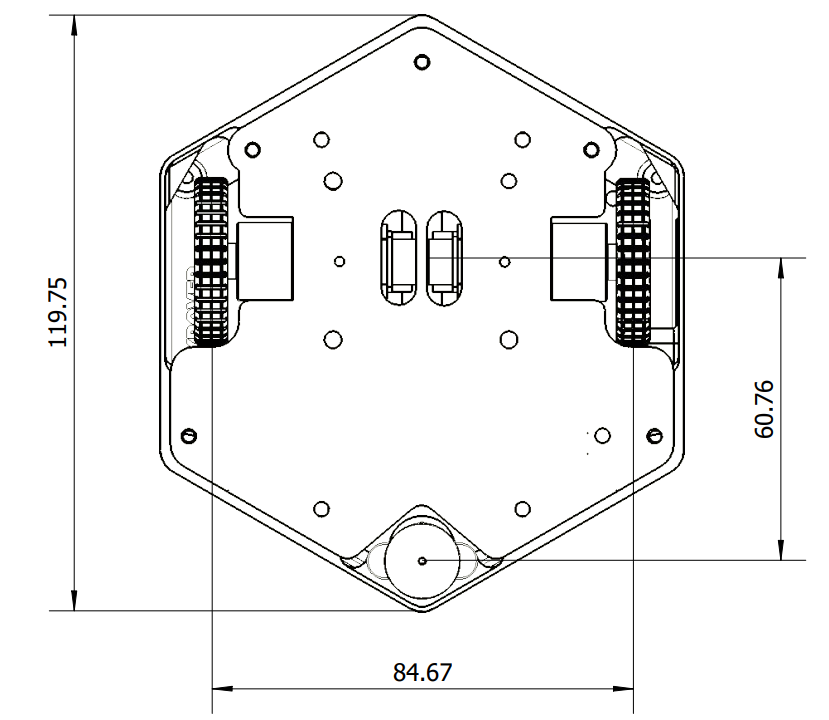
仰视图
小车性能参数
| 类型 | 参数 | 单位 |
|---|---|---|
| 外形尺寸 | 119.75 * 105.01 * 79.07 | 毫米 |
| 轮距 | 84.67 | 毫米 |
| 车轮直径 | 60.5 | 毫米 |
| 驱动方式 | 两轮差速 | / |
| 最大移动速度 | 0.6m/s | 米 / 秒 |
| 空载续航 | 3h | 小时 |
| 满载续航 | 2h | 小时 |
快速上手综述
KKSWARM可以做到开箱即用,凡是购买本产品的用户。可以根据以下内容,将小车的功能运行起来。
产品清单
| 硬件名称 | 硬件型号 | 硬件尺寸 | 备注 |
|---|---|---|---|
| 海康威视灰度相机 | MV-CA013-21UM | / | / |
| 海康威视相机镜头 | 4nm镜头 | / | / |
| 龙门支架 | / | / | / |
| 双U型支架 | / | / | A面接横杆,B面接相机 |
| 地毯 | / | 2.2m x 2.2m | / |
| 小车 | / | / | / |
| 迷你主机 | CPU: Intel i7-8565U,四核八线程 GPU: Intel UHD Graphics 620 ROM: 8GB DDR4 2400MHz 硬盘: 128G SSD | 12.8 x 12.8 x 3.8 cm | / |
| 路由器 | 华硕RT-AX86U Wireless-AX5700 | / | / |
| ST-LINK下载器 | / | / | / |
| TTL转USB | / | / | / |
| WIFI配置底板及电源 | / | / | / |
| 小车电源适配器 | / | / | / |
| 小车充电线 | 一拖三Type-C接口 | / | / |
场地搭建
本教程将会引导读者如何搭建 KKSWARM 项目所需要的真实物理环境
前期准备
搭建实验环境需要用到以下物品
- 龙门支架
- 卷尺
- 海康威视相机+摄像头+海康威视相机数据线
- 相机固定支架
- 地毯
- 4m x 4m x 3m 的实验场地
开始搭建
- 将地毯平铺在 4m x 4m 的实验场地中。备注(地毯的尺寸为 2.2m x 2.2m)
提示
推荐4m x 4m 的场地。实际场地不能少于3.5m x 3.5m,因为考虑到放计算机的桌子以及支架等物件
- 松开龙门架支架最下方的旋钮,同时将三脚架打开,用手扶住主杆。用力向下压。让三脚架的三个脚架和主杆同时着地。此时固定最下方旋钮。 如下图所示

图1 固定三角支架
- 同理,固定好另一个支架
- 将龙门支架三脚架的一个脚 对准地毯侧边的十字架中心,延申大概约20cm。如下图所示:

图2 三角支架位置
- 同理,将另一个支架也放置在相应位置处
- 将龙门架的四根横杆依次连接。并固定在龙门支架上
提示
由于横杆较长,建议两个人一起进行固定和安装。
警告
安装横杆请注意安全
- 相机支架分为AB面,其中A面用于连接横杆,B面用于连接相机。
- 将相机按照图示方向与B面连接。

图3 安装相机
提示
原点的确定 
原点的确定
提示
为了保证镜头是尽可能垂直指向下方,将相机的顶部平面和连接支架的B面内部的边保持一致即可,如下图所示:

安装相机
- A面固定在横杆的中央位置
提示
在用户收到物品的时候,横杆处会有固定A面的标志。届时将A面固定在标志处即可
- 将USB线用轧带或者绳子沿着横杆固定。
提示
USB线沿着横杆固定的方向应该和迷你主机(操作台)放置的方向一致。注意:操作台至少高1m
- 依次升起龙门支架,并固定。
提示
- 龙门支架升起高度为:支架不能继续升起为止(最高)
- 建议两个人同步升起,保持一致性
视频演示
提示
如果无法播放视频,按下
ctrl+F5刷新一下缓存即可
场地标定
本教程将会引导读者如何标定 KKSWARM 项目所需要的真实物理环境
提示
光照标定
注意
由于海康威视相机并未开源底层代码。因此对于相机的参数只能通过其软件进行调节。但是使用其官方软件调节的时候,无法启动ROS驱动。故在光照调节上需要时间和耐心
-
将场地搭建好以后,将开迷你主机
-
启动海康威视软件。打开终端,输入命令:
cd /opt/MVS/bin ./MVS.sh -
调节参数如下图所示:
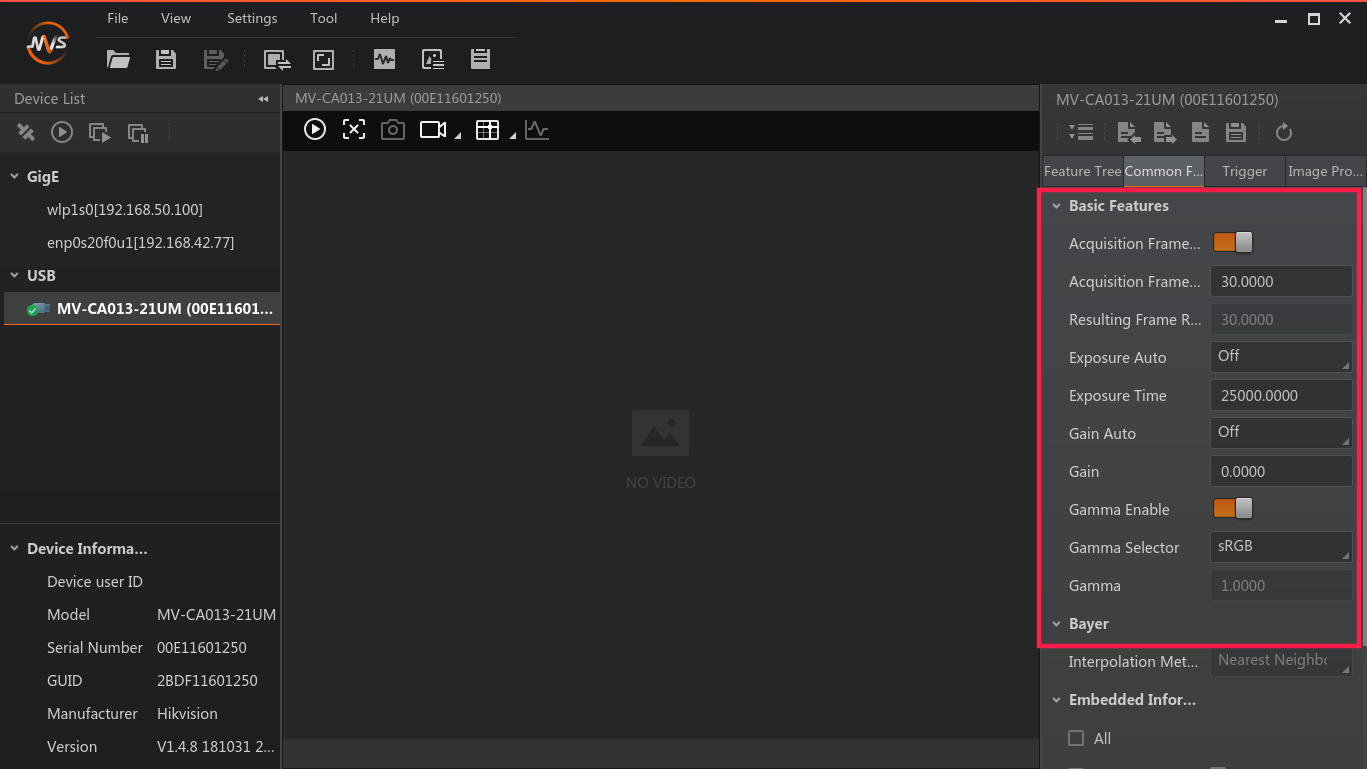
配置界面
将采样频率设置为30,伽马设置为sRGB。曝光时间根据实际的场地进行调整。
-
关闭该窗口。启动ROS相机驱动(记得启动 roscore)
rosrun camtoros camtoros -
启动直方图参考程序
rosrun camtoros hist_reference_generate.py
该程序将会在当前目录下生成一个直方图,如下图所示:
亮度直方图参考
- 此时可以将小车摆放在不同的位置,观察
rviz中是否能识别到其坐标变化。如果可以,表示标定成功。如果出现卡顿或者无法识别。请重复 2-5 步骤。
提示
- 上述直方图仅做一个参考
- 如果仍然无法标定,建议购买补光灯
位置标定
-
将场地搭建好以后,将迷你主机开机。
-
打开终端,输入命令,启动
roscore:roscore -
启动相机驱动。打开终端,输入命令:
rosrun camtoros camtoros -
启动二维码检测功能包。打开终端,输入命令:
roslaunch apriltag_ros continuous_detection.launch -
启动定位系统。打开终端,输入命令:
roslaunch global_vision start.launch -
启动rviz。打开终端,输入命令:
roscd camtoros/config rviz -d tf.rviz -
将相机的话题选择为
/reference_rectangle/image_raw,即可看到画面中有一个绿色的参考框出现。 -
由于在 场地搭建 中,仅仅只是搭建了场地,但是没有进行标定。因此,此时需要根据程序,调节摄像机的高度和方向,让参考框和地毯的白线对齐。如下图所示:
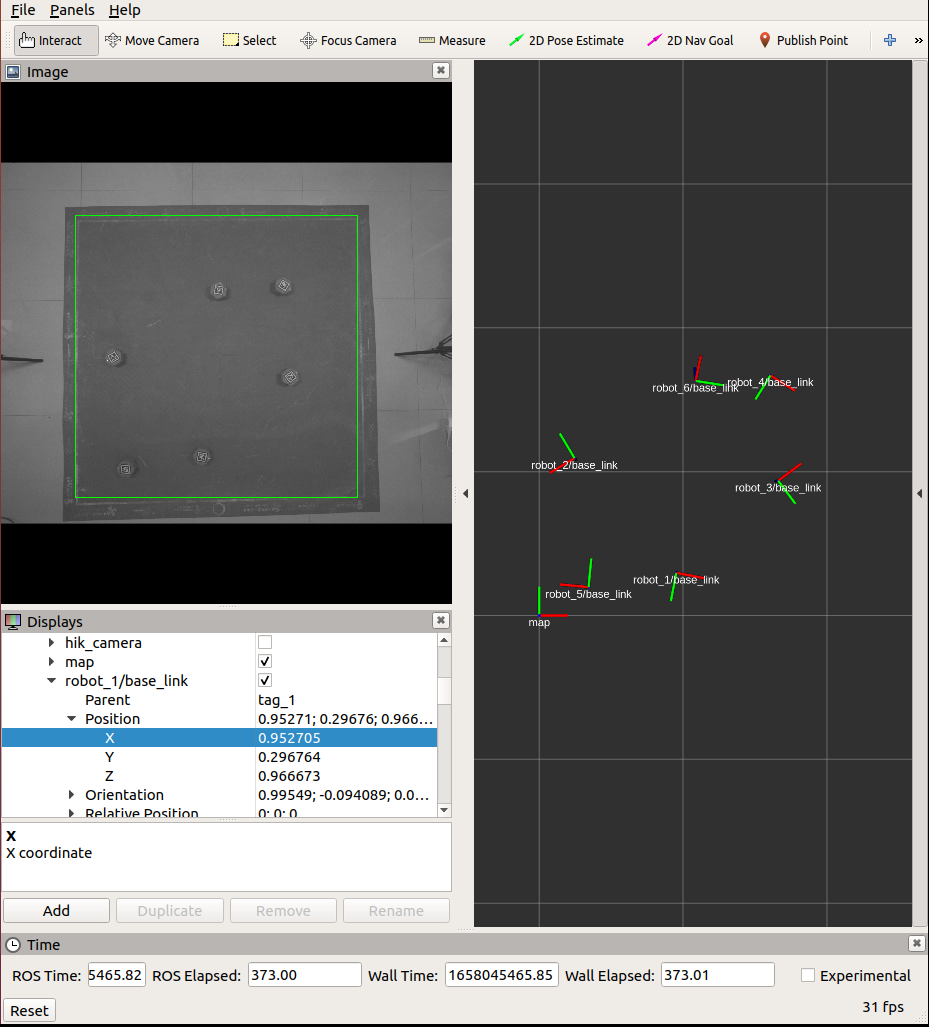
图3 场地标定界面
注意
该步骤需要两个人配合完成
警告
调节相机的时候,需要梯子或桌子垫高。请务必注意安全,防止跌伤!
-
当参考框对齐以后,将任意一辆小车(以1号车为例),放置在原点位置。(原点位置确定见场地搭建),此时输入命令
rostopic echo /robot_1/pose或 查看rviz里面,robot_1/base_link标签下的Postion中的xy值,看看小车的坐标是否在原点附近。如果不在,打开代码:src/apriltag_ros/apriltag_ros/src/common_functions.cpp第549行,进行误差的修正:averagePoint.x / 355 - 2.9, averagePoint.y / 355 - 2.7, tvec.at<double>(2);
通过修改第 549 行的 355 ± x,来修正原点位置。
注意
每次修改完以后,需要进行编译,然后重启
roslaunch global_vision start.launch命令
功能演示综述
以下内容为KKSWARM提供的功能演示,用户可以根据需要,选择功能进行复现。
- Demo前期准备
- 单车航点跟随
- 单车心形跟随
- 单车边界回弹
- 单车pure_pursuit功能演示(C++)
- 多车pure_pursuit功能演示(C++)
- 多车航点跟随(避障)
- 贪吃蛇
- 队形变换
- 多车跟随(强化学习)
功能演示前期准备
本教程将会引导读者完成功能复现的前期准备工作,以确保功能的顺利运行。
环境准备
-
确保已经成功安装 软件环境。如果您是购买过本产品的读者,可以忽略此步骤。
-
确保已经成功 搭建场地
-
确保已经成功 校准相机
-
确保已经成功 设置路由器。如果您是购买过本产品的读者,可以忽略此步骤。
-
根据实际环境情况,设置好海康威视相机的参数。由于场地的不同(主要是 光照)。在进行二次开发或者复现功能的时候, 可能会存在失败的情况,例如:无法识别到二维码。
注意
此步骤仅需设置一次,但是如果更改了环境(特别是 光照前后变化明显 ),例如:同一间场地,同样的灯光,在白天和晚上的光照是不一样的。但是需要重新设置以满足新环境
调整相机参数步骤如下:
- 打开终端,输入以下命令
cd /opt/MVS/bin
./MVS.sh
此时将会启动海康威视的操作界面,如图1所示:
图1 海康威视相机界面
- 可以看到当前连接的设备是
USB方式,以及相机型号为MV-CA013-21UM。将鼠标放置在相机型号上,将会出现一个 连接 的符号,点击连接。然后在中间的区域的菜单上点击 采集 按钮。如图2所示:
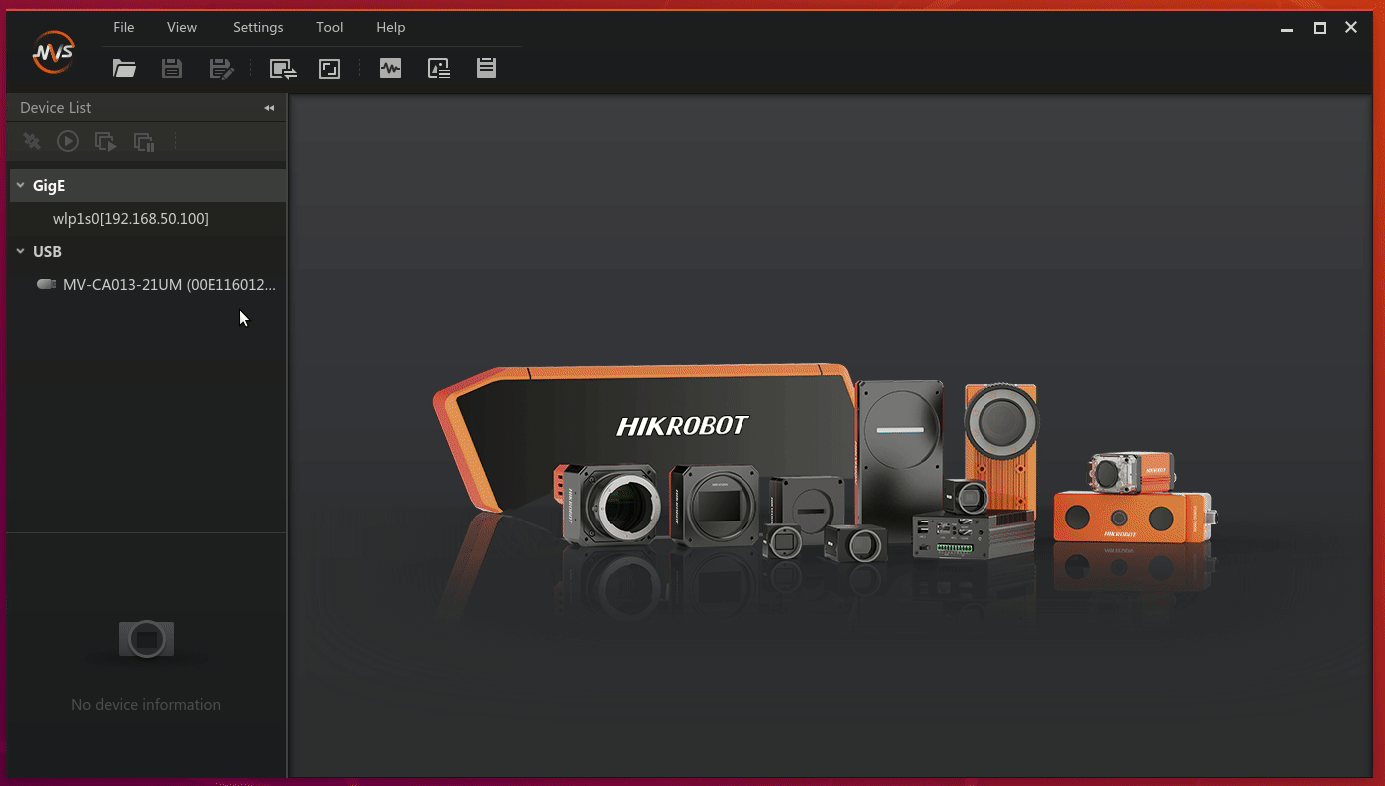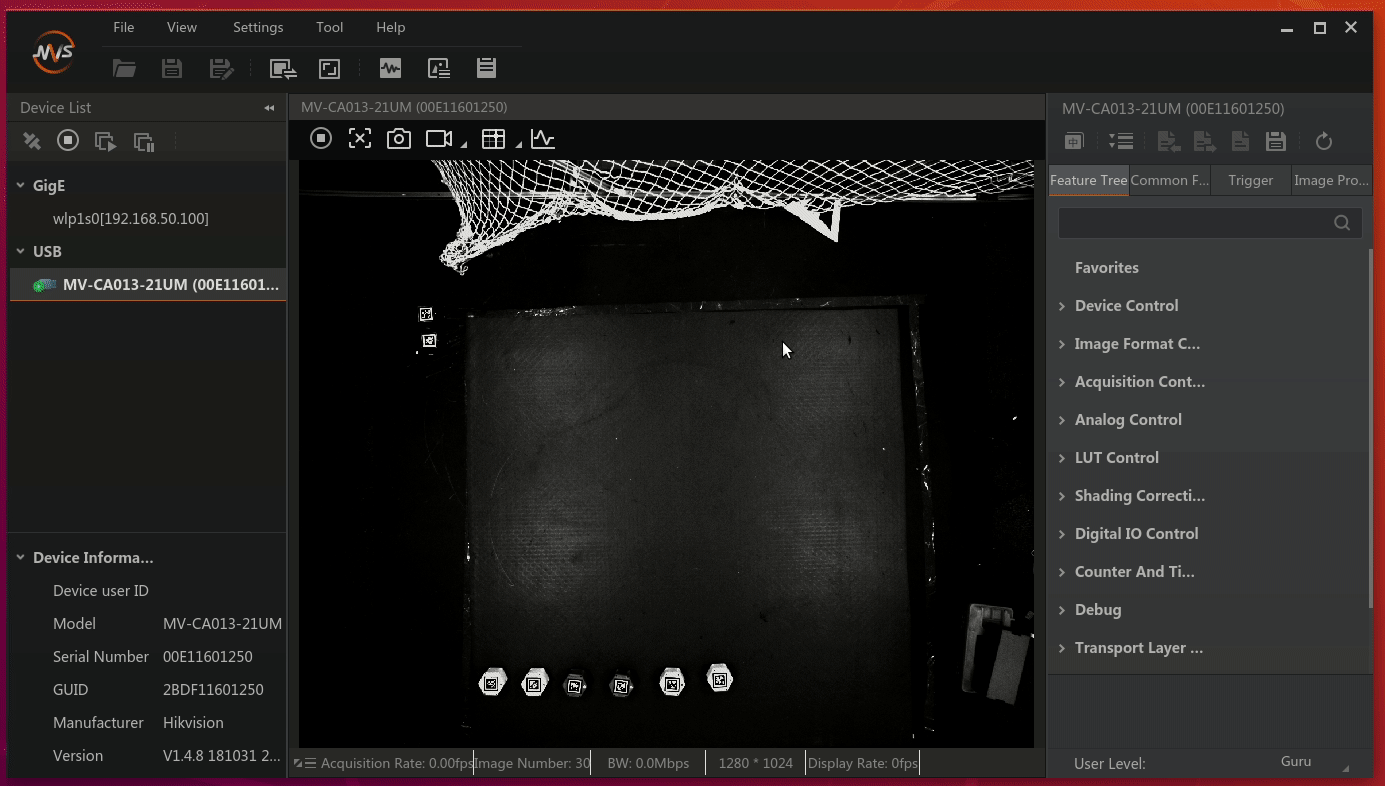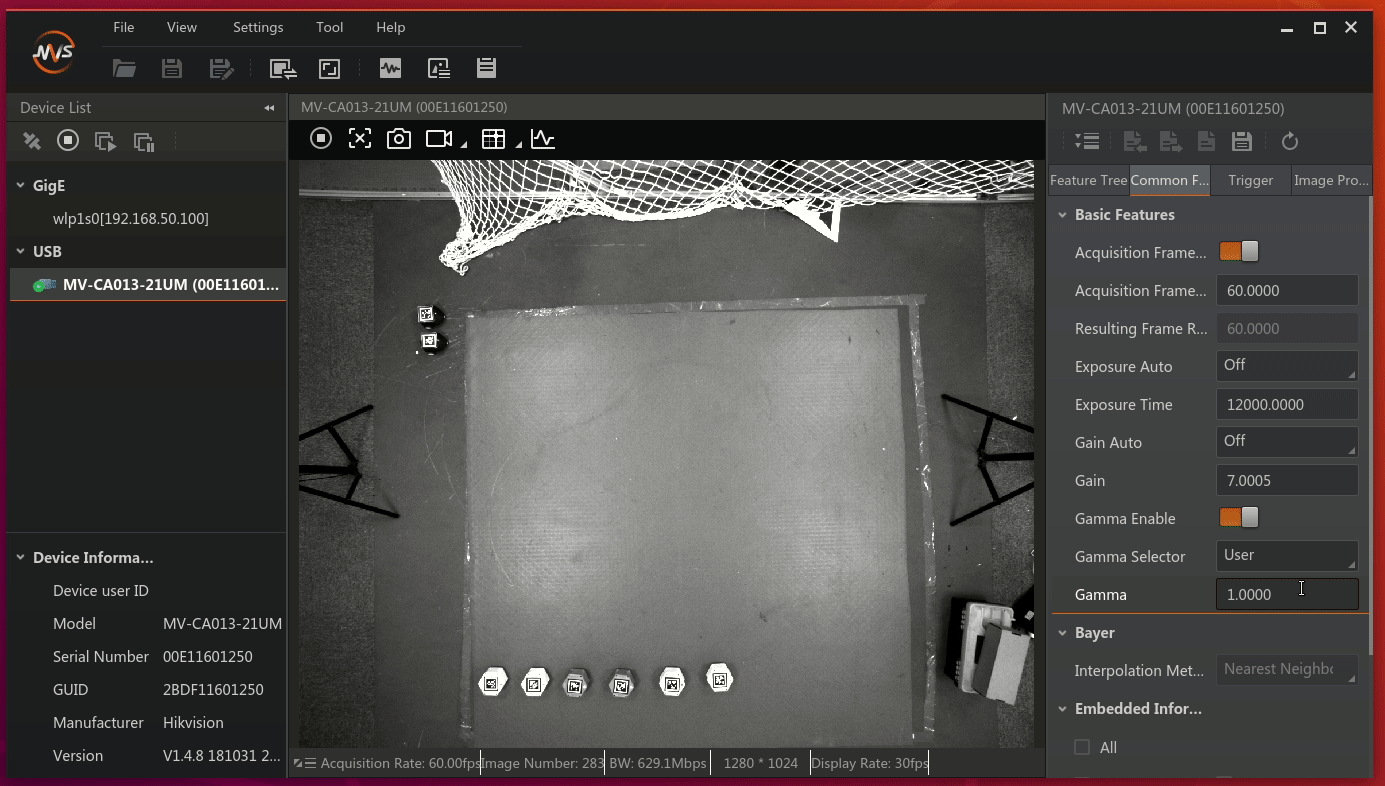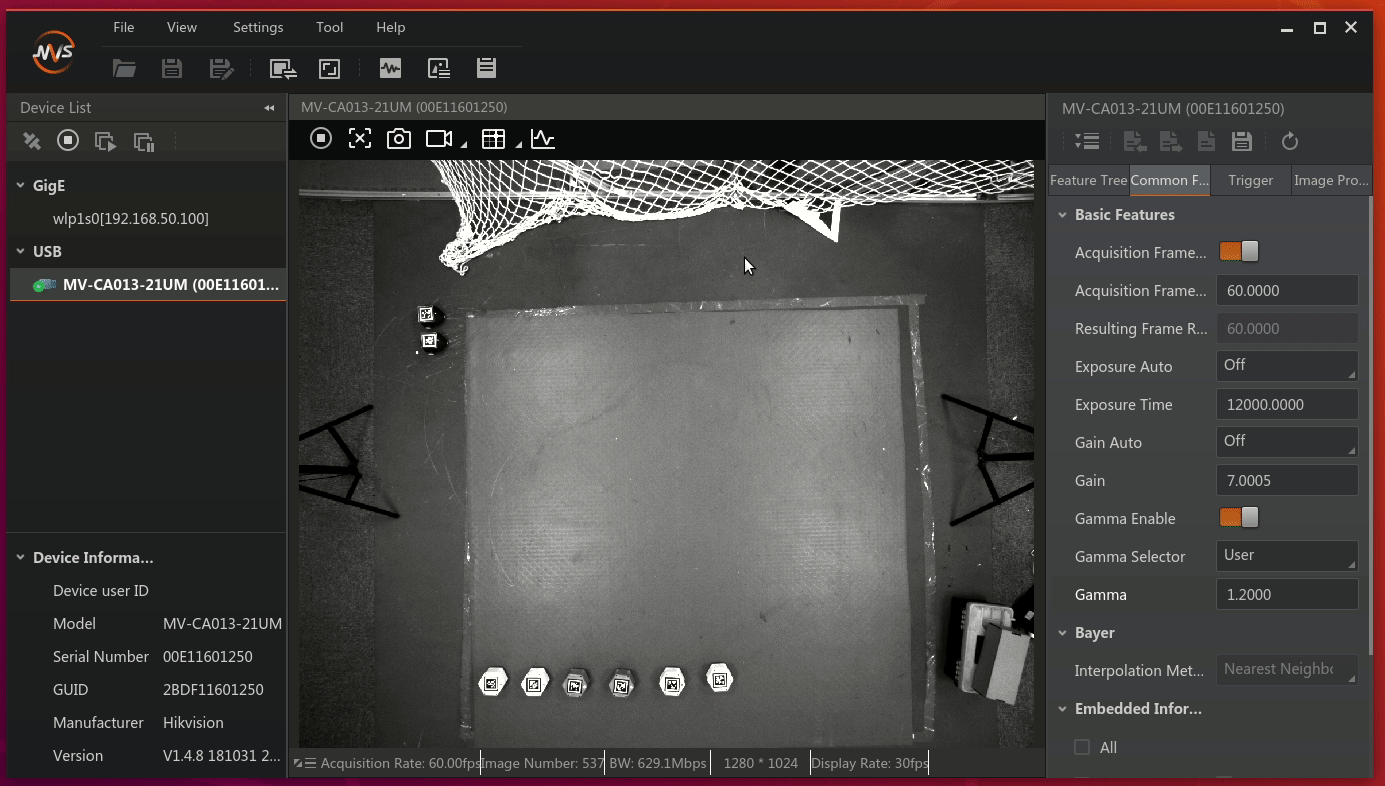
图2 连接相机
- 点击右边界面菜单栏上的
Common字样,进入相机的详细配置。如图3所示:
图3 配置界面
将采样频率设置为30,伽马设置为sRGB。曝光时间根据实际的场地进行调整。
等参数,让图像采集区域采集的图像的 对比度 明显。这个需要根据具体的场地光照去调节参数。
当调节好以后,启动场地光照直方图程序,并按照 场地标定 内容进行处理。
当调节好相机参数以后,可以打开rviz,启动定位系统,用键盘控制小车在场地移动,观察是否都能识别。具体步骤如下:
- 启动 roscore
roscore
- 启动相机界节点
注意
启动前,务必关闭海康威视自带的相机界面。否则将会产生冲突
rosrun camtoros camtoros
- 启动通信节点
rosrun tcp_communication tcpDriverNode
- 启动定位系统
roslaunch apriltag_ros continuous_detection.launch
roslaunch global_vision start.launch
- 打开rviz
roscd camtoros/config
rviz -d tf.rviz
- 启动键盘控制节点
python2 ~/kk-robot-swarm/swarm_control.py
控制小车在场地中移动。观察rviz中是否出现坐标系断连或者卡顿的情况
单车航点跟随功能演示
本教程将会引导读者完成 单车航点跟随功能 的演示。在使用此功能之前,确保已经完成了 Demo前期准备工作
提示
启动此Demo前,请关闭所有终端
- 打开终端,输入命令,启动
roscore:
roscore
- 启动相机驱动。打开终端,输入命令:
rosrun camtoros camtoros
- 启动二维码检测功能包。打开终端,输入命令:
roslaunch apriltag_ros continuous_detection.launch
- 将1号小车开机,放置在场地靠近原点处。如图1所示:
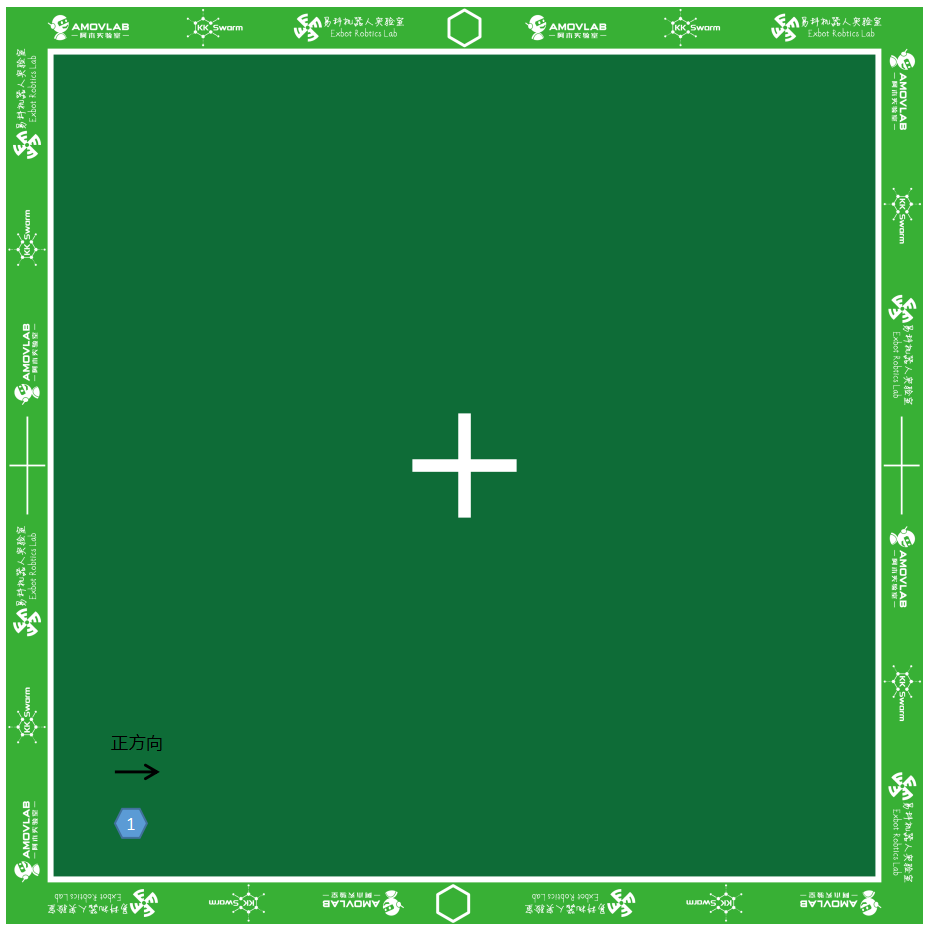
图1 小车位置摆放
注意
- 小车 开关方向 为小车正方向
- 图示位置 左下角 为原点,右边为
x轴正方向,上边为y轴正方向
- 启动通信节点。打开终端,输入命令:
rosrun tcp_communication tcpDriverNode
提示
小车连接需要大概3-5s时间
图2 连接成功界面
提示
你也可以双击打开
kk-robot-swarm/kkSwarm state.AppImage小车状态监视软件,查看小车连接情况。如下图所示:
小车状态检测
注意
connfd为文件描述符,由系统随机分配。以实际使用为准
- 启动定位系统节点。
打开
kk-robot-swarm/src/global_vision/launch/start.launch文件, 将 car_total_num 与 car_num 改为 1,如下所示:
最后启动定位系统。打开终端,输入命令:<launch> <node pkg="global_vision" type="odometryPub" respawn="false" name="odometryPub" output="screen"> <param name="car_total_num" value="1" /> </node> <node pkg="global_vision" type="static_tf" respawn="false" name="static_tf" output="screen"> <param name="car_num" value="1" /> </node> <!-- tf publisher --> <!-- matrix (1, 0, 0, 0, -1, 0, 0, 0, -1) --> <node pkg="tf" type="static_transform_publisher" name="map_hik_broadcaster" args="0 2 4 1 0 0 0 map hik_camera 100" /> </launch>
roslaunch global_vision start.launch
- 启动单车航点功能。打开终端,输入命令:
rosrun c1_waypoint c1_waypoint
- 停车。首先 关闭第7步 的程序,然后打开终端,输入:
rosrun global_vision stop
视频演示
提示
如果无法播放视频,按下
ctrl+F5刷新一下缓存即可
心形跟随功能演示
本教程将会引导读者完成 心形跟随功能 的演示。在使用此功能之前,确保已经完成了 Demo前期准备工作
提示
启动此Demo前,请关闭所有终端
- 打开终端,输入命令,启动
roscore:
roscore
- 启动相机驱动。打开终端,输入命令:
rosrun camtoros camtoros
- 启动二维码检测功能包。打开终端,输入命令:
roslaunch apriltag_ros continuous_detection.launch
- 将1号小车开机,放置在场地靠近原点处。如图1所示:
图1 小车位置摆放
注意
- 小车 开关方向 为小车正方向
- 图示位置 左下角 为原点,右边为
x轴正方向,上边为y轴正方向
- 启动通信节点。打开终端,输入命令:
rosrun tcp_communication tcpDriverNode
提示
小车连接需要大概3-5s时间
图2 连接成功界面
提示
你也可以双击打开
kk-robot-swarm/kkSwarm state.AppImage小车状态监视软件,查看小车连接情况。如下图所示:小车状态检测
注意
connfd为文件描述符,由系统随机分配。以实际使用为准
- 启动定位系统节点。
打开
kk-robot-swarm/src/global_vision/launch/start.launch文件, 将 car_total_num 与 car_num 改为 1,如下所示:
最后启动定位系统。打开终端,输入命令:<launch> <node pkg="global_vision" type="odometryPub" respawn="false" name="odometryPub" output="screen"> <param name="car_total_num" value="1" /> </node> <node pkg="global_vision" type="static_tf" respawn="false" name="static_tf" output="screen"> <param name="car_num" value="1" /> </node> <!-- tf publisher --> <!-- matrix (1, 0, 0, 0, -1, 0, 0, 0, -1) --> <node pkg="tf" type="static_transform_publisher" name="map_hik_broadcaster" args="0 2 4 1 0 0 0 map hik_camera 100" /> </launch>
roslaunch global_vision start.launch
- 启动心形跟踪功能。打开终端,输入命令:
rosrun c1_pp_s_heart c1_pp_s_heart
- 停车。首先 关闭第7步 的程序,然后打开终端,输入:
rosrun global_vision stop
视频演示
提示
如果无法播放视频,按下
ctrl+F5刷新一下缓存即可
单车边界回弹功能演示
本教程将会引导读者完成 单车边界回弹功能 的演示。在使用此功能之前,确保已经完成了 Demo前期准备工作
提示
启动此Demo前,请关闭所有终端
- 打开终端,输入命令,启动
roscore:
roscore
- 启动相机驱动。打开终端,输入命令:
rosrun camtoros camtoros
- 启动二维码检测功能包。打开终端,输入命令:
roslaunch apriltag_ros continuous_detection.launch
-
将1号小车开机,放置在场地中央附近位置
-
启动通信节点。打开终端,输入命令:
rosrun tcp_communication tcpDriverNode
等待小车链接成功,如图所示:
提示
小车连接需要大概3-5s时间
图1 连接成功界面
提示
你也可以双击打开
kk-robot-swarm/kkSwarm state.AppImage小车状态监视软件,查看小车连接情况。如下图所示:小车状态检测
注意
connfd为文件描述符,由系统随机分配。以实际使用为准
- 启动定位系统节点。
打开
kk-robot-swarm/src/global_vision/launch/start.launch文件, 将 car_total_num 与 car_num 改为 1,如下所示:
最后启动定位系统。打开终端,输入命令:<launch> <node pkg="global_vision" type="odometryPub" respawn="false" name="odometryPub" output="screen"> <param name="car_total_num" value="1" /> </node> <node pkg="global_vision" type="static_tf" respawn="false" name="static_tf" output="screen"> <param name="car_num" value="1" /> </node> <!-- tf publisher --> <!-- matrix (1, 0, 0, 0, -1, 0, 0, 0, -1) --> <node pkg="tf" type="static_transform_publisher" name="map_hik_broadcaster" args="0 2 4 1 0 0 0 map hik_camera 100" /> </launch>
roslaunch global_vision start.launch
- 启动单车边界回弹功能。打开终端,输入命令:
rosrun c1_soft_border0516 c1_soft_border0516
- 停车
rosrun global_vision stop
视频演示
提示
如果无法播放视频,按下
ctrl+F5刷新一下缓存即可
单车pure_pursuit功能演示(C++)演示
本教程将会引导读者完成 单车pure_pursuit功能演示(C++) 的演示。在使用此功能之前,确保已经完成了 Demo前期准备工作
提示
启动此Demo前,请关闭所有终端
- 打开终端,输入命令,启动
roscore:
roscore
- 启动相机驱动。打开终端,输入命令:
rosrun camtoros camtoros
- 启动二维码检测功能包。打开终端,输入命令:
roslaunch apriltag_ros continuous_detection.launch
- 将1号小车开机,放置在场地的任意位置
提示
小车连接需要大概3-5s时间
- 启动通信节点。打开终端,输入命令:
rosrun tcp_communication tcpDriverNode
图1 连接成功界面
提示
你也可以双击打开
kk-robot-swarm/kkSwarm state.AppImage小车状态监视软件,查看小车连接情况。如下图所示:小车状态检测
注意
connfd为文件描述符,由系统随机分配。以实际使用为准
- 启动定位系统节点。
打开
kk-robot-swarm/src/global_vision/launch/start.launch文件, 将 car_total_num 与 car_num 改为 1,如下所示:
最后启动定位系统。打开终端,输入命令:<launch> <node pkg="global_vision" type="odometryPub" respawn="false" name="odometryPub" output="screen"> <param name="car_total_num" value="1" /> </node> <node pkg="global_vision" type="static_tf" respawn="false" name="static_tf" output="screen"> <param name="car_num" value="1" /> </node> <!-- tf publisher --> <!-- matrix (1, 0, 0, 0, -1, 0, 0, 0, -1) --> <node pkg="tf" type="static_transform_publisher" name="map_hik_broadcaster" args="0 2 4 1 0 0 0 map hik_camera 100" /> </launch>
roslaunch global_vision start.launch
- 打开 rviz。打开终端,输入命令:
roscd camtoros/config
rviz -d tf.rviz
-
在rviz中加载航点。 首先打开
kk-robot-swarm/src/swarm/waypoint_loader/launch/waypoint_loader.launch文件。保留1号车的路径,其余均注释。如下所示:<?xml version="1.0"?> <launch> <node pkg="waypoint_loader" type="waypoint_loader.py" name="waypoint_loader_1" output="screen"> <param name="path" value="$(find waypoint_loader)/waypoints/five_star.csv" /> <param name="velocity" value="0.2" /> <remap from="/path" to="/robot_1/path" /> </node> <!-- <node pkg="waypoint_loader" type="waypoint_loader.py" name="waypoint_loader_2" output="screen"> <param name="path" value="$(find waypoint_loader)/waypoints/robot_2.csv" /> <param name="velocity" value="0.2" /> <remap from="/path" to="/robot_2/path" /> </node> <node pkg="waypoint_loader" type="waypoint_loader.py" name="waypoint_loader_3" output="screen"> <param name="path" value="$(find waypoint_loader)/waypoints/five_star.csv" /> <param name="velocity" value="0.2" /> <remap from="/path" to="/robot_3/path" /> </node> --> </launch>然后打开
kk-robot-swarm/src/swarm/waypoint_loader/waypoints/文件夹。在该文件夹下可以看到预定义的航点信息。最后打开终端,输入命令:
roslaunch waypoint_loader waypoint_loader.launch
-
启动pure_pursuit功能包。 打开
kk-robot-swarm/src/swarm/pursuit/launch/pure_pursuit.launch文件,将2号和3号车相关注释。如下所示:<launch> <arg name="name_1" default="robot_1"/> <!-- <arg name="name_2" default="robot_2"/> <arg name="name_3" default="robot_3"/> --> <!-- Pure pursuit path tracking --> <node pkg="pure_pursuit" type="pure_pursuit" name="controller_1" output="screen"> <rosparam file="$(find pure_pursuit)/config/$(arg name_1).yaml" command="load"/> <remap from="path_segment" to="$(arg name_1)/path"/> <remap from="odometry" to="$(arg name_1)/pose"/> <remap from="cmd_vel" to="$(arg name_1)/cmd_vel"/> </node> <!-- add more params and nodes--> <!-- <node pkg="pure_pursuit" type="pure_pursuit" name="controller_2" output="screen"> <rosparam file="$(find pure_pursuit)/config/$(arg name_2).yaml" command="load"/> <remap from="path_segment" to="$(arg name_2)/path"/> <remap from="odometry" to="$(arg name_2)/pose"/> <remap from="cmd_vel" to="$(arg name_2)/cmd_vel"/> </node> <node pkg="pure_pursuit" type="pure_pursuit" name="controller_3" output="screen"> <rosparam file="$(find pure_pursuit)/config/$(arg name_3).yaml" command="load"/> <remap from="path_segment" to="$(arg name_3)/path"/> <remap from="odometry" to="$(arg name_3)/pose"/> <remap from="cmd_vel" to="$(arg name_3)/cmd_vel"/> </node> --> </launch>打开终端,输入命令:
roslaunch pure_pursuit pure_pursuit.launch
- 停车。首先 关闭第9步 的程序,然后打开终端,输入:
rosrun global_vision stop
视频演示
提示
如果无法播放视频,按下
ctrl+F5刷新一下缓存即可
多车pure_pursuit功能演示(C++)演示
本教程将会引导读者完成 多车pure_pursuit功能演示(C++) 的演示。在使用此功能之前,确保已经完成了 Demo前期准备工作
提示
启动此Demo前,请关闭所有终端
- 打开终端,输入命令,启动
roscore:
roscore
- 启动相机驱动。打开终端,输入命令:
rosrun camtoros camtoros
- 启动二维码检测功能包。打开终端,输入命令:
roslaunch apriltag_ros continuous_detection.launch
- 将1,2,3号小车开机,放置位置如图1所示:
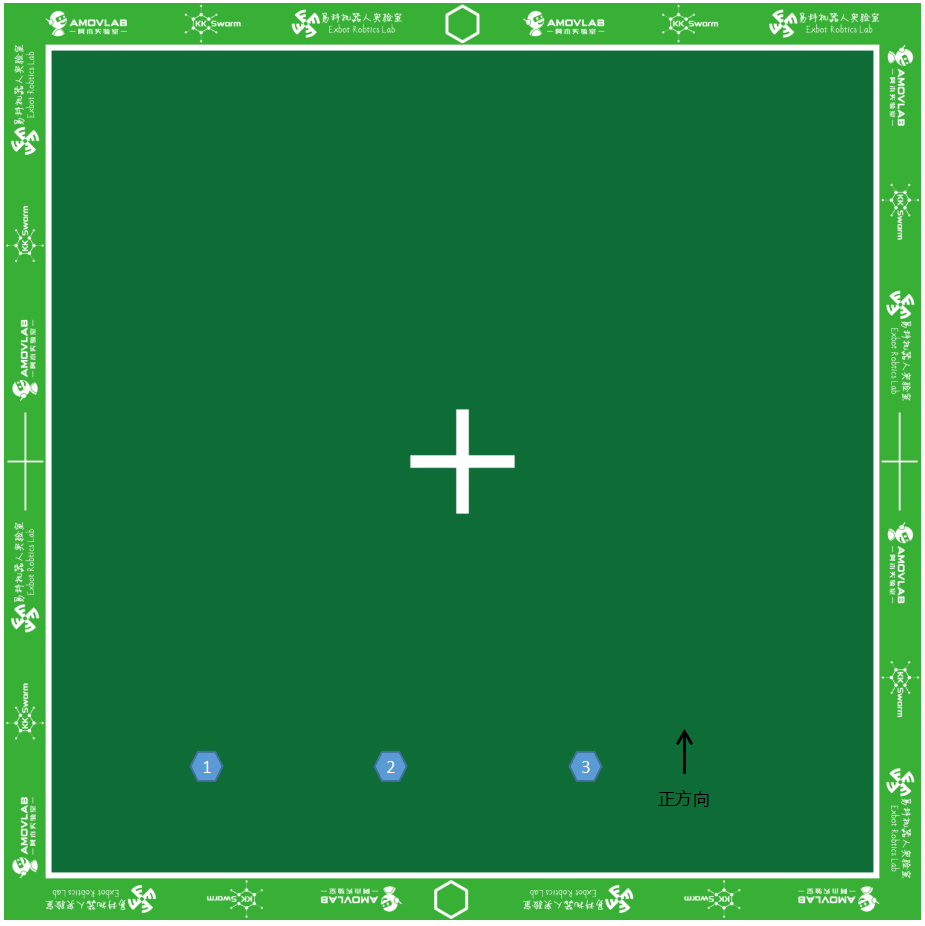
图1 小车位置摆放
注意
- 小车 开关方向 为小车正方向
- 图示位置 左下角 为原点,右边为
x轴正方向,上边为y轴正方向- 摆放的时候小车左右间距尽量大一点, 太近可能会导致刚启动的时候发生碰撞
提示
小车的摆放位置取决于航点的定义,注意不要让航点产生交叉。此Demo集群小车不具备避障功能
- 启动通信节点。打开终端,输入命令:
rosrun tcp_communication tcpDriverNode
- 启动定位系统节点。
打开
kk-robot-swarm/src/global_vision/launch/start.launch文件, 将 car_total_num 与 car_num 改为 3,如下所示:
最后启动定位系统。打开终端,输入命令:<launch> <node pkg="global_vision" type="odometryPub" respawn="false" name="odometryPub" output="screen"> <param name="car_total_num" value="3" /> </node> <node pkg="global_vision" type="static_tf" respawn="false" name="static_tf" output="screen"> <param name="car_num" value="3" /> </node> <!-- tf publisher --> <!-- matrix (1, 0, 0, 0, -1, 0, 0, 0, -1) --> <node pkg="tf" type="static_transform_publisher" name="map_hik_broadcaster" args="0 2 4 1 0 0 0 map hik_camera 100" /> </launch>
roslaunch global_vision start.launch
- 打开 rviz。打开终端,输入命令:
roscd camtoros/config
rviz -d tf.rviz
-
在rviz中加载航点。 首先打开
kk-robot-swarm/src/swarm/waypoint_loader/launch/waypoint_loader.launch文件。如下所示:<?xml version="1.0"?> <launch> <node pkg="waypoint_loader" type="waypoint_loader.py" name="waypoint_loader_1" output="screen"> <param name="path" value="$(find waypoint_loader)/waypoints/robot_1.csv" /> <param name="velocity" value="0.2" /> <remap from="/path" to="/robot_1/path" /> </node> <node pkg="waypoint_loader" type="waypoint_loader.py" name="waypoint_loader_2" output="screen"> <param name="path" value="$(find waypoint_loader)/waypoints/robot_2.csv" /> <param name="velocity" value="0.2" /> <remap from="/path" to="/robot_2/path" /> </node> <node pkg="waypoint_loader" type="waypoint_loader.py" name="waypoint_loader_3" output="screen"> <param name="path" value="$(find waypoint_loader)/waypoints/robot_3.csv" /> <param name="velocity" value="0.2" /> <remap from="/path" to="/robot_3/path" /> </node> </launch>然后打开
kk-robot-swarm/src/swarm/waypoint_loader/waypoints/文件夹。在该文件夹下可以看到预定义的航点信息。最后打开终端,输入命令:
roslaunch waypoint_loader waypoint_loader.launch
-
修改航路点文件(以
robot_1.csv为例)打开
kk-robot-swarm/src/swarm/waypoint_loader/waypoints/robot_1.csv文件内容如下:0.2,0.2,0.1 0.4,0.6,0.1 0.2,1.2,0.1每一行代表一个航点的
(x,y)坐标,第三列代表航向。(暂时用不到) -
启动pure_pursuit功能包。 打开
kk-robot-swarm/src/swarm/pursuit/launch/pure_pursuit.launch文件,如下所示:<launch> <arg name="name_1" default="robot_1"/> <arg name="name_2" default="robot_2"/> <arg name="name_3" default="robot_3"/> <!-- Pure pursuit path tracking --> <node pkg="pure_pursuit" type="pure_pursuit" name="controller_1" output="screen"> <rosparam file="$(find pure_pursuit)/config/$(arg name_1).yaml" command="load"/> <remap from="path_segment" to="$(arg name_1)/path"/> <remap from="odometry" to="$(arg name_1)/pose"/> <remap from="cmd_vel" to="$(arg name_1)/cmd_vel"/> </node> <!-- add more params and nodes--> <node pkg="pure_pursuit" type="pure_pursuit" name="controller_2" output="screen"> <rosparam file="$(find pure_pursuit)/config/$(arg name_2).yaml" command="load"/> <remap from="path_segment" to="$(arg name_2)/path"/> <remap from="odometry" to="$(arg name_2)/pose"/> <remap from="cmd_vel" to="$(arg name_2)/cmd_vel"/> </node> <node pkg="pure_pursuit" type="pure_pursuit" name="controller_3" output="screen"> <rosparam file="$(find pure_pursuit)/config/$(arg name_3).yaml" command="load"/> <remap from="path_segment" to="$(arg name_3)/path"/> <remap from="odometry" to="$(arg name_3)/pose"/> <remap from="cmd_vel" to="$(arg name_3)/cmd_vel"/> </node> </launch>打开终端,输入命令:
roslaunch pure_pursuit pure_pursuit.launch
警告
此Demo不带有避障功能,如果路径发生交叉,小车将会发生碰撞
- 停车。首先 关闭第10步 的程序,然后打开终端,输入:
rosrun global_vision stop
视频演示
提示
如果无法播放视频,按下
ctrl+F5刷新一下缓存即可
多车航点跟随(避障)功能演示
本教程将会引导读者完成 多车航点跟随(避障) 的演示。在使用此功能之前,确保已经完成了 Demo前期准备工作
提示
启动此Demo前,请关闭所有终端
- 打开终端,输入命令,启动
roscore:
roscore
- 启动相机驱动。打开终端,输入命令:
rosrun camtoros camtoros
- 启动二维码检测功能包。打开终端,输入命令:
roslaunch apriltag_ros continuous_detection.launch
-
将1-6号小车开机,放置在场地的任意位置
-
启动通信节点。打开终端,输入命令:
rosrun tcp_communication tcpDriverNode
提示
小车连接需要大概10-15s时间
图2 连接成功界面
提示
你也可以双击打开
kk-robot-swarm/kkSwarm state.AppImage小车状态监视软件,查看小车连接情况。如下图所示:
小车状态检测
注意
connfd为文件描述符,由系统随机分配。以实际使用为准
- 启动定位系统节点。
打开
kk-robot-swarm/src/global_vision/launch/start.launch文件, 将 car_total_num 与 car_num 改为 6,如下所示:
最后启动定位系统。打开终端,输入命令:<launch> <node pkg="global_vision" type="odometryPub" respawn="false" name="odometryPub" output="screen"> <param name="car_total_num" value="6" /> </node> <node pkg="global_vision" type="static_tf" respawn="false" name="static_tf" output="screen"> <param name="car_num" value="6" /> </node> <!-- tf publisher --> <!-- matrix (1, 0, 0, 0, -1, 0, 0, 0, -1) --> <node pkg="tf" type="static_transform_publisher" name="map_hik_broadcaster" args="0 2 4 1 0 0 0 map hik_camera 100" /> </launch>
roslaunch global_vision start.launch
- 启动多车航点跟随(避障)功能。打开终端,输入命令:
rosrun c6_goto_target c6_goto_target
- 通过命令行改变目标点。打开终端,输入命令:
rostopic pub -r 10 /wp std_msgs/Float64 "data: 815426"
提示
有关小车位置定义,详见 二次开发参数
- 停车。首先 关闭第7步 的程序,然后打开终端,输入:
rosrun global_vision stop
视频演示
提示
如果无法播放视频,按下
ctrl+F5刷新一下缓存即可
贪吃蛇功能演示
本教程将会引导读者完成 贪吃蛇 的演示。在使用此功能之前,确保已经完成了 Demo前期准备工作
提示
启动此Demo前,请关闭所有终端
- 打开终端,输入命令,启动
roscore:
roscore
- 启动相机驱动。打开终端,输入命令:
rosrun camtoros camtoros
- 启动二维码检测功能包。打开终端,输入命令:
roslaunch apriltag_ros continuous_detection.launch
- 将1 - 6号小车开机,将 1号车放置在场地的原点附近,其余车辆依次摆放在场外 。如图1所示:
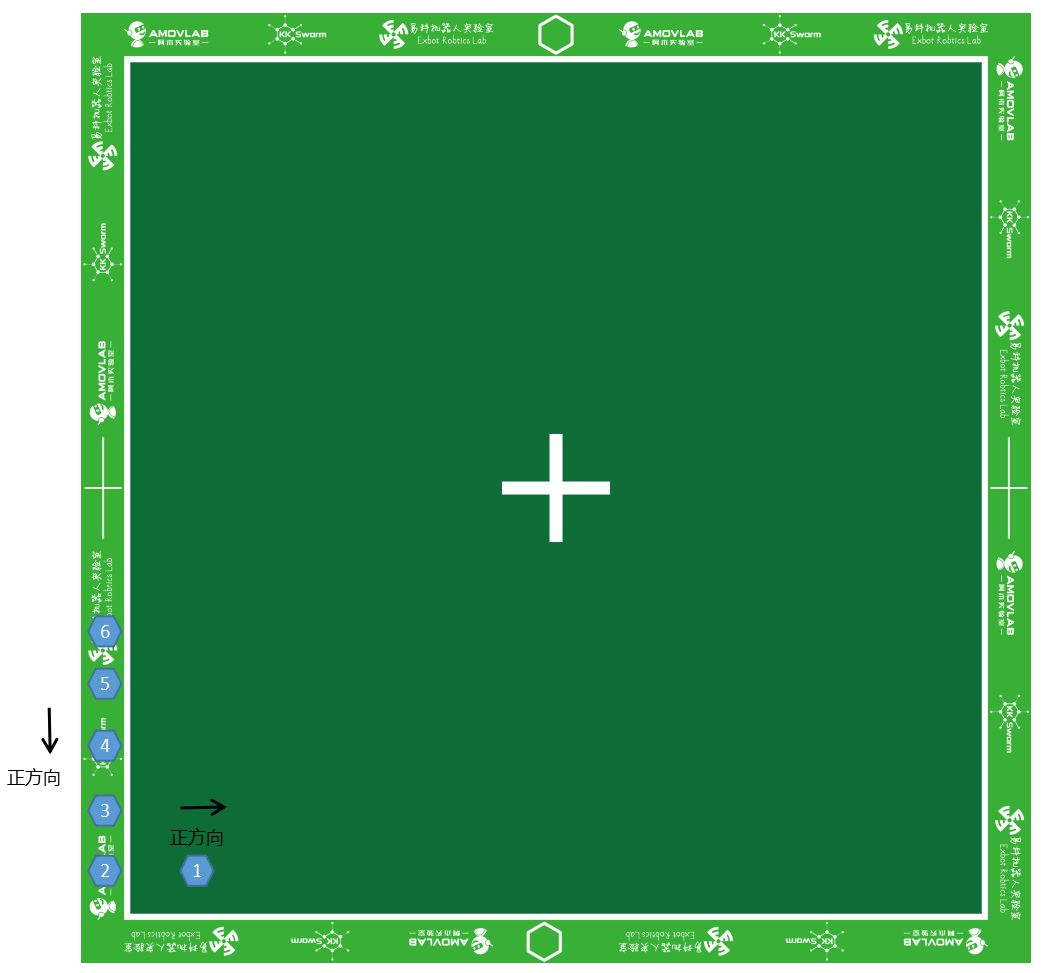
图2 小车摆放位置
注意
- 小车 开关方向 为小车正方向
- 图示位置 左下角 为原点,右边为
x轴正方向,上边为y轴正方向- 摆放的时候小车 2 - 5 号前后左右间距为
5cm左右, 太近可能会导致刚启动的时候发生碰撞- 1号车和2号车之间在水平方向 保持一致,但是间隔稍微宽一点,约
10cm
- 启动通信节点。打开终端,输入命令:
rosrun tcp_communication tcpDriverNode
提示
小车连接需要大概10-15s时间
图3 连接成功界面
提示
你也可以双击打开
kk-robot-swarm/kkSwarm state.AppImage小车状态监视软件,查看小车连接情况。如下图所示:小车状态检测
注意
connfd为文件描述符,由系统随机分配。以实际使用为准
- 启动定位系统节点。
打开
kk-robot-swarm/src/global_vision/launch/start.launch文件, 将 car_total_num 与 car_num 改为 6,如下所示:
最后启动定位系统。打开终端,输入命令:<launch> <node pkg="global_vision" type="odometryPub" respawn="false" name="odometryPub" output="screen"> <param name="car_total_num" value="6" /> </node> <node pkg="global_vision" type="static_tf" respawn="false" name="static_tf" output="screen"> <param name="car_num" value="6" /> </node> <!-- tf publisher --> <!-- matrix (1, 0, 0, 0, -1, 0, 0, 0, -1) --> <node pkg="tf" type="static_transform_publisher" name="map_hik_broadcaster" args="0 2 4 1 0 0 0 map hik_camera 100" /> </launch>
roslaunch global_vision start.launch
- 启动贪吃蛇功能。打开终端,输入命令:
rosrun c10_wp_snake c10_wp_snake
- 停车。首先 关闭第7步 的程序,然后打开终端,输入:
rosrun global_vision stop
视频演示
提示
如果无法播放视频,按下
ctrl+F5刷新一下缓存即可
队形变换功能演示
本教程将会引导读者完成 队形变换 的演示。在使用此功能之前,确保已经完成了 Demo前期准备工作
提示
启动此Demo前,请关闭所有终端
- 打开终端,输入命令,启动
roscore:
roscore
- 启动相机驱动。打开终端,输入命令:
rosrun camtoros camtoros
- 启动二维码检测功能包。打开终端,输入命令:
roslaunch apriltag_ros continuous_detection.launch
- 将1 - 6号小车开机,放置在场地中央附近。如图1所示:
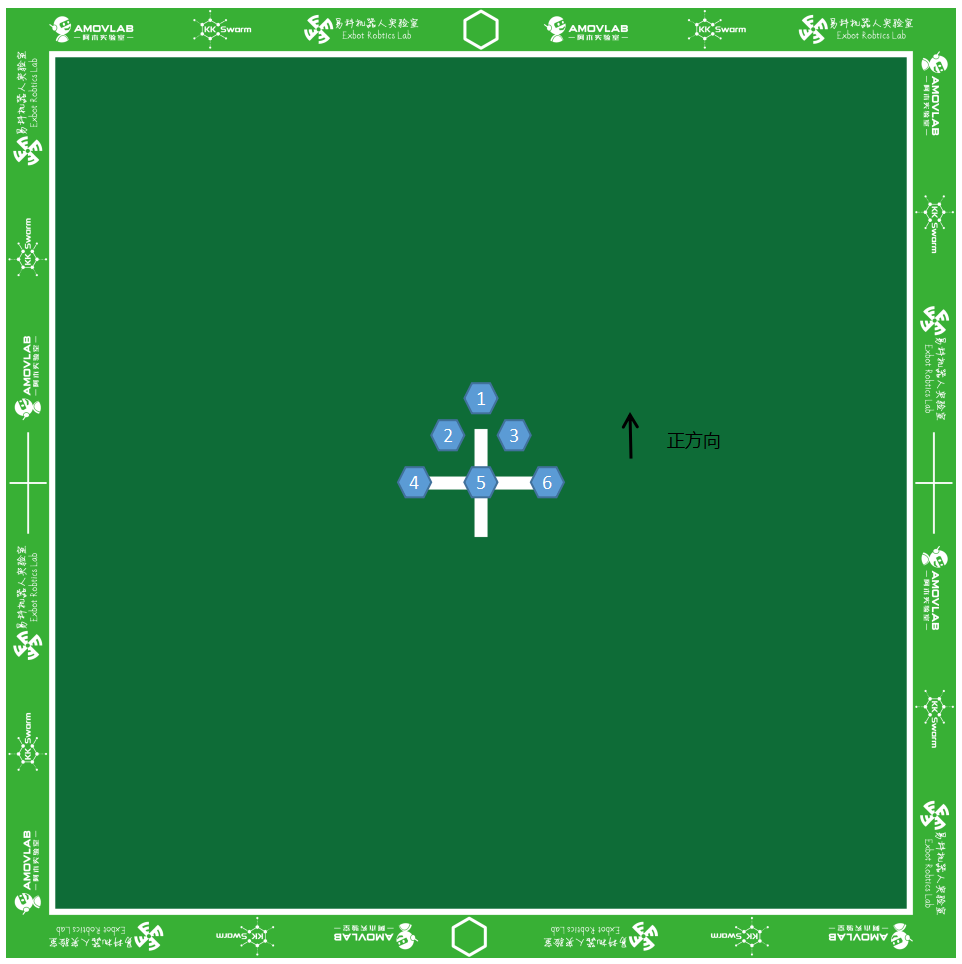
图2 连接成功界面
注意
- 小车 开关方向 为小车正方向
- 图示位置 左下角 为原点,右边为
x轴正方向,上边为y轴正方向- 摆放的时候小车前后左右间距为
5cm左右, 太近可能会导致刚启动的时候发生碰撞
- 启动通信节点。打开终端,输入命令:
rosrun tcp_communication tcpDriverNode
提示
小车连接需要大概10-15s时间
图2 连接成功界面
提示
你也可以双击打开
kk-robot-swarm/kkSwarm state.AppImage小车状态监视软件,查看小车连接情况。如下图所示:小车状态检测
注意
connfd为文件描述符,由系统随机分配。以实际使用为准
- 启动定位系统节点。
打开
kk-robot-swarm/src/global_vision/launch/start.launch文件, 将 car_total_num 与 car_num 改为 6,如下所示:
最后启动定位系统。打开终端,输入命令:<launch> <node pkg="global_vision" type="odometryPub" respawn="false" name="odometryPub" output="screen"> <param name="car_total_num" value="6" /> </node> <node pkg="global_vision" type="static_tf" respawn="false" name="static_tf" output="screen"> <param name="car_num" value="6" /> </node> <!-- tf publisher --> <!-- matrix (1, 0, 0, 0, -1, 0, 0, 0, -1) --> <node pkg="tf" type="static_transform_publisher" name="map_hik_broadcaster" args="0 2 4 1 0 0 0 map hik_camera 100" /> </launch>
roslaunch global_vision start.launch
- 启动队形变换航点功能。打开终端,输入命令:
rosrun c6_formation c6_formation
- 停车。首先 关闭第7步 的程序,然后打开终端,输入:
rosrun global_vision stop
视频演示
提示
如果无法播放视频,按下
ctrl+F5刷新一下缓存即可
多车跟随(强化学习)功能演示
本教程将会引导读者完成 多车跟随(强化学习) 的演示。在使用此功能之前,确保已经完成了 Demo前期准备工作
提示
启动此Demo前,请关闭所有终端
- 打开终端,输入命令,启动
roscore:
roscore
- 启动相机驱动。打开终端,输入命令:
rosrun camtoros camtoros
- 启动二维码检测功能包。打开终端,输入命令:
roslaunch apriltag_ros continuous_detection.launch
- 将1 - 6号小车开机,放置在场地中央附近。如图1所示:
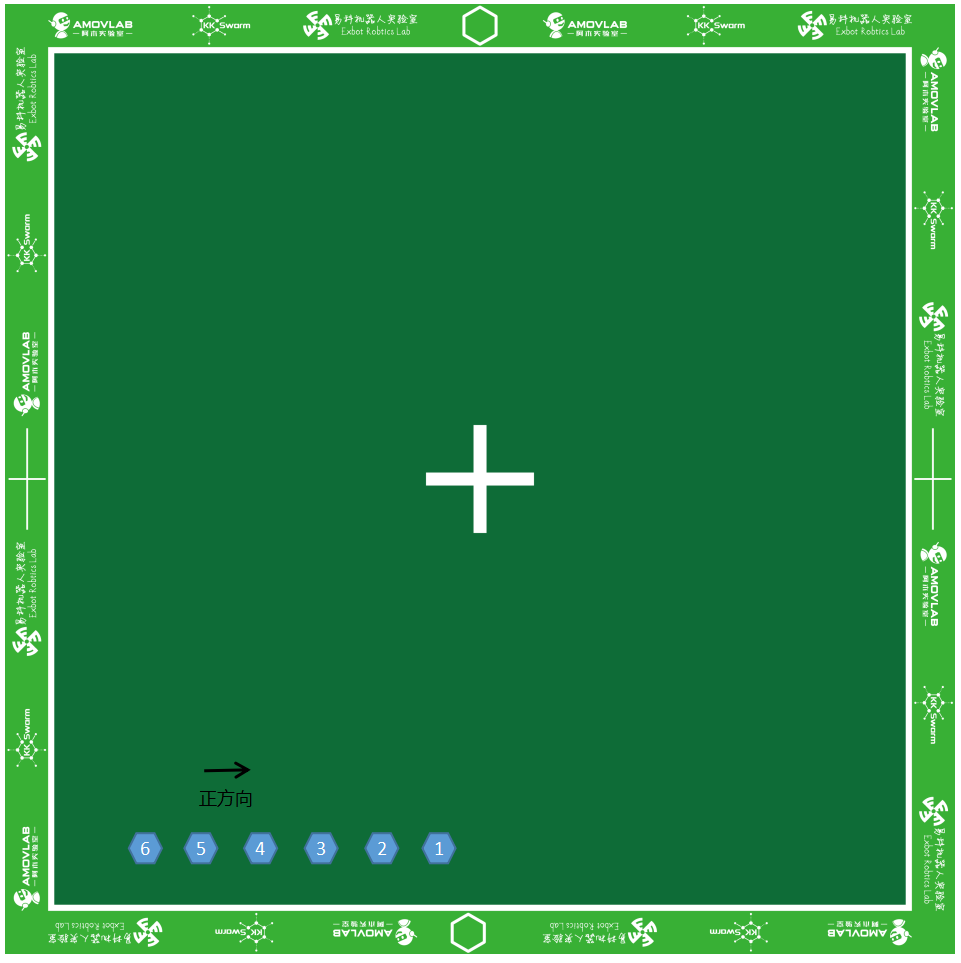
图2 连接成功界面
注意
- 小车 开关方向 为小车正方向
- 图示位置 左下角 为原点,右边为
x轴正方向,上边为y轴正方向- 摆放的时候小车前后左右间距为
5cm左右, 太近可能会导致刚启动的时候发生碰撞
- 启动通信节点。打开终端,输入命令:
rosrun tcp_communication tcpDriverNode
提示
小车连接需要大概10-15s时间
图2 连接成功界面
提示
你也可以双击打开
kk-robot-swarm/kkSwarm state.AppImage小车状态监视软件,查看小车连接情况。如下图所示:小车状态检测
注意
connfd为文件描述符,由系统随机分配。以实际使用为准
- 启动定位系统节点。
打开
kk-robot-swarm/src/global_vision/launch/start.launch文件, 将 car_total_num 与 car_num 改为 6,如下所示:
最后启动定位系统。打开终端,输入命令:<launch> <node pkg="global_vision" type="odometryPub" respawn="false" name="odometryPub" output="screen"> <param name="car_total_num" value="6" /> </node> <node pkg="global_vision" type="static_tf" respawn="false" name="static_tf" output="screen"> <param name="car_num" value="6" /> </node> <!-- tf publisher --> <!-- matrix (1, 0, 0, 0, -1, 0, 0, 0, -1) --> <node pkg="tf" type="static_transform_publisher" name="map_hik_broadcaster" args="0 2 4 1 0 0 0 map hik_camera 100" /> </launch>
roslaunch global_vision start.launch
- 启动强化学习多车跟随节点。打开终端,输入命令:
rosrun c6_pfc_rl c6_pfc_rl
提示
在运行过程中,由于车的数量较多,会产生甩尾现象。导致最后一辆车被甩出场地,这是正常现象。
将甩尾的车重新放置在场地内即可
- 停车。首先 关闭第7步 的程序,然后打开终端,输入:
rosrun global_vision stop
提示
强化学习跟车Demo支持2-6车,可以根据情况将6车变为4车。或者根据源码重新训练多车。
视频演示
提示
如果无法播放视频,按下
ctrl+F5刷新一下缓存即可
注意
- 由于存在甩尾现象加上场地限制(图像采集画面下方正好是一面墙)可以看到最后一辆小车被甩出场地(砸在墙上)
- 虽然甩尾现象存在,但是将6号车再次放回场地,依然能够完成跟随动作
- 如果采用4车,效果会更好
仿真综述
KKSWARM 项目的仿真基于 matlab 搭建,目前不支持在ROS下仿真。但是可以无缝过渡到ROS环境以及真实物理环境。
以下内容均在 matlab 下实现
Matlab仿真环境搭建
本教程将会引导读者搭建 KKSWARM 项目所需要的Matlab仿真环境。在搭建环境之前,确保已经安装了 Matlab2021b 版本及以上。
警告
目前尚未在低于Matlab2021b上进行测试,低于该版本可能导致程序无法运行。
Windows10环境
安装python2.7环境
- 点击下载 python2.7 for Windows
- 下载完成以后,双击进行安装。选择
Install for all users,然后点击Next如图1所示:
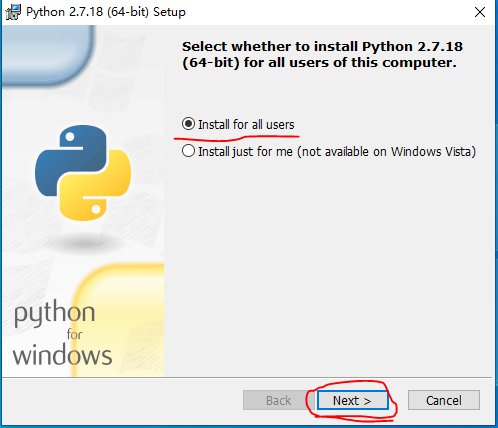
图1 python2.7安装界面
- 接着选择安装路径,可以 自定义路径,也可以选择 默认。这里是 默认路径。如图2所示:
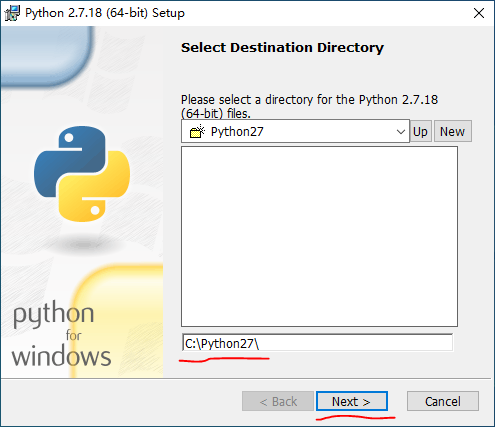
图2 路径选择界面
- 接着点击
Next,保持默认即可。如图3所示:
图3 自定义界面
-
接下来就会开始安装,等待安装完成即可。
-
安装完成以后,开始设置环境变量。依次打开 设置 -- 系统 -- 关于 -- 高级系统设置 -- 环境变量。
提示
如果是win11系统,依次打开 设置 -- 系统 -- 系统信息 -- 高级系统设置 -- 环境变量
然后双击 系统变量 下的
Path。如图4所示:
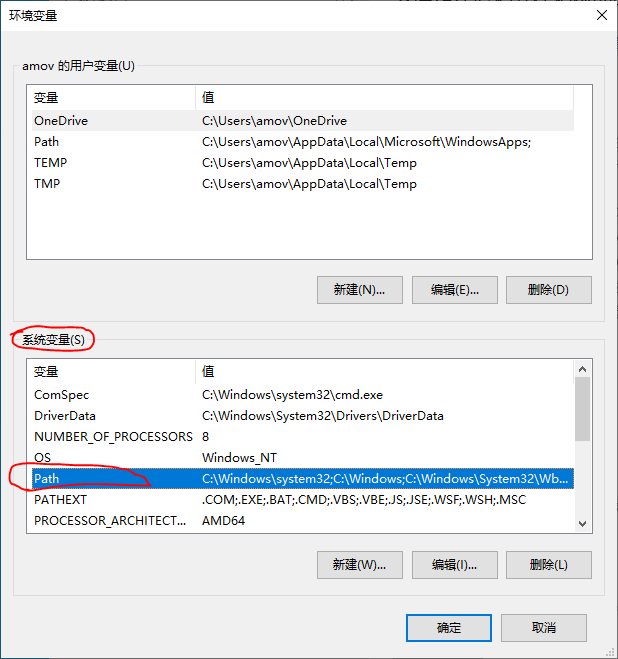
图4 环境变量设置界面
- 双击打开
Path后,点击 新建,然后将 第3步 安装的时候的路径复制下来即可。如图5所示:
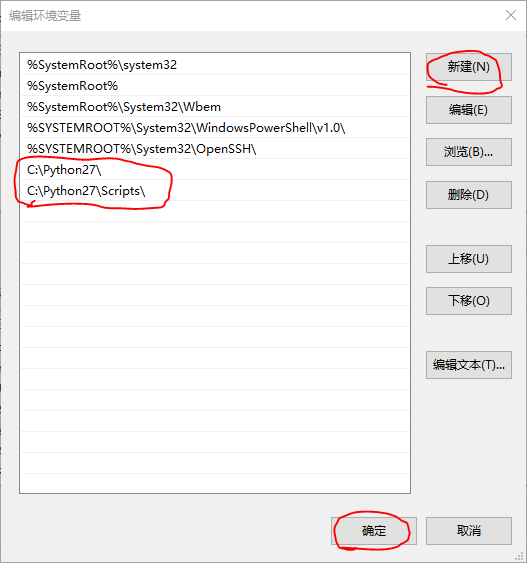
图5 添加环境变量
- 接着按下键盘上的
win+r,在弹出的界面中输入cmd,打开windows shell。如图6所示:
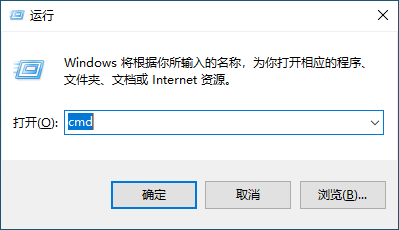
图6 按下 win + r 后的界面
- 在windows shell中输入命令
python并回车,将会返回 python 的解释器界面,表示环境变量设置成功。如图7所示:
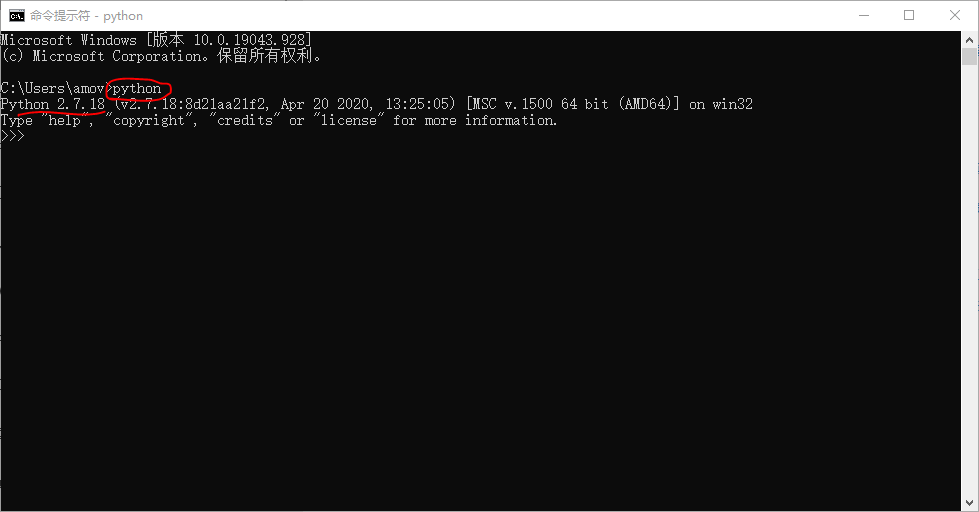
图7 python环境设置成功界面
安装MinGW
打开Matlab,点击 附件功能 -- 获取附件功能,在搜索栏输入MATLAB Support for MinGW-w64 C/C++ Compiler,在工具箱主界面右侧有一个安装按钮,点击安装,按照默认步骤安装即可
安装Cmake
- 点击下载 cmake3.24 for windows
- 下载完成以后,双击进行安装。需要注意的是,选中
Add Cmake to system PATH for all users如下图所示:
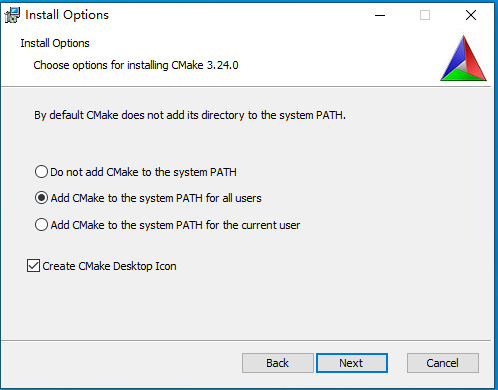
图19 设置cmake环境变量
- 然后选择安装路径,这里选择默认路径,如图20所示:
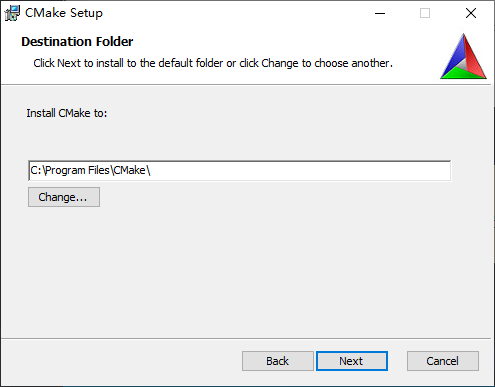
图20 cmake安装路径
- 等待安装完成
- 接着按下键盘上的
win+r,在弹出的界面中输入cmd,打开windows shell。如图21所示:
图21 按下 win + r 后的界面
- 然后输入命令
cmake --version,查看是否安装成功。如图22所示:
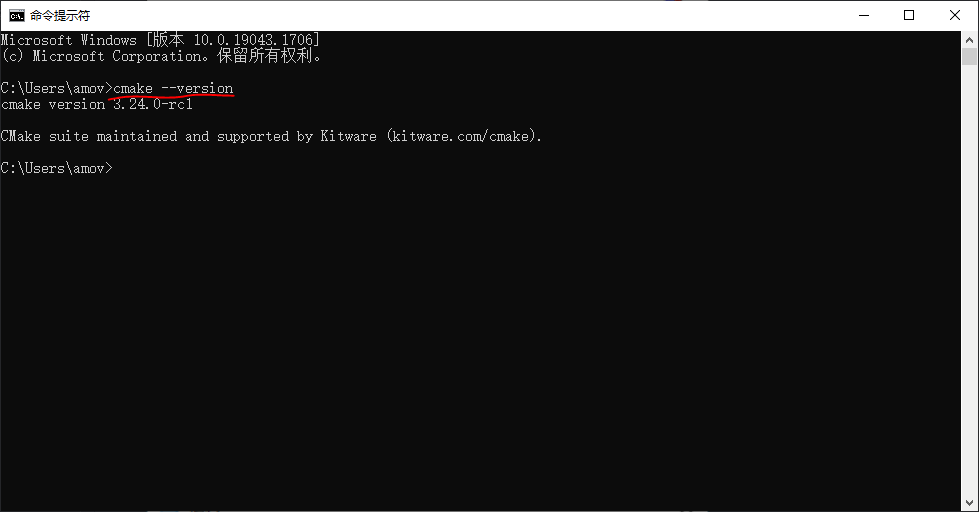
图22 安装成功界面
Matlab附加工具安装
KKSWARM 项目的开发需要安装以下 Matlab附加工具
- 依次打开 matlbaR2021b 菜单栏上的 附加功能 -- 获取附加功能,在弹出的界面中输入
MATLAB Coder Interface for Deep Learning Libraries,并且安装。 - 依次打开 matlbaR2021b 菜单栏上的 附加功能 -- 获取附加功能,在弹出的界面中输入
Mobile Robotics Simulation Toolbox,并且安装。
仿真Demo相关代码下载
git clone https://github.com/kkswarm/kk-robot-swarm
下载好以后,将 kk-robot-swarm/src/ 下的 matlab 文件夹拷贝出来即可
这里对matlab下的文件进行说明:
matlab代码说明
matlab文件下有 axxx.slx、bxxxx.slx、cxxxx.slx三种类型的仿真文件。其中:
a开头的文件表示matlan纯仿真模块,例如:a1_waypoint.slxb开头的文件表示matlab+ros仿真模块,该类文件中引入了ROS仿真c开头的文件表示真车使用的代码,该类文件用于生成ROS代码并部署到真实物理环境中
Linux环境
TODO
单车航点跟随仿真
本教程将会引导读者完成 单车航点跟随仿真 的演示。在使用此功能之前,确保已经完成了 仿真系统搭建
- 打开matlabR20021b,在命令行中输入
rosinit,启动ROS Master节点
rosinit
此时将会弹出ROS master 的窗口,不要关闭。最小化即可。 如图1所示:
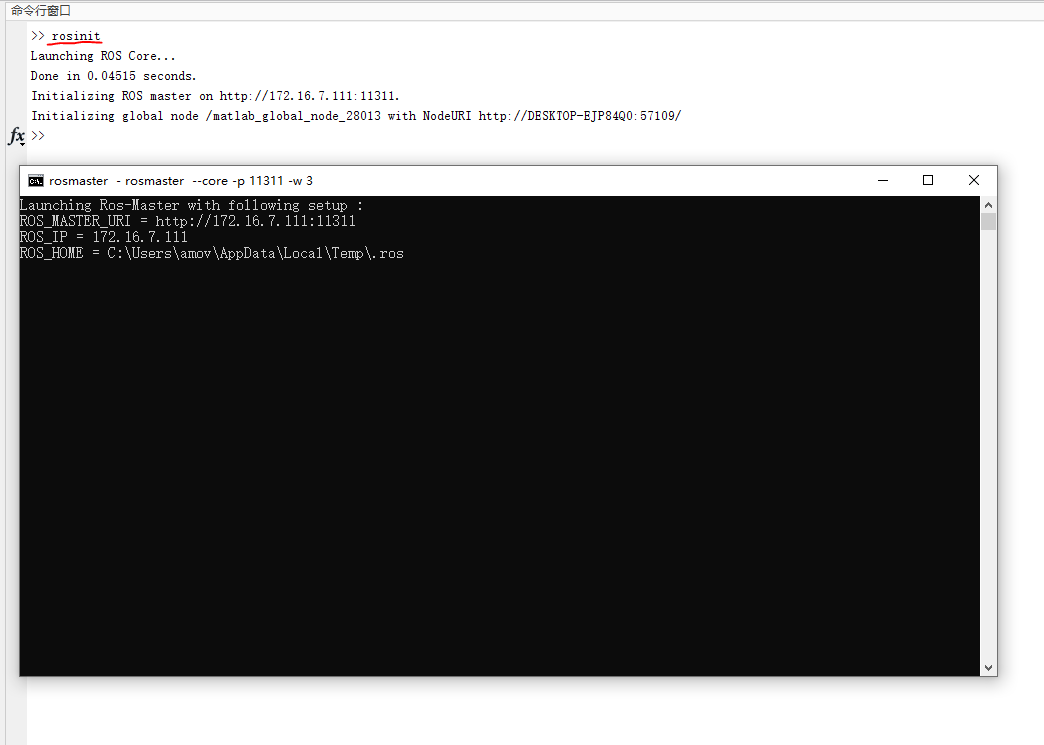
图1 rosinit
提示
在某些电脑环境中,即使按照仿真系统搭建步骤完成搭建,在运行
rosinit时,可能会出现Cannot connect to ROS master at http://localhost:11311. Check the specified address or hostname字样。解决的办法是,将
rosinit命令改为,rosinit("ip",端口)。如下图所示: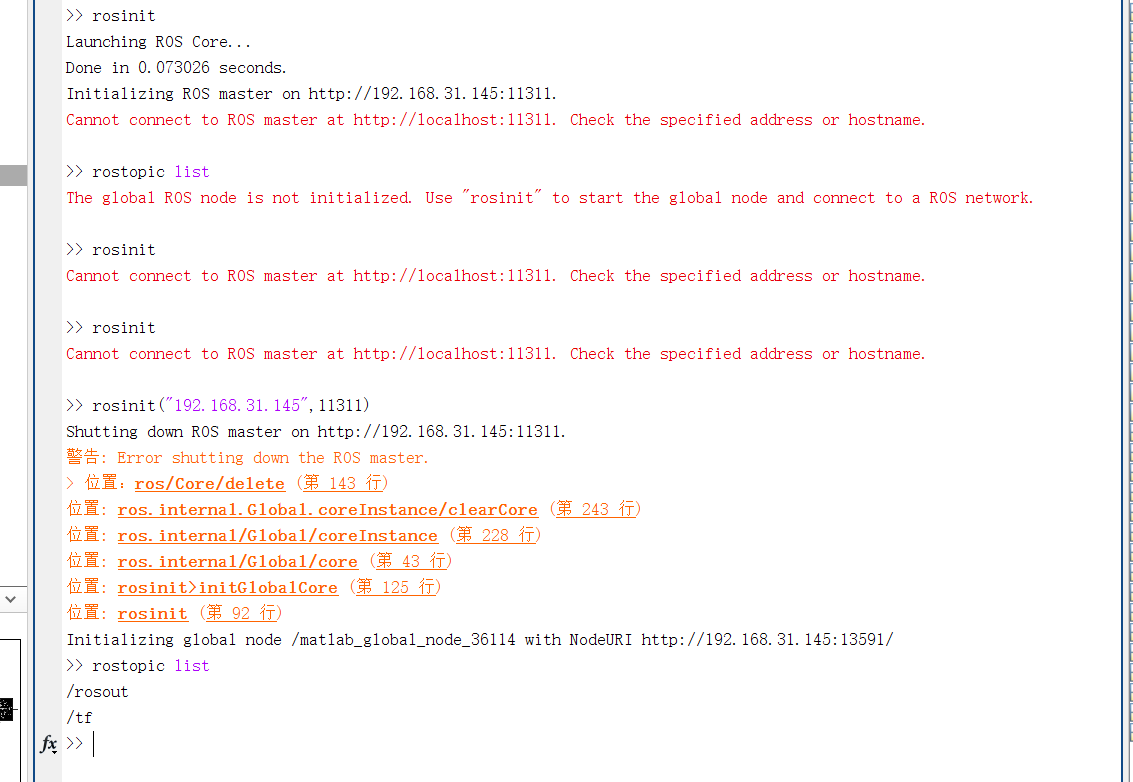
解决办法
- 打开
kk-robot-swarm/src/matlab/pid_waypoint/b1_waypoint.slx文件,如图2所示。
图2 b1_waypoint
- 点击菜单栏上的
ROS--Deplay to Localhost。如图3所示
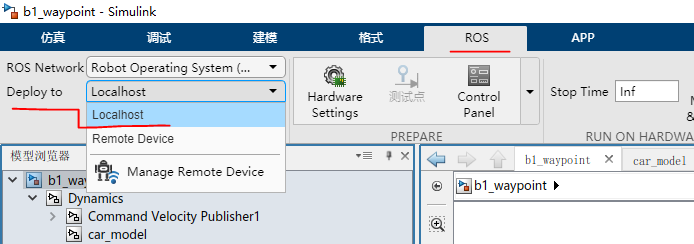
图3 b1_waypoint ROS
- 接着点击菜单栏上的
仿真--运行。启动仿真
图4 b1_waypoint ROS
- 等待编译完成,系统将会运行仿真。如图4所示:

图5 仿真结果
程序的最后,小车将会原地转圈,表示功能已经结束。
二次开发参数说明
- 打开
b1_waypoint.slx文件 - 在菜单栏上找到
建模--模型设置--模型属性--回调--InitFcn*如图1所示:
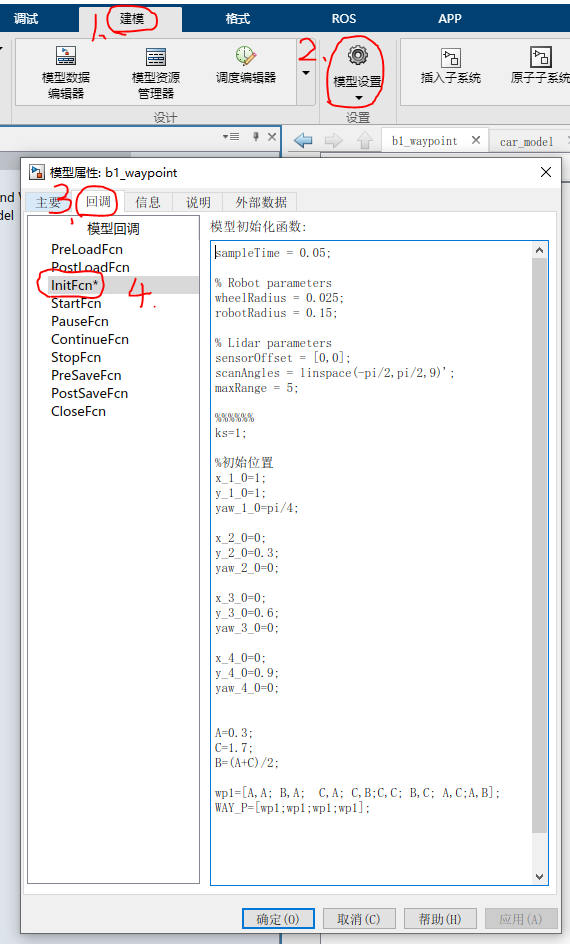
图1 模型设置界面
在这个界面,可以看到一些模型的属性,从上往下依次为
- 采样时间
- 小车的物理属性(轮子宽度、车体半径。用于小车动力学建模)
- 虚拟雷达参数
- 初始位置(小车启动的初始位置)
- 航点信息
一键生成ROS代码
- 首先在
b1_waypoint.slx文件中开发,完成想要的仿真效果,然后保存 - 删除
c1_waypoint.slx文件全部内容 - 接着将
b1_waypoint.slx文件内容全部复制到c1_waypoint.slx文件中,
图1 要复制的内容
- 在
c1_waypoint.slx文件中,删除 Dynamics 模块。如图9所示:
图2 删除Dynamics模块
注意
- 将
b1_waypoint.slx文件复制到c1_waypoint.slx的时候,注意查看复制后的模块的各个初始化条件是否正常。- 建议用户直接使用提供的模板
c1_waypoint.slx进行二次开发- 有关matlab开发文件说明,详见matlab文件说明
- 在编译代码之前,确保启动了
rosinit - 然后在菜单栏上的
ROS--Deploy to Remote Device。如图3所示
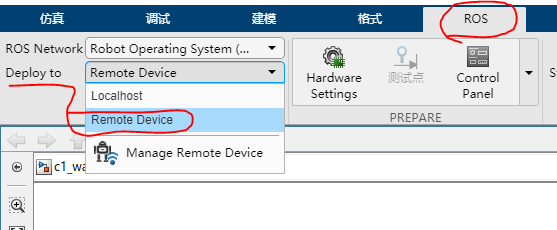
图3 生成ROS代码配置
- 然后点击菜单栏上的
ROS--Build Model--Build Model一键生成ROS代码,如图10所示
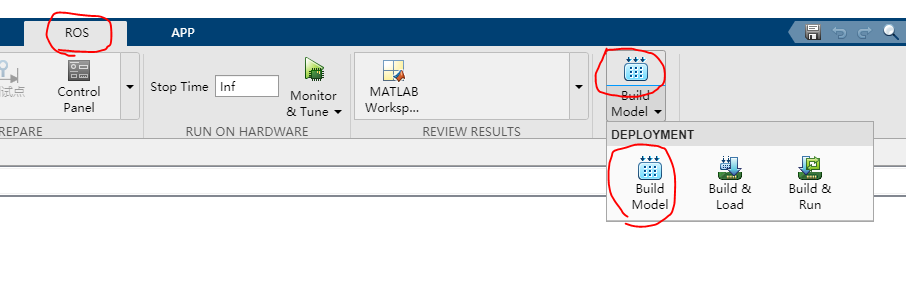
图3 生成ROS代码
-
等待编译完成以后,将会看到生成的压缩包文件
-
将生成的 ROS 代码复制到Linux系统中,并解压至
kk-robot-swarm/src/swarm/下,然后编译整个工作空间即可。
单车心形跟随仿真
本教程将会引导读者完成 单车心形跟随仿真 的演示。在使用此功能之前,确保已经完成了 仿真系统搭建
本教程作为 单车航点跟随 的进阶版本(因为算法原理是一样的)。将会引导读者如何自定义航路点,让小车按照给定的航路点进行运动。
- 打开matlabR20021b,在命令行中输入
rosinit,启动ROS Master节点
rosinit
此时将会弹出ROS master 的窗口,不要关闭。最小化即可。 如图1所示:
图1 rosinit
提示
在某些电脑环境中,即使按照仿真系统搭建步骤完成搭建,在运行
rosinit时,可能会出现Cannot connect to ROS master at http://localhost:11311. Check the specified address or hostname字样。解决的办法是,将
rosinit命令改为,rosinit("ip",端口)。如下图所示:解决办法
- 打开
kk-robot-swarm/src/matlab/pid_heart/b1_PP_s_heart.slx文件,如图2所示。
图2 b1_PP_s_heart
- 点击菜单栏上的
ROS--Deplay to Localhost。如图3所示
图3 b1_PP_s_heart ROS
- 接着点击菜单栏上的
仿真--运行。启动仿真
图4 b1_PP_s_heart ROS
- 等待编译完成,系统将会运行仿真。如图4所示:
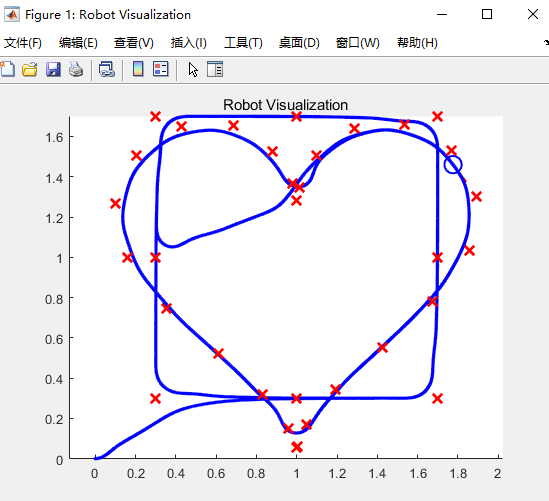
图5 仿真结果
小车将会先走一个正方形的航点,然后开始走心形航点。最后会在心形的凹槽部分画圆。
自定义航点
在这个Demo中。航点是由 plot_a_heart 模块生成的,如下图所示。双击该模块进入:

plot_a_heart
代码如下:
function z = plot_a_heart()
%% waypoints 应为 列数 等于 2 的数组。
x0=1;
y0=1;
dt=1;
t=0:dt:4*2*pi;
N=length(t);
x=zeros(1,N);
y=zeros(1,N);
for ii = 1:N
x(ii) =x0+ 1.8/32 *( 16*sin(t(ii)/4)^3);
y(ii) =y0+ 1.8/32 *( 13*cos(t(ii)/4)-5*cos(t(ii)/2) -2*cos(3*t(ii)/4)-cos(t(ii)) );
end
heart=[x,x,x;y,y,y]';
%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 四边形
A=0.3;
C=1.7;
B=(A+C)/2;
wp1=[A,A; B,A; C,A; C,B;C,C; B,C; A,C;A,B];
WAY_P=[wp1;wp1;heart];
z=WAY_P;
% plot(x,y)
提示
waypoints 应为 列数 等于 2 的数组
将想要自定义路径的代码替换即可。
8字形
%期望8字轨迹
sampleTime=0.01;
st=sampleTime;
tNum=1:1:20*pi;
T=60;
Ax=0.8;Ay=0.8;f=2*pi/T;%Yawd0=atan2(f*Ay,2*f*Ax);
Xd0=1;Yd0=1;%初始位置
Xd=Ax*sin(2*f*(tNum))+Xd0;
Yd=Ay*sin(f*(tNum))+Yd0;
wp=[Xd,Yd];
plot(Xd ,Yd,'*', 'Linewidth',5)
六边形
theta = linspace(0,2*pi,7);% linspace(x1,x2,N)用于产生x1,x2之间的N点行矢量。其中x1、x2、N分别为起始值、中止值、元素个数
x= 1+cos(theta);
y= 1+sin(theta);
wp=[x',y'];
plot(x,y,'*', 'Linewidth',5);
一键生成ROS代码
- 首先在
b1_PP_s_heart.slx文件中开发,完成想要的仿真效果,然后保存 - 删除
c1_PP_s_heart.slx文件所有内容 - 接着将
b1_PP_s_heart.slx文件内容全部复制到c1_PP_s_heart.slx文件中,
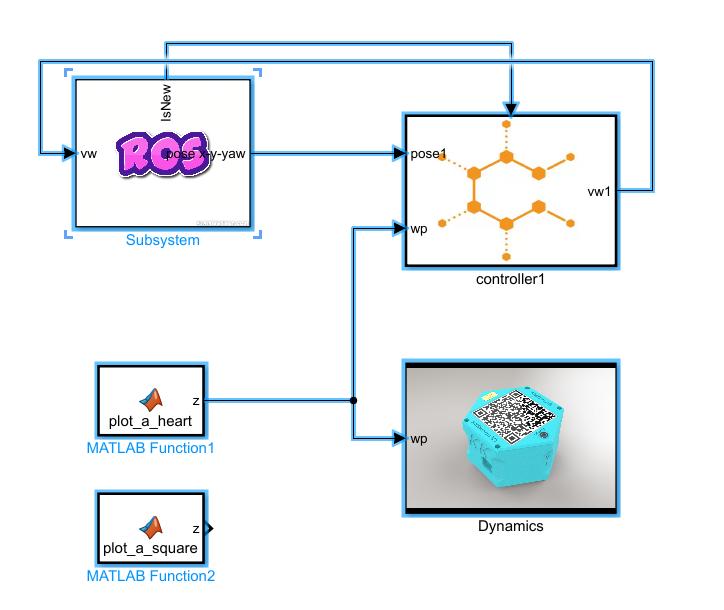
图1 要复制的内容
- 在
c1_PP_s_heart.slx文件中,删除 Dynamics 模块。如图9所示:
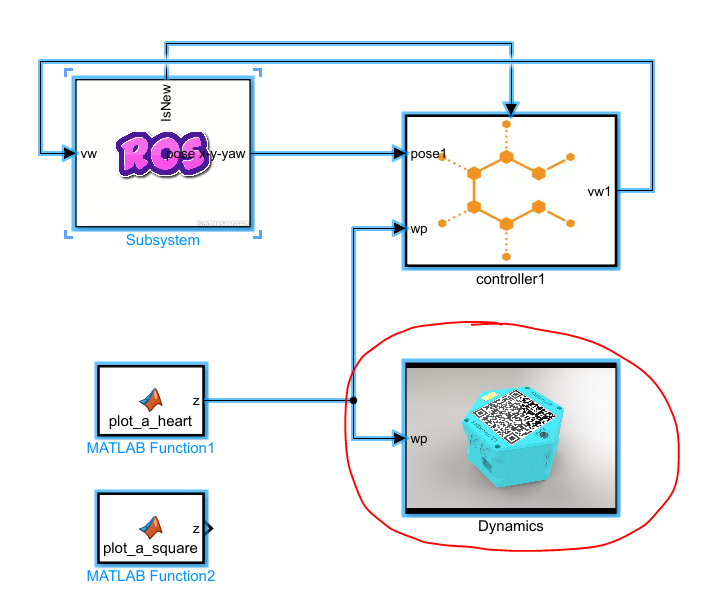
图2 删除Dynamics模块
注意
- 将
b1_PP_s_heart.slx文件复制到c1_PP_s_heart.slx的时候,注意查看复制后的模块的各个初始化条件是否正常。- 建议用户直接使用提供的模板
c1_PP_s_heart.slx进行二次开发- 有关matlab开发文件说明,详见matlab文件说明
- 在编译代码之前,确保启动了
rosinit - 然后在菜单栏上的
ROS--Deploy to Remote Device。如图3所示
图3 生成ROS代码配置
- 然后点击菜单栏上的
ROS--Build Model--Build Model一键生成ROS代码,如图10所示
图3 生成ROS代码
-
等待编译完成以后,将会看到生成的压缩包文件
-
将生成的 ROS 代码复制到Linux系统中,并解压至
kk-robot-swarm/src/swarm/下,然后编译整个工作空间即可。
单车边界回弹仿真
本教程将会引导读者完成 单车边界回弹仿真 的演示。在使用此功能之前,确保已经完成了 仿真系统搭建
一、单车边界反弹仿真
- 打开matlabR20021b,在命令行中输入
rosinit,启动ROS Master节点。此时将会弹出ROS master 的窗口,不要关闭。最小化即可。 如图1所示:
图1 rosinit
提示
在某些电脑环境中,即使按照仿真系统搭建步骤完成搭建,在运行
rosinit时,可能会出现Cannot connect to ROS master at http://localhost:11311. Check the specified address or hostname字样。解决的办法是,将
rosinit命令改为,rosinit("ip",端口)。如下图所示:解决办法
- 打开
kk-robot-swarm/src/matlab/soft_border/b1_soft_border.slx文件,如图2所示。
图2 b1_soft_border
- 点击菜单栏上的
ROS--Deplay to Localhost。如图3所示
图3 b1_soft_border ROS
- 接着点击菜单栏上的
仿真--运行。启动仿真
图4 b1_soft_border ROS
- 等待编译完成,系统将会运行仿真。如图5所示。
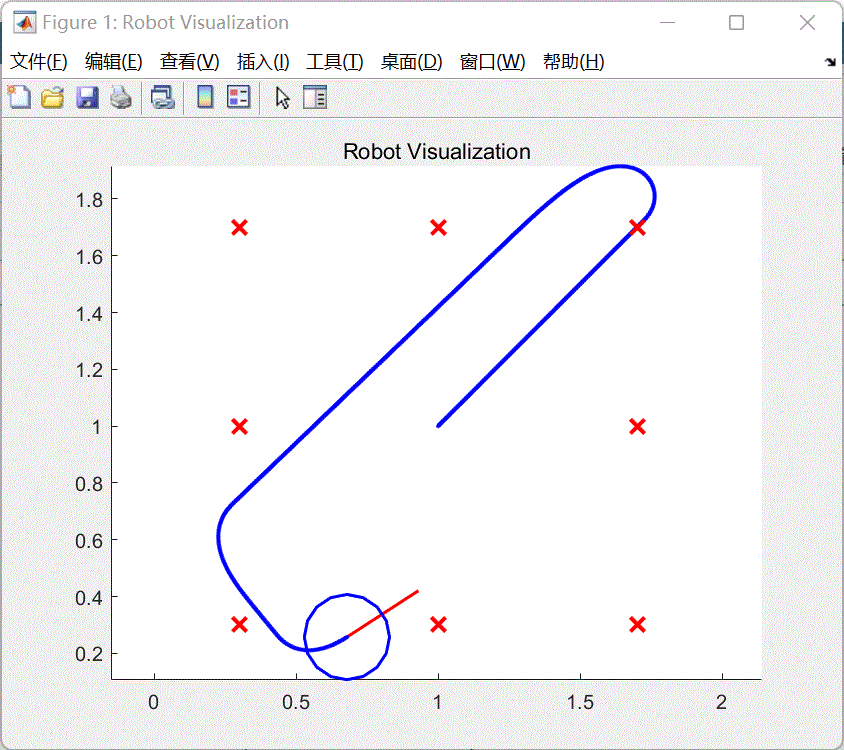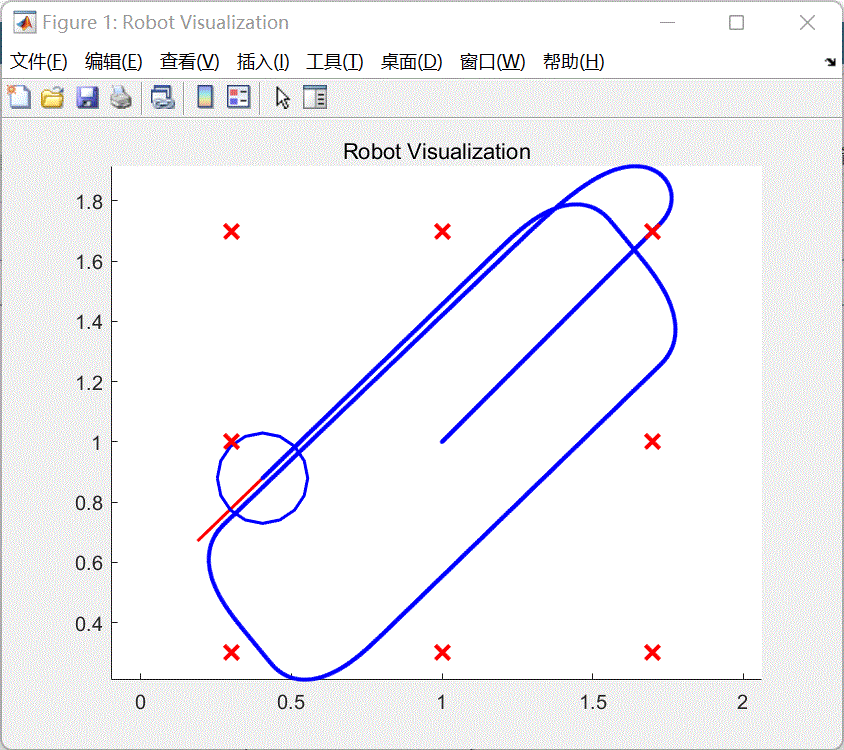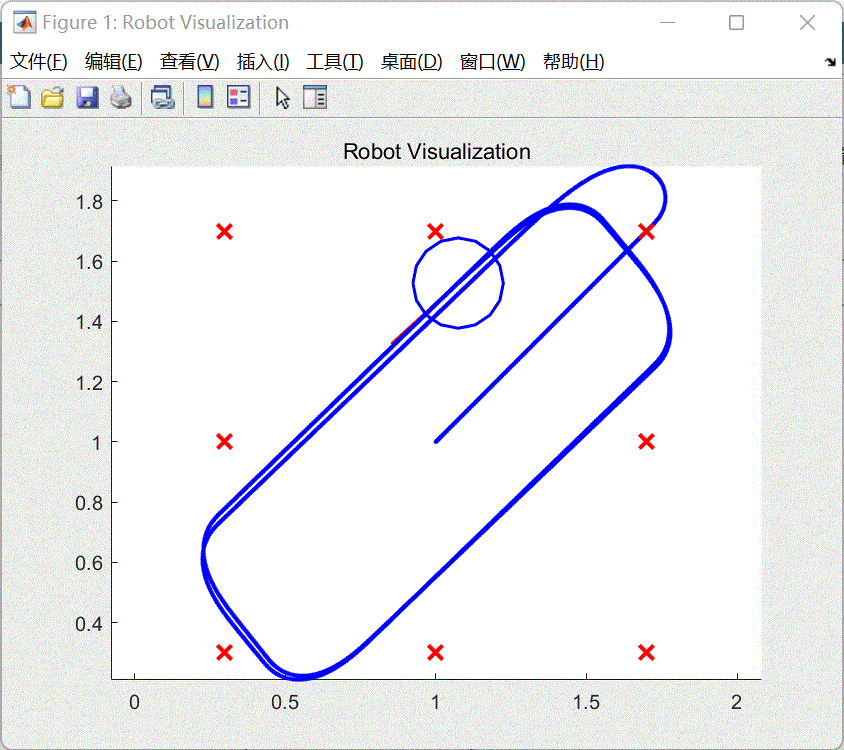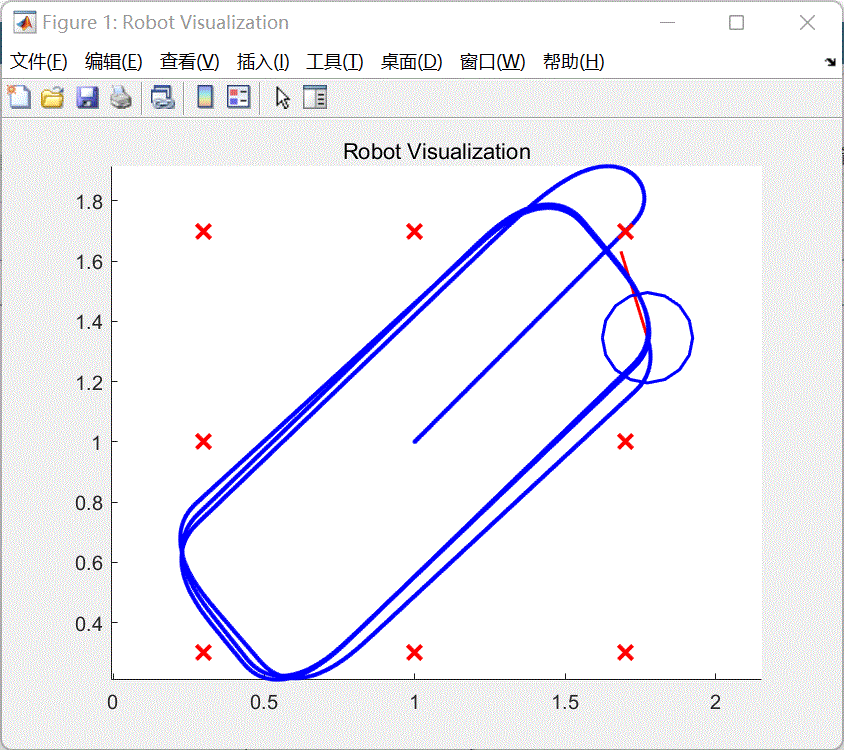
图5 仿真结果
一键生成ROS代码
-
首先在
b1_soft_border.slx文件中开发,完成想要的仿真效果,然后保存 -
删除
c1_soft_border.slx中所有内容 -
接着将
b1_soft_border.slx文件内容全部复制到c1_soft_border.slx文件中
图6 要复制的内容
- 在
c1_soft_border.slx文件中,删除 Dynamics 模块。如图7所示:
图7 删除Dynamics模块
注意
- 将
b1_soft_border.slx文件复制到c1_soft_border.slx的时候,注意查看复制后的模块的各个初始化条件是否正常。- 建议用户直接使用提供的模板
c1_soft_border.slx进行二次开发- 有关matlab开发文件说明,详见matlab文件说明
-
在编译代码之前,确保启动了
rosinit -
然后在菜单栏上的
ROS--Deploy to Remote Device。如图8所示
图8 生成ROS代码配置
- 然后点击菜单栏上的
ROS--Build Model--Build Model一键生成ROS代码,如图9所示
图9 生成ROS代码
-
等待编译完成以后,将会看到生成的压缩包文件
-
将生成的 ROS 代码复制到Linux系统中,并解压至
kk-robot-swarm/src/swarm/下,然后编译整个工作空间即可。
多车跟随仿真(强化学习)
本教程将会引导读者完成 多车跟随仿真(强化学习) 的演示。在使用此功能之前,确保已经完成了 仿真系统搭建
提示
除第一辆小车以外,每一辆小车都可以根据视轴前方的小车做跟随机动
提示
在某些电脑环境中,即使按照仿真系统搭建步骤完成搭建,在运行
rosinit时,可能会出现Cannot connect to ROS master at http://localhost:11311. Check the specified address or hostname字样。解决的办法是,将
rosinit命令改为,rosinit("ip",端口)。如下图所示:解决办法
多车跟随策略训练与评估
- 打开
kk-robot-swarm/src/matlab/pfc_rl/train_a2_pfc_td3.m多车跟随策略训练脚本文件。
提示
文件名
a2表示只有1台车跟随前车,td3表示所使用的强化学习算法名称——双延迟深度确定性策略梯度(Twin Delayed Deep Deterministic Policy Gradient)
部分代码说明:
% 设置打开的多车跟随策略仿真训练环境
mdl = "a2_pfc_rl";
open_system(mdl);
% 加载强化学习训练模块
blks = mdl + ["/RL Agent"];
env = rlSimulinkEnv(mdl,blks,obsInfo,actInfo);
% 重置仿真训练环境的部分参数,如小车的位置,具体详见a2pfcResetFcn.m脚本文件
env.ResetFcn = @a2pfcResetFcn;
% 创建跟随策略训练智能体-TD3算法
agent = createPFCAgent(obsInfo,actInfo);
% 设置仿真结束时间Tf为120秒,采样时间Ts为0.1秒,最大训练回合数maxepisodes为30000,每个回合的仿真步长为maxsteps
Tf = 120;
Ts = 0.1;
maxepisodes = 30000;
maxsteps = ceil(Tf/Ts);
% 不会根据跟随仿真设置的奖励值(如某个回合的奖励值达到100以上)中途停止训练
trainingOpts = rlTrainingOptions(...
'MaxEpisodes',maxepisodes,...
'MaxStepsPerEpisode',maxsteps,...
'Verbose',false,...
'Plots','training-progress',...
'StopTrainingCriteria','EpisodeReward',... % 中止训练条件为回合奖励值
'StopTrainingValue',100,... % 中止训练的奖励值为100
'ScoreAveragingWindowLength',10);
% 不根据跟随仿真设置的奖励值中途停止训练
trainingOpts = rlTrainingOptions(...
'MaxEpisodes',maxepisodes,...
'MaxStepsPerEpisode',maxsteps,...
'Verbose',false,...
'Plots','training-progress',...
'ScoreAveragingWindowLength',10);
% 是否开启异步分布式训练 硬件性能配置较高时建议开启
trainingOpts.UseParallel = true;
trainingOpts.ParallelizationOptions.Mode = "async";
trainingOpts.ParallelizationOptions.DataToSendFromWorkers = "Experiences";
trainingOpts.ParallelizationOptions.StepsUntilDataIsSent = 32;
% 是否开启训练模式 true为训练模式 false为评估模式
doTraining = false;
% 保存已训练好的神经网络策略数据
save('a2_pfc_rl.mat', 'agent');
% 评估模式查看仿真运行效果
simOptions = rlSimulationOptions('MaxSteps',1200);
experience = sim(env,agent,simOptions);
totalReward = sum(experience.Reward);
提示
在进行训练以前, 避免覆盖已经训练好的神经网络。还请在
train_a2_pcf_td3.m文件中做如下修改:
- 代码67行,
save('a2_pfc_rl.mat', 'agent');,将文件名称a2_pfc_rl.mat修改为自己训练的文件名称。例如:rl_training_xxx.mat- 代码56行,
doTraining = false;,改为true,进行训练- 代码62行,
load('a2_pfc_rl.mat','agent');,将文件名称改为自己训练的文件名称即可- 该强化学习对CPU和内存要求较高,大概需要
Intel i9-10700KCPU及以上,内存32GB及以上- 如果您的电脑硬件达不到要求,将代码 31-39行取消注释,同时将
'StopTrainingValue',100,...中的100,改为80,然后注释掉 42-47行。开始训练- 更多详情请见代码注释以及本教程前后部分wiki
- 将多车跟随策略训练脚本文件
train_a2_pfc_td3.m第56行代码改为doTraining = true;,即可开启运用强化学习方法训练多车跟随策略。
如图1所示,点击 运行 按钮,matlab会自动打开 a2_pfc_rl.slx 文件;
图1 运行多车跟随策略训练脚本文件
同时,matlab将自动打开 a2_pfc_rl.slx 文件,并且开启强化学习算法训练模式。如图2所示。
图2 a2_pfc_rl.slx文件
以及将会自动打开训练效果窗口和训练进程窗口(包括每次训练的奖励值情况),如图3所示。
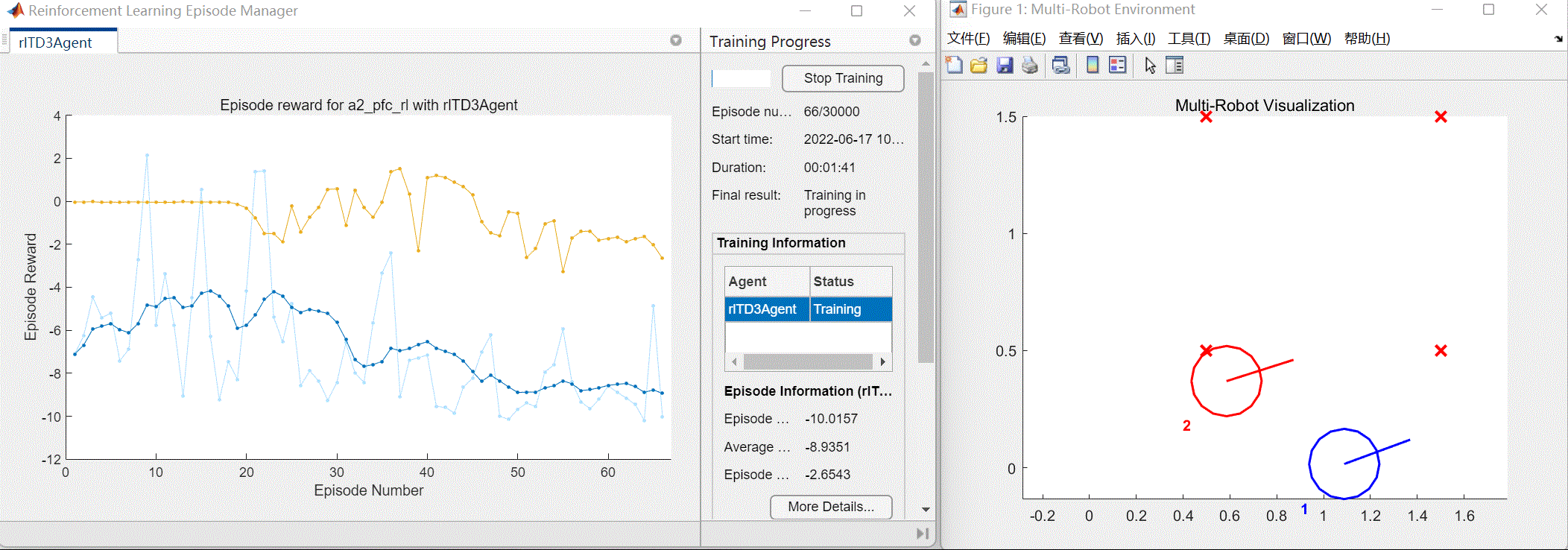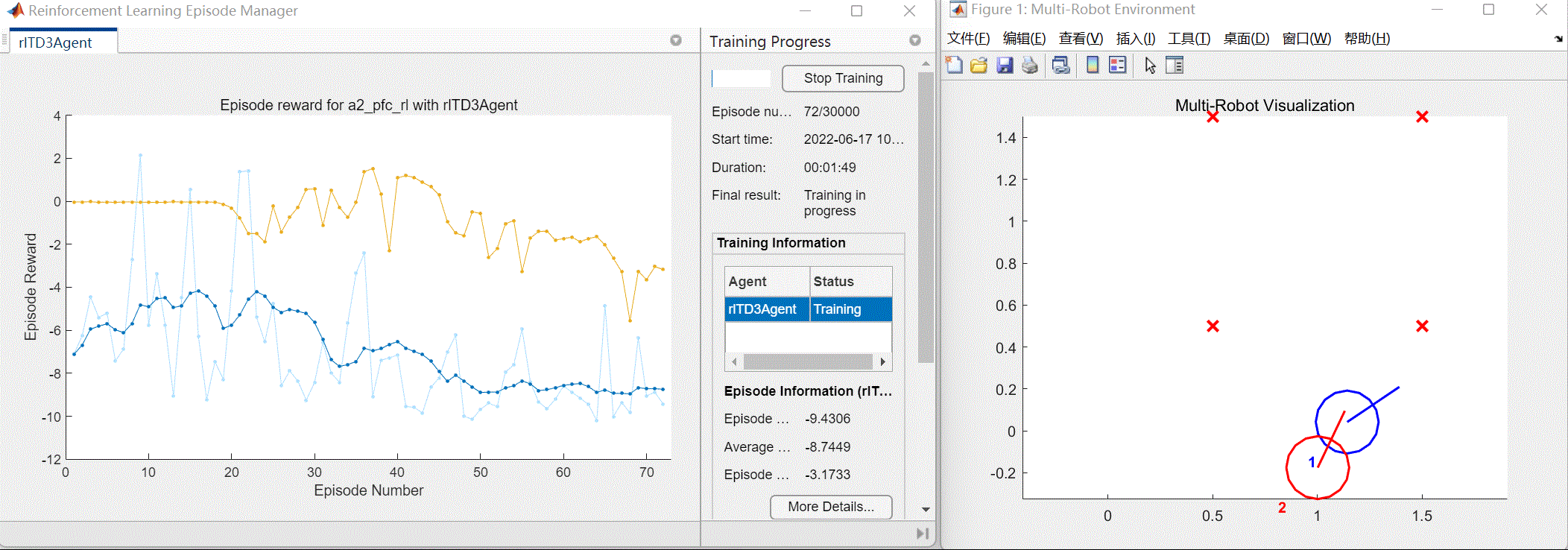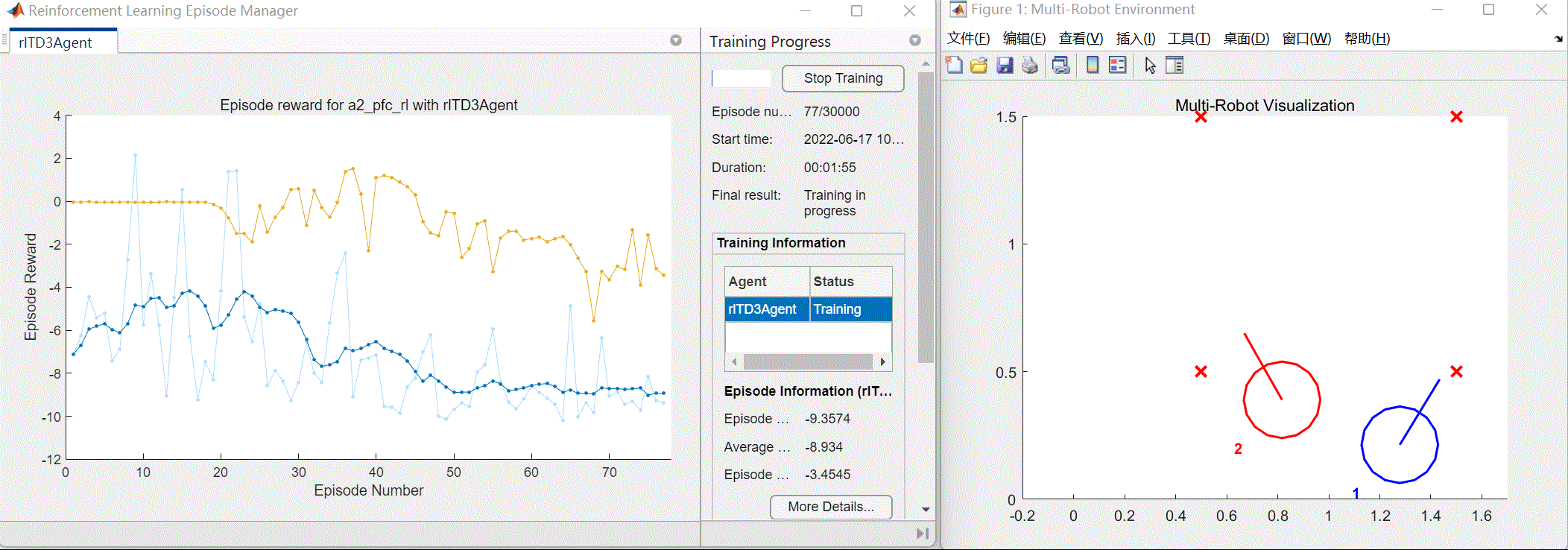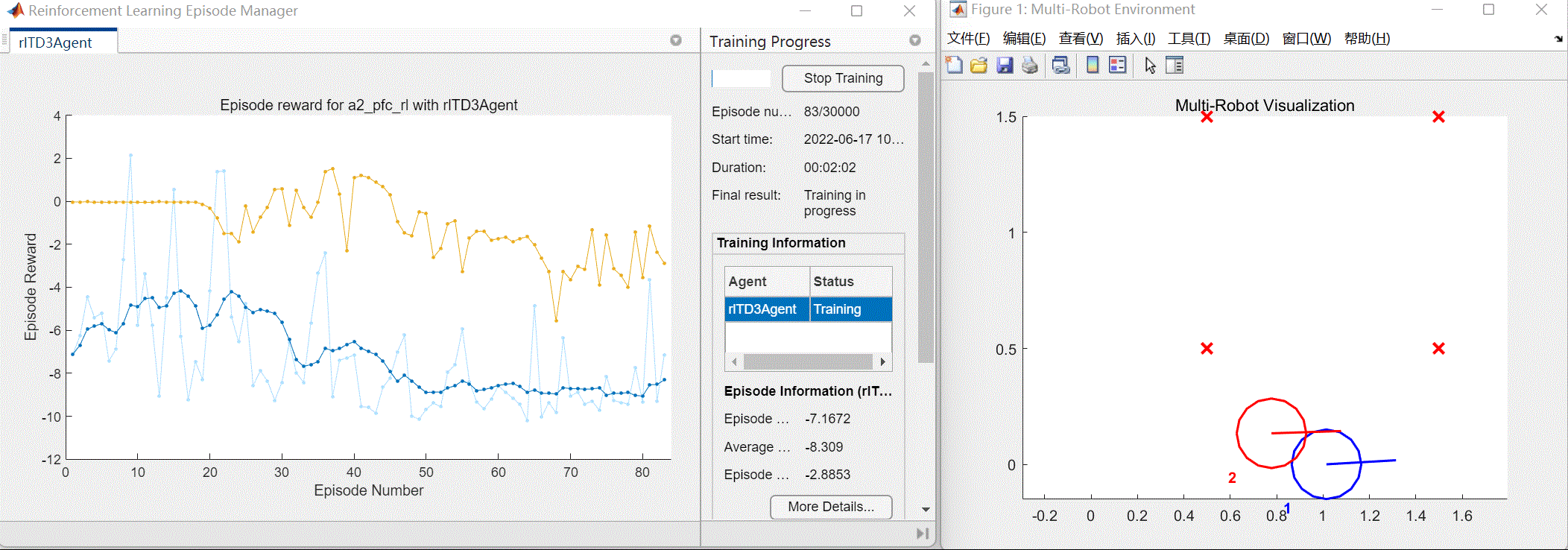
图3 训练效果与进程窗口
-
训练完成后,matlab会自动保存已训练好的神经网络策略数据文件,如
a2_pfc_rl.mat文件 -
将多车跟随策略训练脚本文件
train_a2_pfc_td3.m第56行代码改为doTraining =false,取消多车跟随策略训练。 同时将脚本第70-72行代码注释,然后点击运行按钮,将会打开a2_pfc_rl.slx文件,然后点击该文件菜单栏上的仿真--运行即可查看和评估当前使用强化学习算法训练的多车跟随效果。如图4所示。
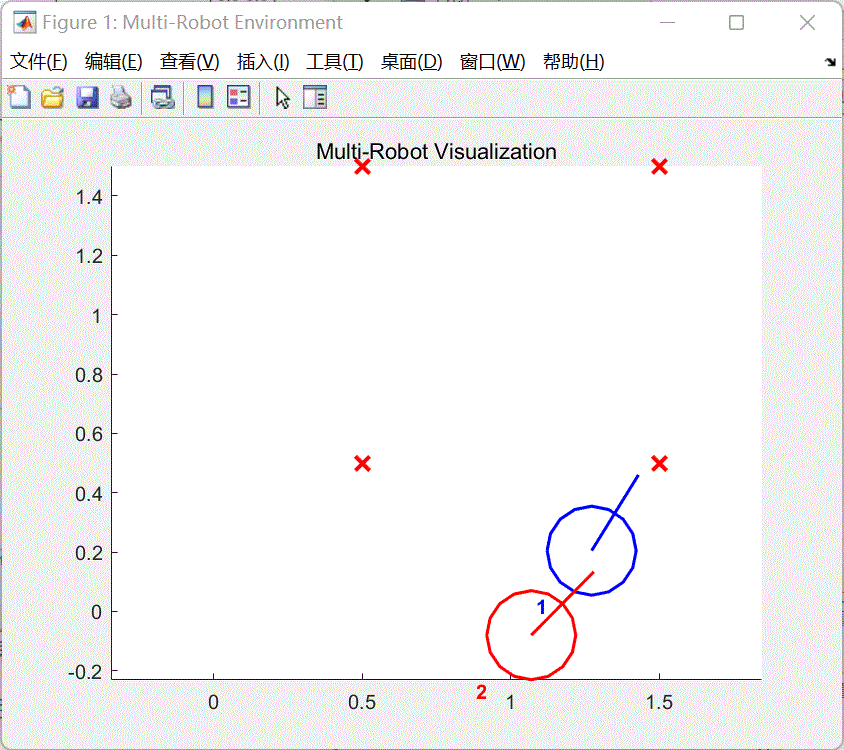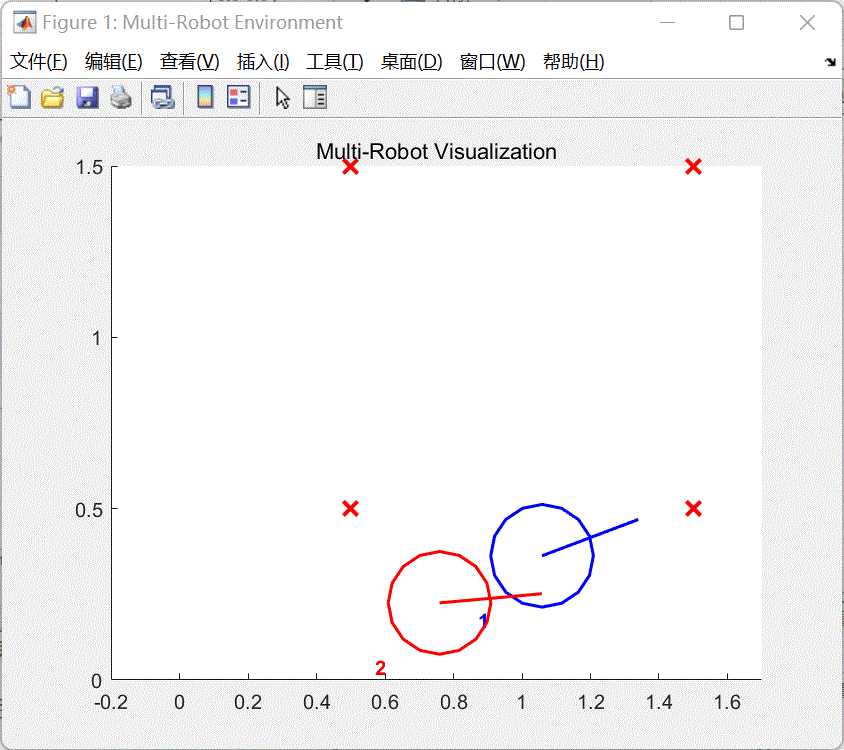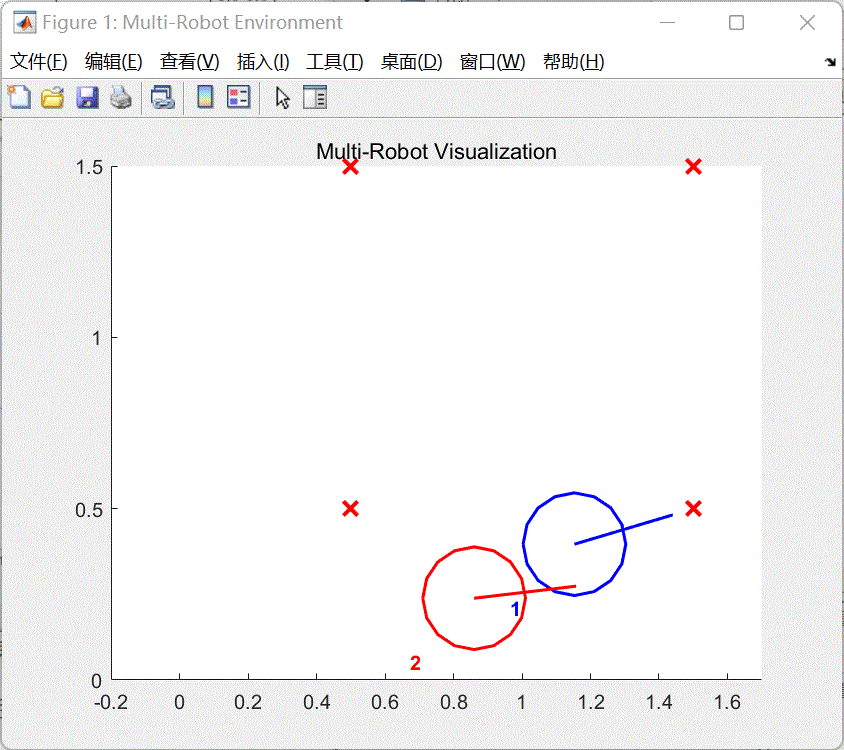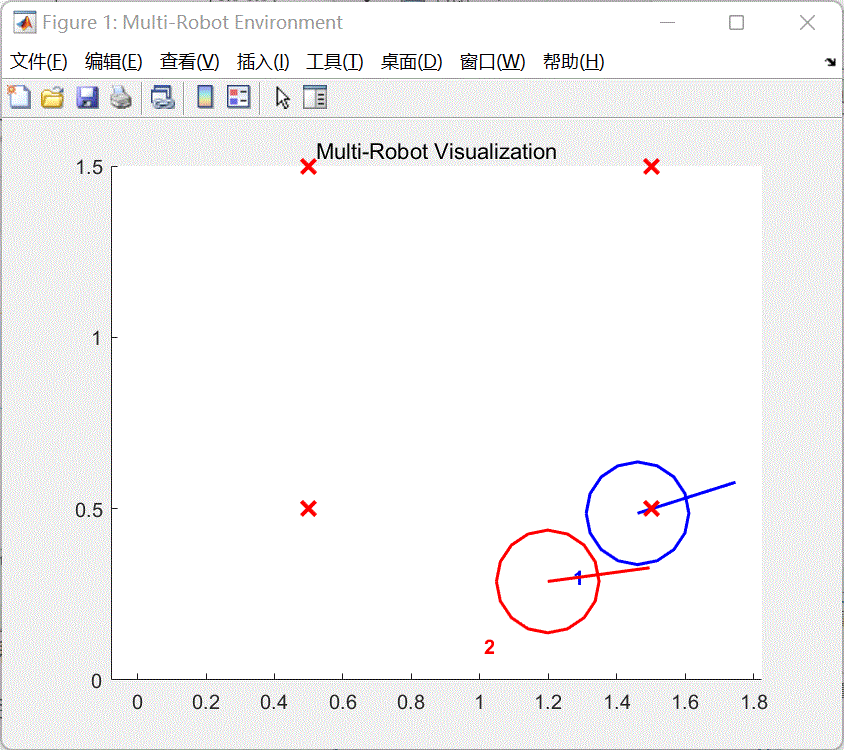
图4 训练效果
多车跟随策略生成与部署
- 打开
kk-robot-swarm/src/matlab/pfc_rl/gen_pfc_policy.m单车跟随策略生成脚本文件,如图5所示。点击运行按钮,matlab会自动生成PFC_Policy.m和PFC_Agent.mat两个文件,如图6所示。用户可以拷贝这两个文件,在自己的Simulink工程文件中按照正常脚本文件中的m函数调用多车跟随策略方法。
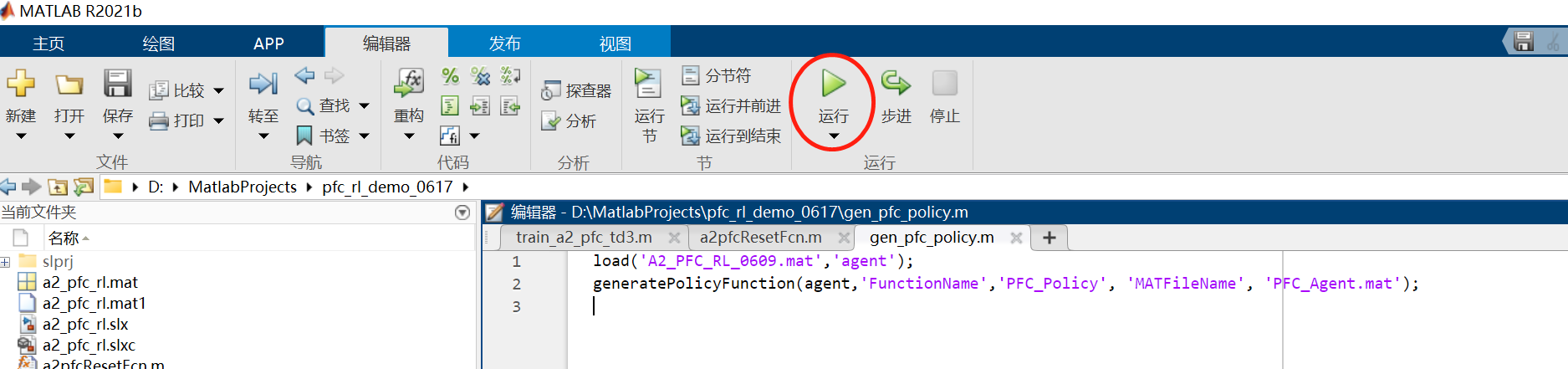
图5 运行单车跟随策略生成脚本文件
图6 matlab自动生成的单车跟随策略文件
- 打开
kk-robot-swarm/src/matlab/pfc_rl/b6_pfc_rl.slx文件,如图7所示。双击图7中的controller模块,可以看到跟随控制模块,名称为one_car_pfc,如图8所示。
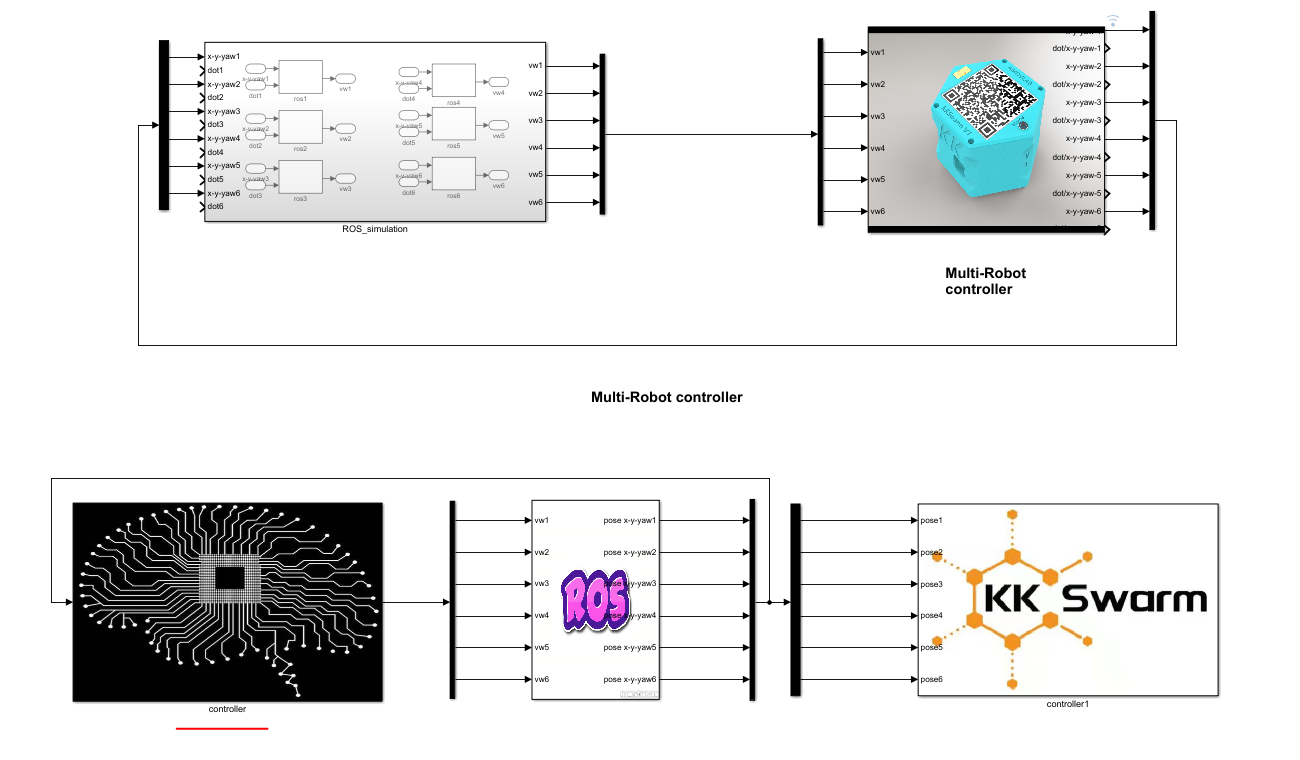
图7 运行多车跟随仿真环境
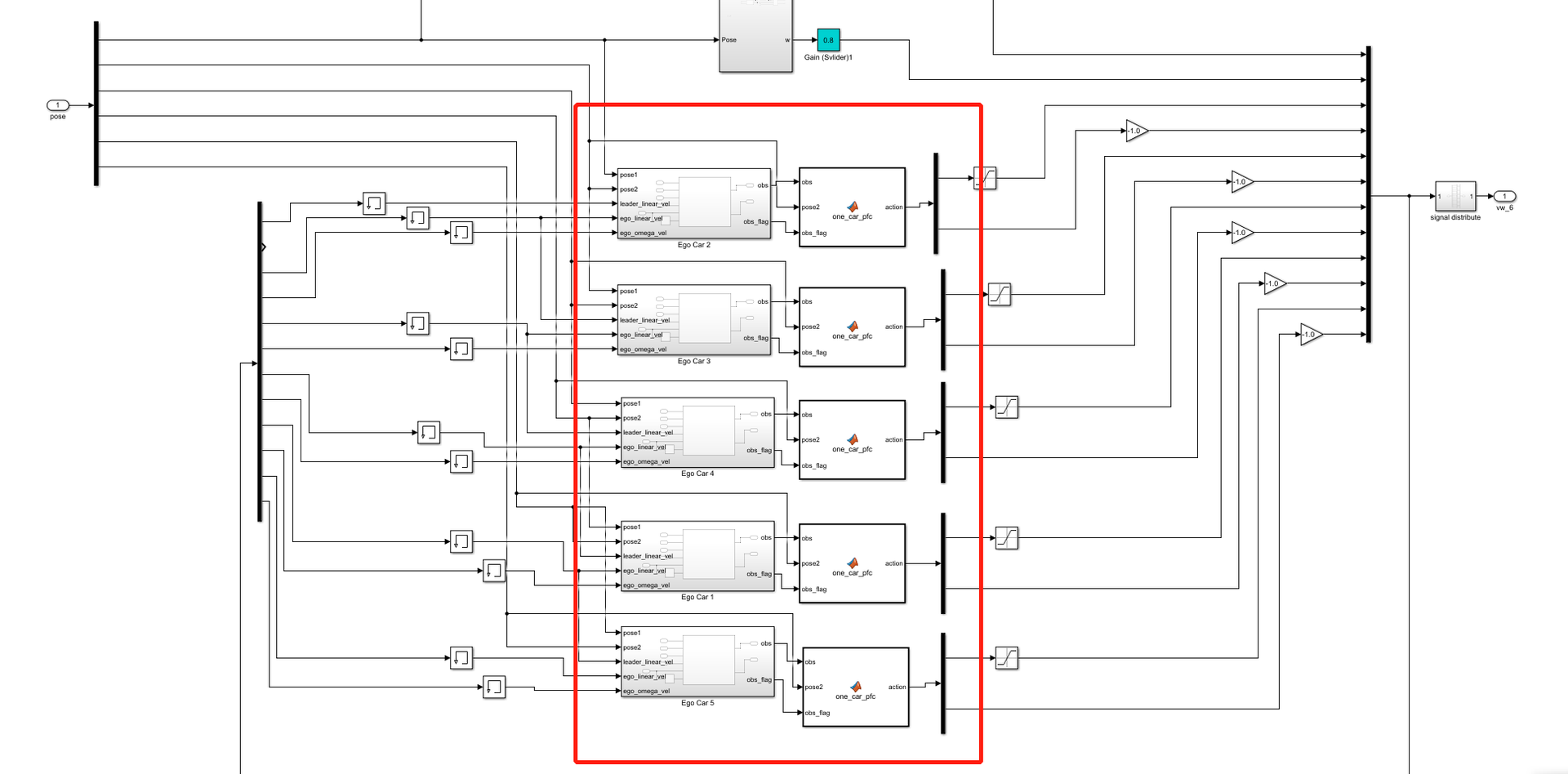
图8 多车跟随仿真环境的跟随控制模块
目前,跟随控制模块采用了 混合控制策略,考虑到前后车横距和纵距有时很大,可以采用比较简单的直线跟车策略。双击跟随控制模块,可以看到单车跟随的控制逻辑,示例代码如下:
function action = one_car_pfc(obs, pose2, obs_flag)
longitudinal_rel_dist = obs(3);
lateral_rel_dist = obs(6);
% 在前后车横距和纵距一定的情况下,使用强化学习训练的单车跟随策略
if longitudinal_rel_dist > -0.25 && abs(lateral_rel_dist) <=0.225 && longitudinal_rel_dist < 0
action = double(PFC_Policy(obs));
% 其它情况,使用直线跟车策略
else
action = simple_pfc(obs(1), obs(2), pose2(3));
end
if obs_flag==0
action = [0.0, 0.0];
end
end
% 直线跟车策略
function action = simple_pfc(x_delta, y_delta, yaw2)
kk = -1.0;
new_theta_cmd = atan2(y_delta, x_delta);
delta_theta = angdiff(yaw2, new_theta_cmd);
angular_speed = kk * delta_theta;
new_omega_cmd = angular_speed;
action = [0.225, new_omega_cmd];
end
- 在matlab命令行中输入
rosinit,启动ROS Master节点,如图9所示。
图9 rosinit
- 打开matlabR2021b,在命令行中输入命令
setenv('MW_MINGW64_LOC','C:\MinGW\'),然后再输入mex -setup C++。为matlab配置 MinGW 环境。如图10所示:

图10 Matlab配置MinGW
- 点击菜单栏上的
ROS--Deplay to Localhost。如图11所示
图11 deploy
-
接着点击菜单栏上的
仿真--运行。启动仿真, -
等待编译完成,系统将会运行仿真。如图12所示:
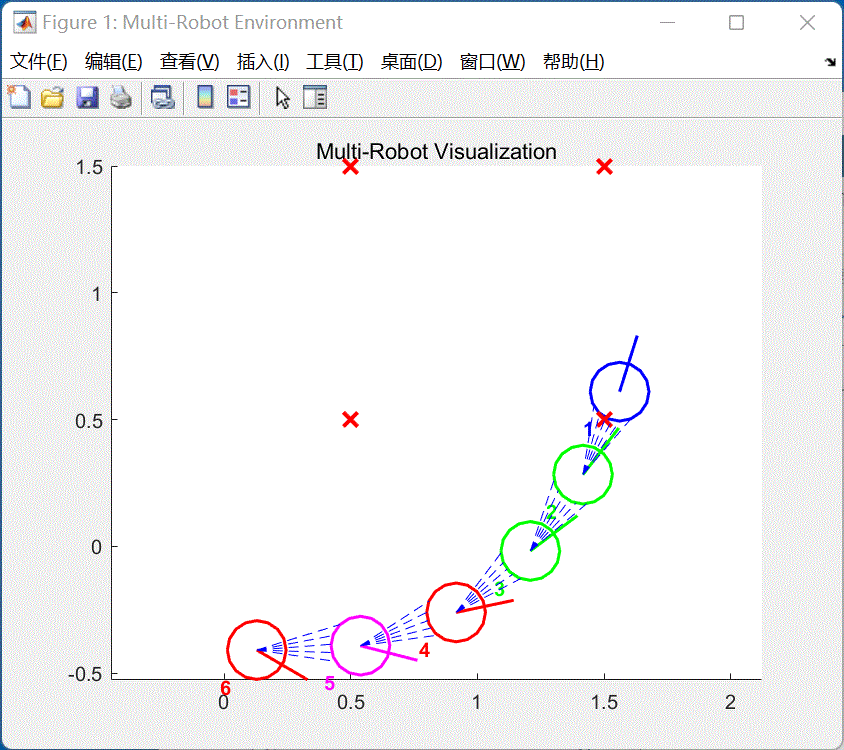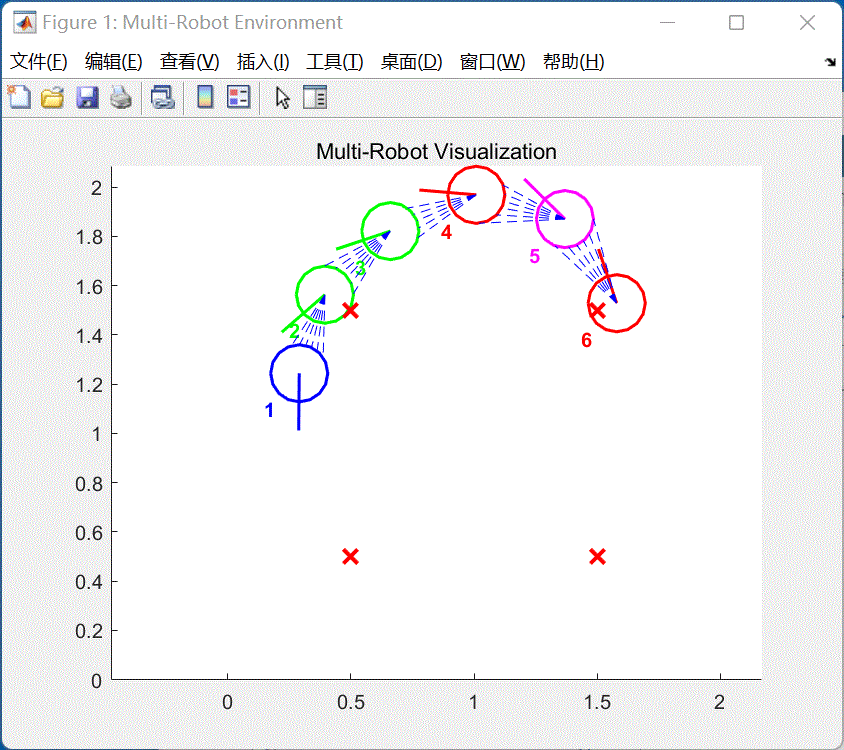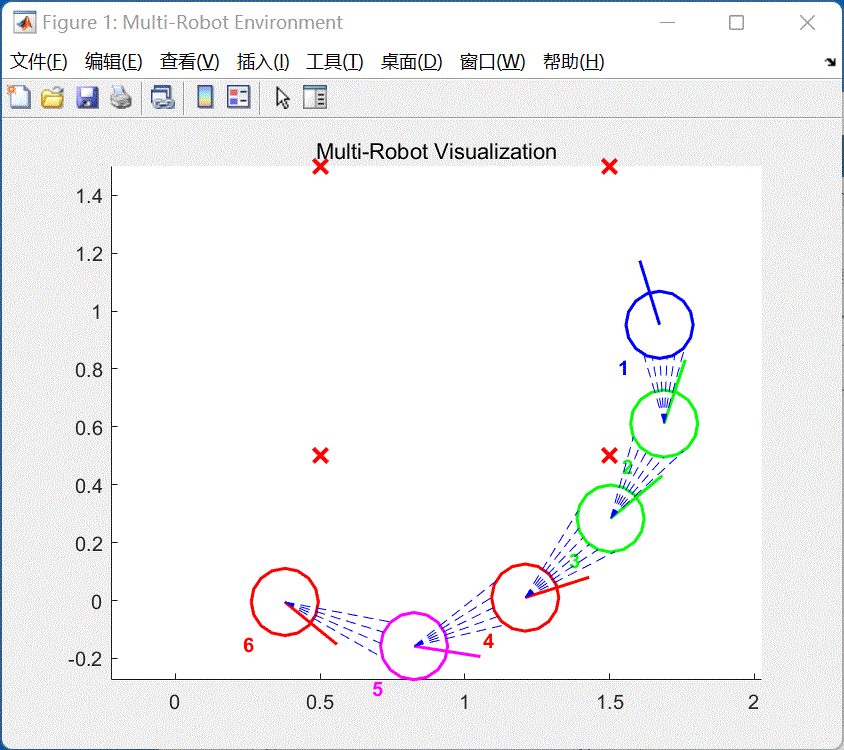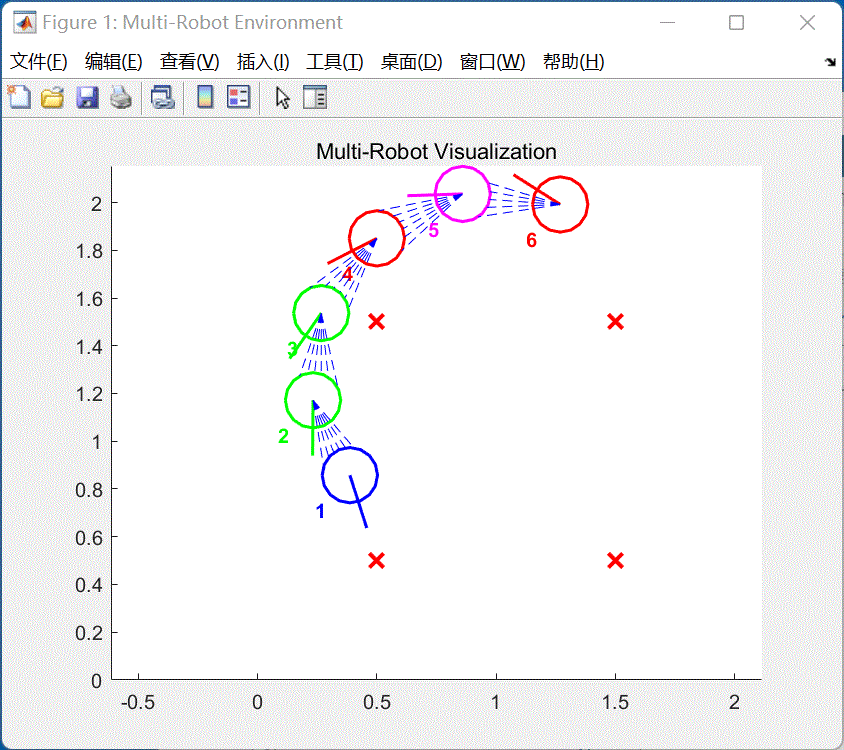
图12 运行
一键生成ROS代码
-
将多车跟随环境训练生成的
PFC_Policy.m和PFC_Agent.mat两个文件与kk-robot-swarm/src/matlab/pfc_rl/c6_pfc_rl.slx放在一起 -
在matlab命令行中输入
rosinit,启动ROS Master节点 -
打开
kk-robot-swarm/src/matlab/pfc_rl/c6_pfc_rl.slx文件,如图14所示。
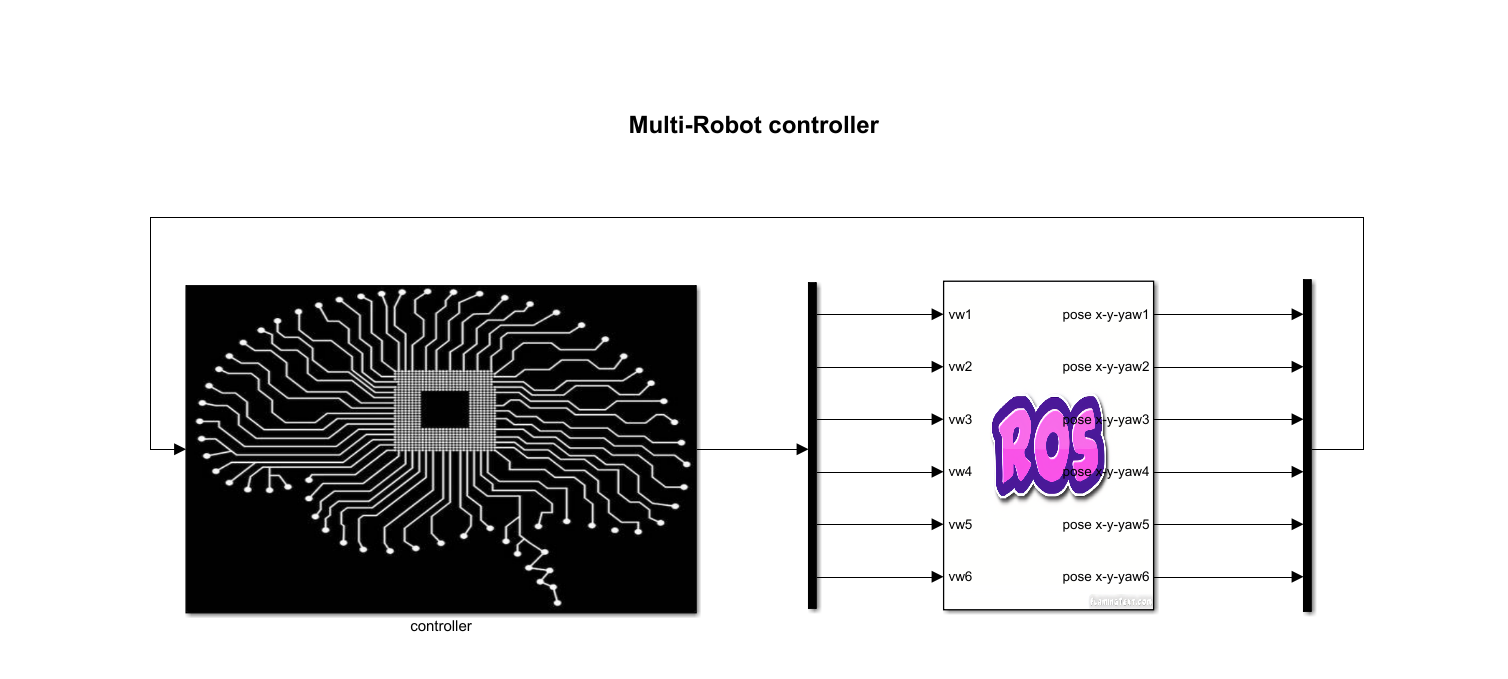
图12 c6_pfc_rl.slx
- 与
c6_pfc_rl.slx文件类似,双击图14中的controller模块,可以看到单车跟随控制模块,名称为one_car_pfc,如图15所示。
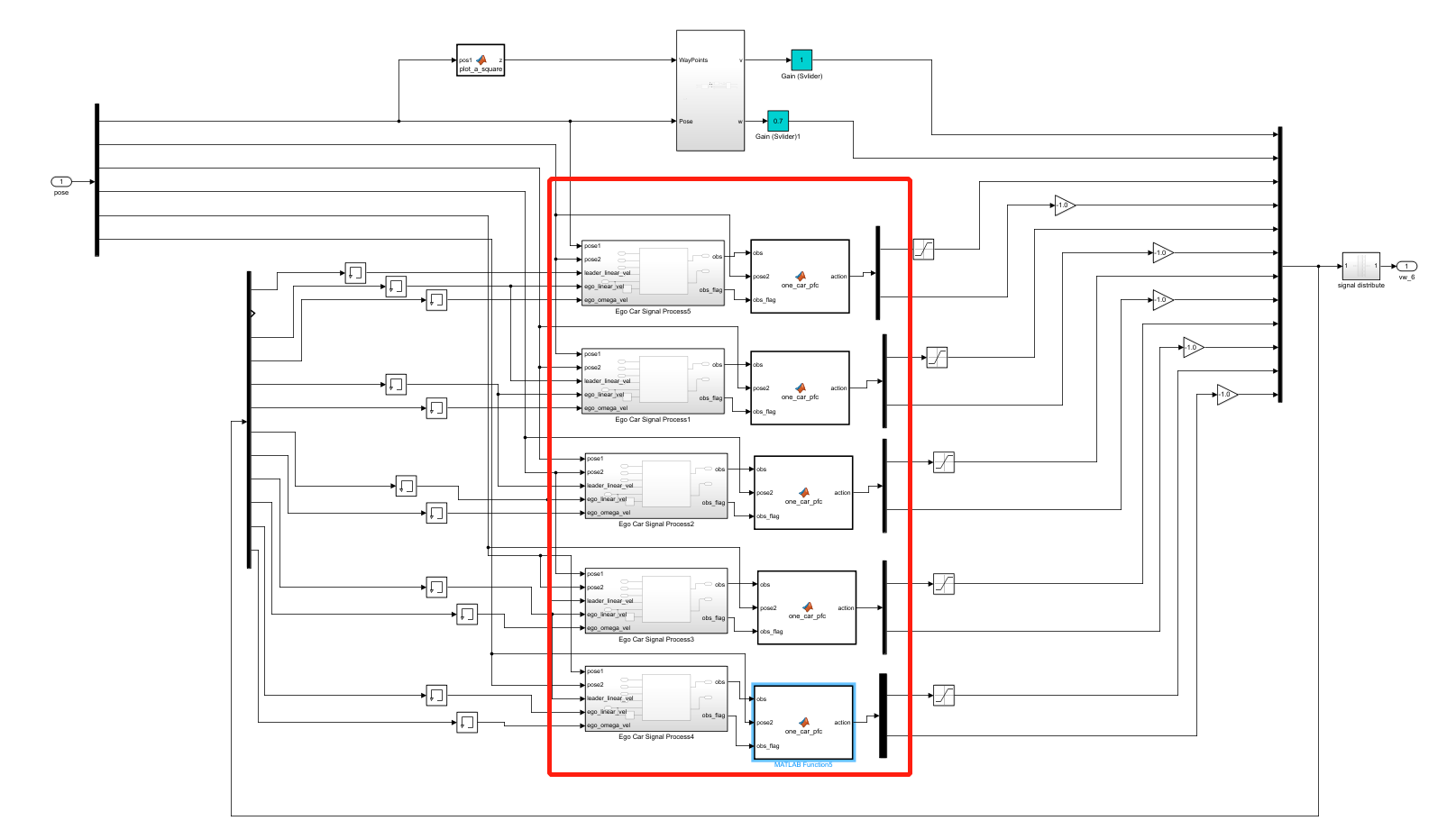
图15 controller模块
注意
多车跟随Demo在小车数量较多的时候(6车以上),存在甩尾和速度跟不上前车的情况
- 考虑到场地限制和甩尾情况,将5号车和6号车
one_car_pfc模块中的直线跟车策略的线速度参数增加了增益系数,分别为1.2和1.5,如图16、图17所示。
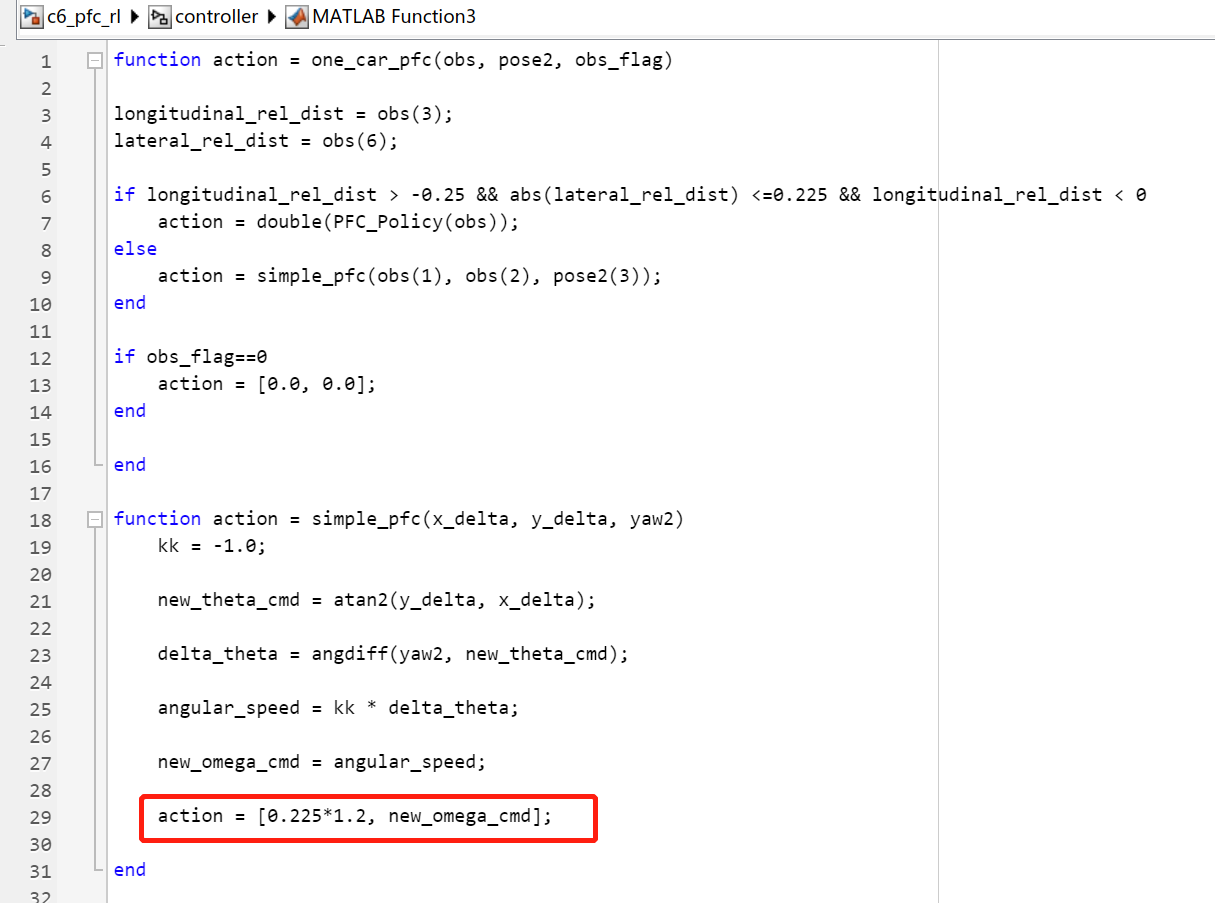
图16 增益系数1.2
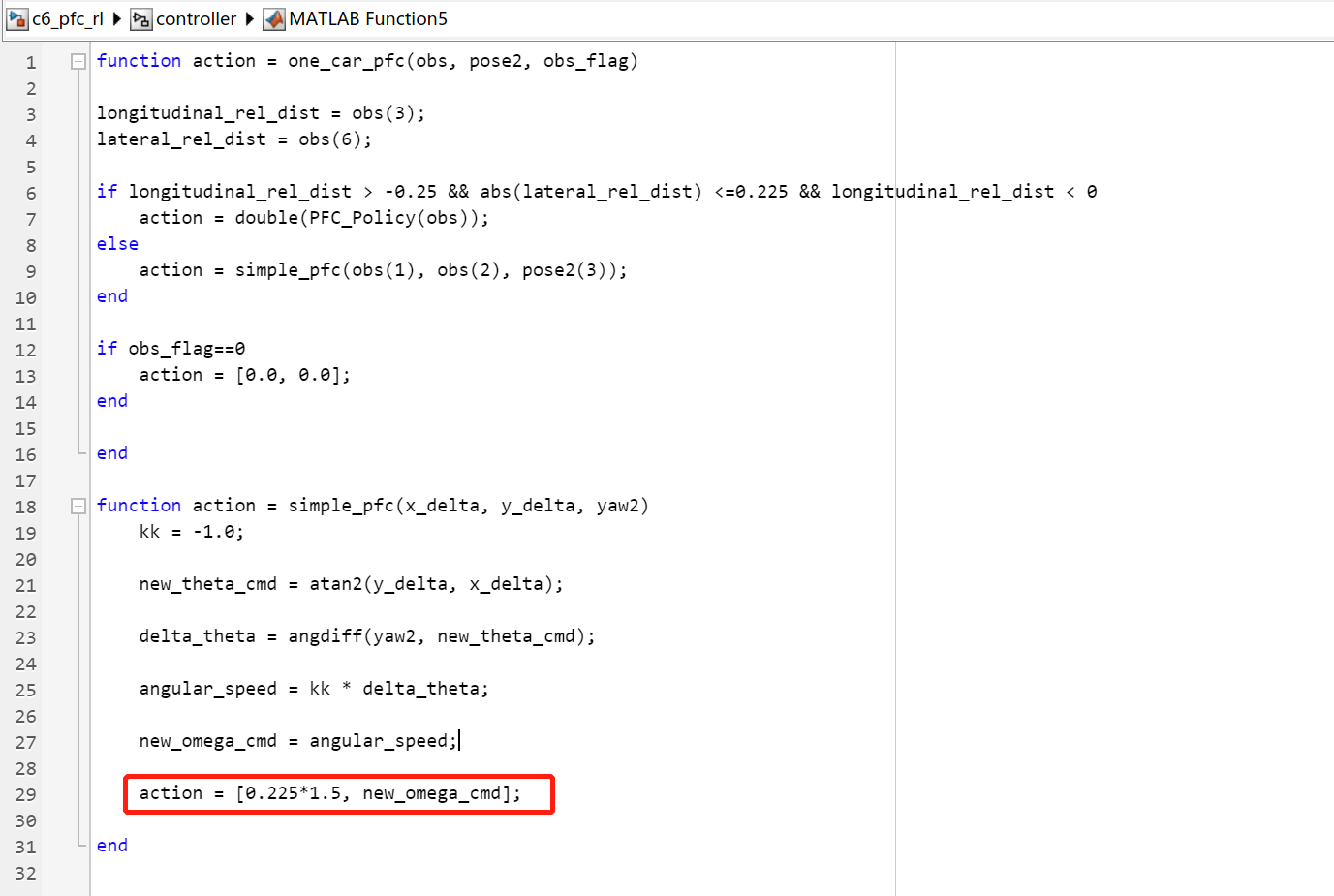
图17 增益系数1.5
-
在编译代码之前,确保启动了
rosinit -
然后在菜单栏上的
ROS--Deploy to Remote Device。如图18所示。
图18
- 然后点击菜单栏上的
ROS--Build Model--Build Model一键生成ROS代码,如图19所示
图19 生成ROS代码
-
等待编译完成以后,将会看到生成的压缩包文件,如
c6_pfc_rl.tgz。 -
将生成的 ROS 代码复制到Linux系统中,并解压至
kk-robot-swarm/src/swarm/下,然后编译整个工作空间即可。
多车航点跟随仿真(避障)
本教程将会引导读者完成 多车航点跟随仿真(避障) 的演示。在使用此功能之前,确保已经完成了 仿真系统搭建
- 打开matlabR20021b,在命令行中输入
rosinit,启动ROS Master节点
rosinit
此时将会弹出ROS master 的窗口,不要关闭。最小化即可。 如图1所示:
图1 rosinit
提示
在某些电脑环境中,即使按照仿真系统搭建步骤完成搭建,在运行
rosinit时,可能会出现Cannot connect to ROS master at http://localhost:11311. Check the specified address or hostname字样。解决的办法是,将
rosinit命令改为,rosinit("ip",端口)。如下图所示:解决办法
- 打开
kk-robot-swarm/src/matlab/goto_target/b6_goto_target.slx文件,如图2所示。
图2 b1_waypoint
- 点击菜单栏上的
ROS--Deplay to Localhost。如图3所示
图3 b1_waypoint ROS
- 接着点击菜单栏上的
仿真--运行。启动仿真
图4 b1_waypoint ROS
- 等待编译完成,系统将会运行仿真。如图4所示:
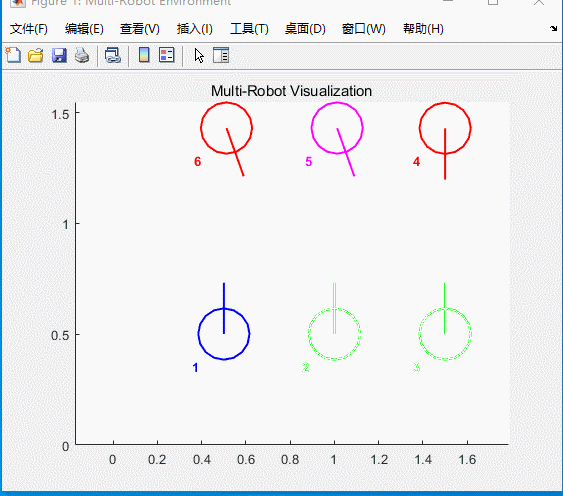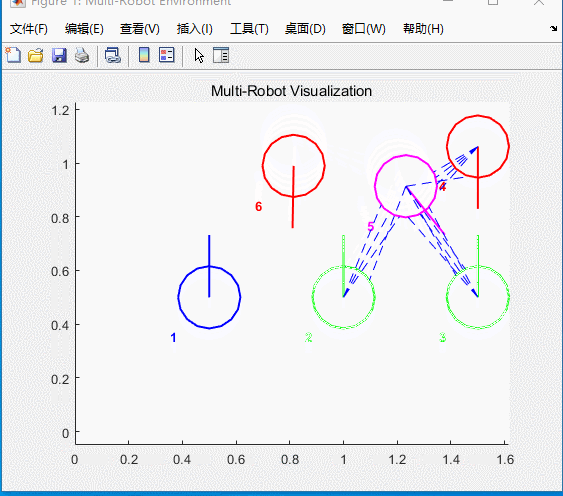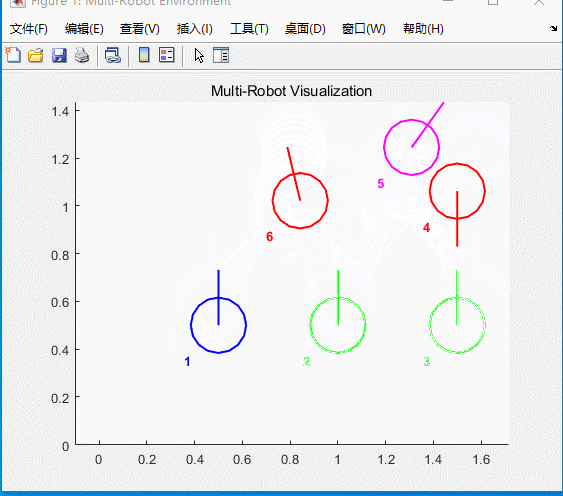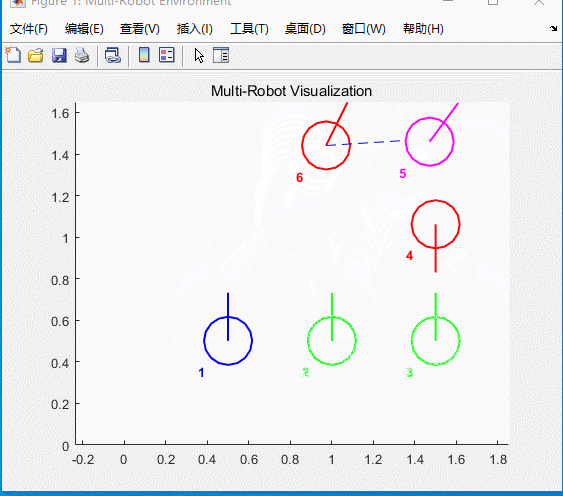
图5 仿真结果
六辆小车将会到达给定的目标点位置,同时自带避障功能。虚线为虚拟雷达。
二次开发参数说明
该程序的预定义位置如图6所示:
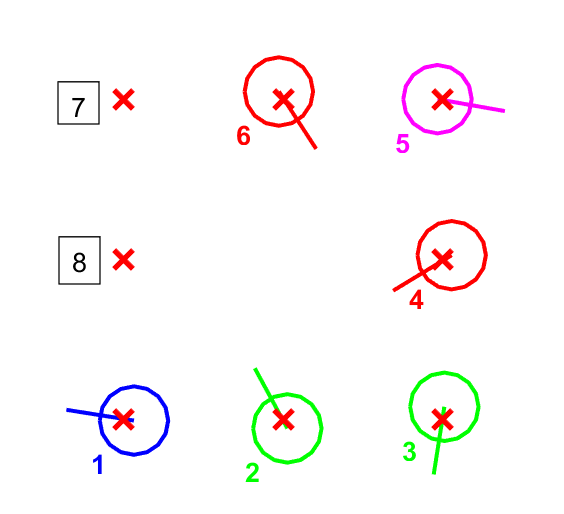
图6 预定义位置
打开 kk-robot-swarm/src/matlab/pub_wp.m 文件,如下所示:
wppub = rospublisher('/wp','std_msgs/Float64','DataFormat','struct');
msg = rosmessage(wppub);
msg.Data = 123456;
%msg.Data = 235467;
%msg.Data = 156724;
%msg.Data = 812345;
send(wppub,msg);
topic = wppub.TopicName
b=wppub.rosmessage
如图6所示,此时场上各车的位置为:123456,此时要想改变小车的位置。将上述代码中的 msg.Data = 123456; 改为 msg.Data = 812345;, 然后点击菜单栏上的 运行 即可。如图7所示:
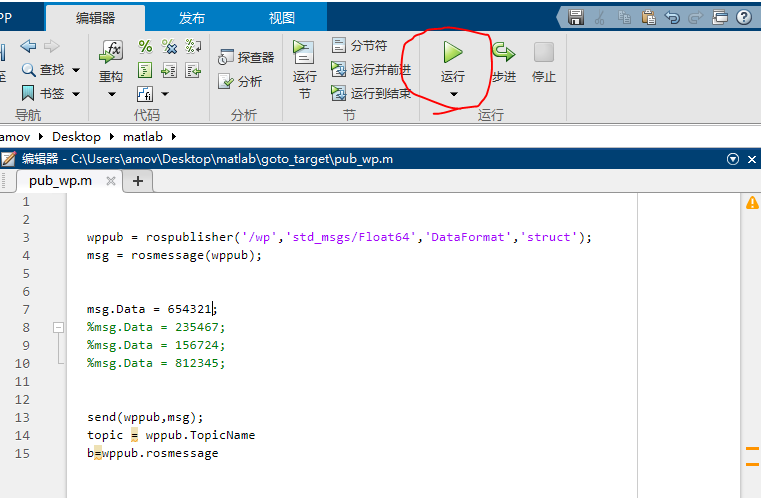
图7 修改位置
msg.Data = 812345 表示的含义如下:
- 1车->8位置
- 2车->1位置
- 3车->2位置
- 4车->3位置
- 5车->4位置
- 6车->5位置
然后小车就会按照下述过程运动
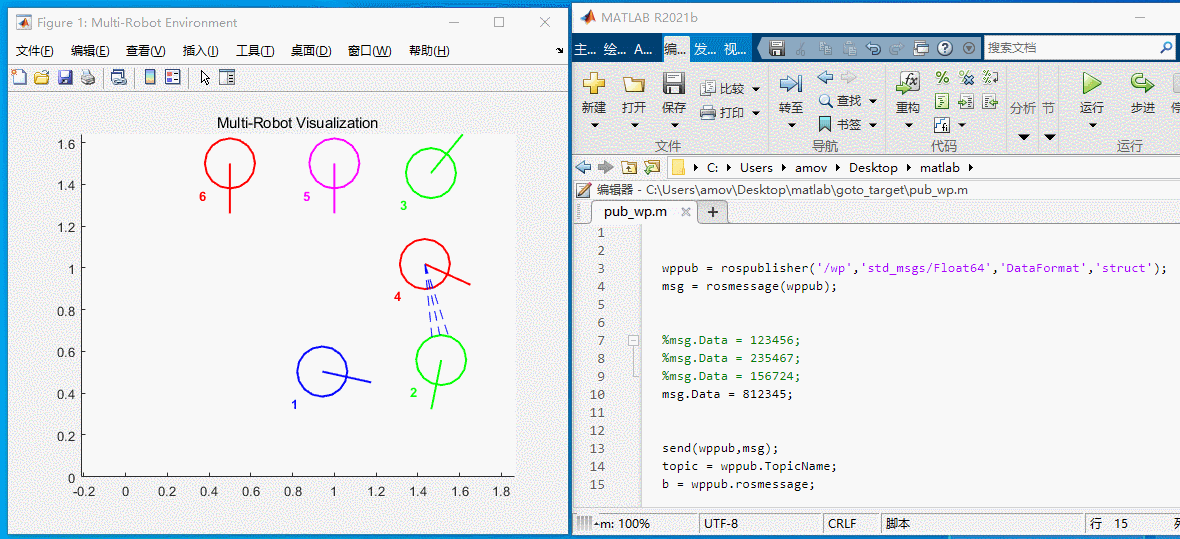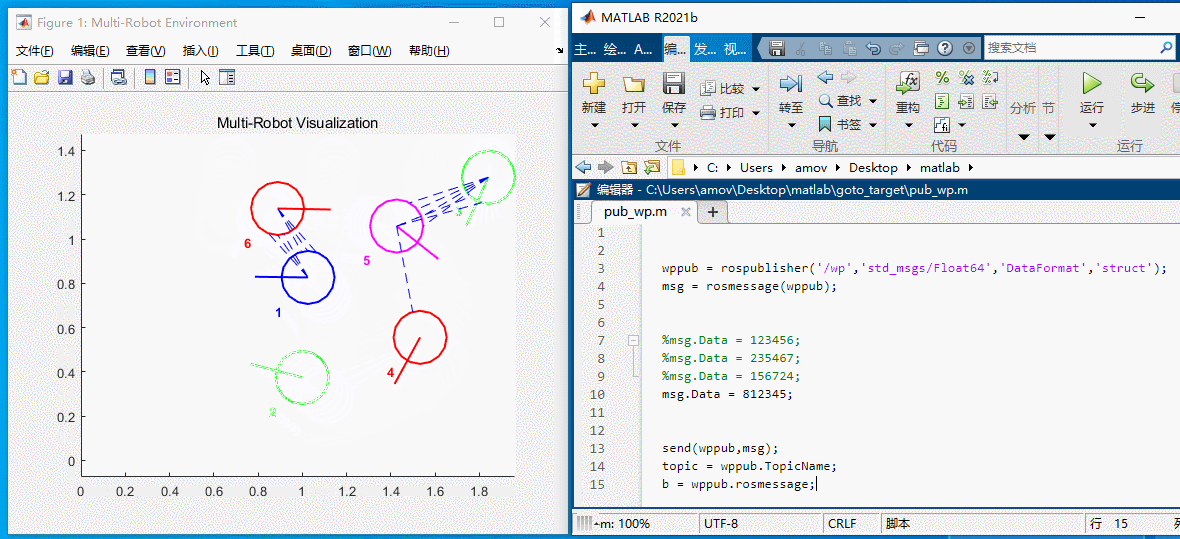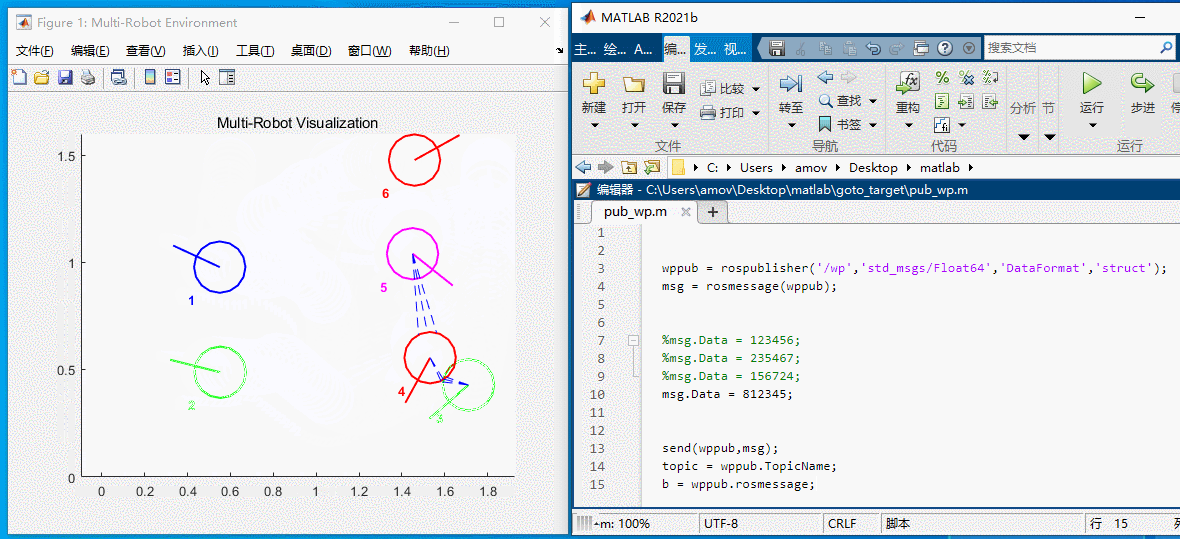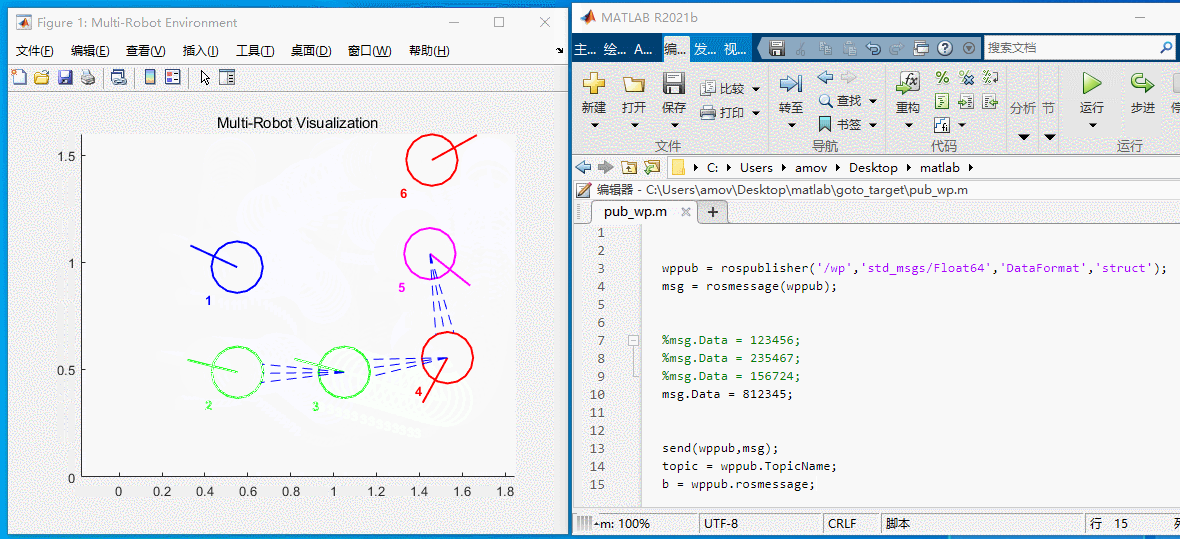
图8 812345
一键生成ROS代码
- 首先在
b6_goto_target.slx文件中开发,完成想要的仿真效果,然后保存 - 打开
c6_goto_target.slx文件,将b6_goto_target.slx文件中开发的部分同等在c6_goto_target.slx文件中修改。
注意
- 该功能不建议直接复制
- 建议用户直接使用提供的模板
c6_goto_target.slx进行二次开发- 有关matlab开发文件说明,详见matlab文件说明
- 在编译代码之前,确保启动了
rosinit - 然后在菜单栏上的
ROS--Deploy to Remote Device。如图1所示
图1 生成ROS代码配置
- 然后点击菜单栏上的
ROS--Build Model--Build Model一键生成ROS代码,如图2所示
图2 生成ROS代码
-
等待编译完成以后,将会看到生成的压缩包文件
-
将生成的 ROS 代码复制到Linux系统中,并解压至
kk-robot-swarm/src/swarm/下,然后编译整个工作空间即可。
贪吃蛇仿真
本教程将会引导读者完成 贪吃蛇仿真 的演示。在使用此功能之前,确保已经完成了 仿真系统搭建
- 打开matlabR20021b,在命令行中输入
rosinit,启动ROS Master节点
rosinit
此时将会弹出ROS master 的窗口,不要关闭。最小化即可。 如图1所示:
图1 rosinit
提示
在某些电脑环境中,即使按照仿真系统搭建步骤完成搭建,在运行
rosinit时,可能会出现Cannot connect to ROS master at http://localhost:11311. Check the specified address or hostname字样。解决的办法是,将
rosinit命令改为,rosinit("ip",端口)。如下图所示:解决办法
- 打开
kk-robot-swarm/src/matlab/snakes/b10_wp_snake.slx文件,如图2所示。
图2 b10_snake
- 点击菜单栏上的
ROS--Deplay to Localhost。如图3所示
图3 仿真运行
注意
在启动仿真运行之前,确保
init_b10.m文件和b10_wp_snake.slx文件在 同一路径下否则运行程序将会报错
- 等待编译完成,系统将会运行仿真。如图4所示:
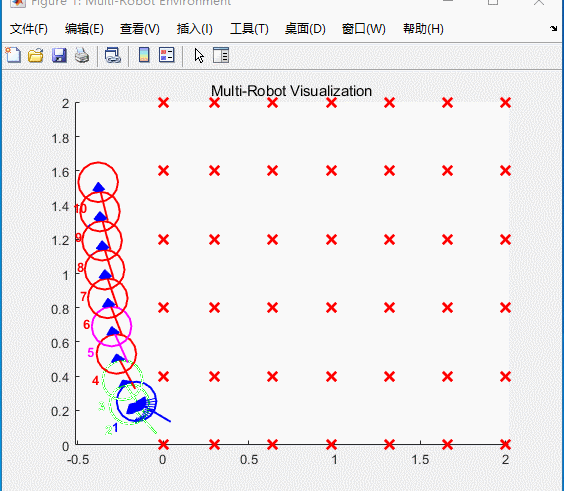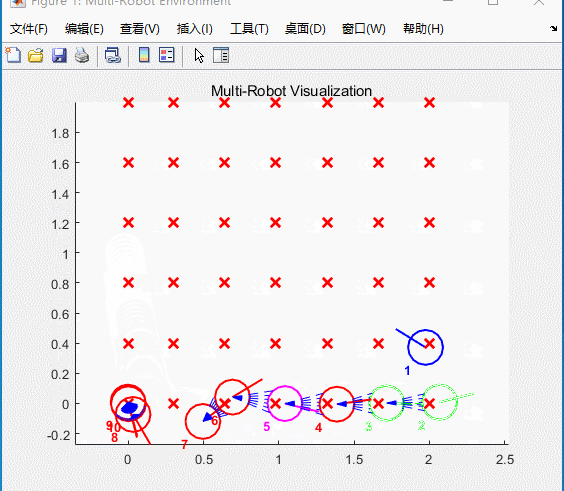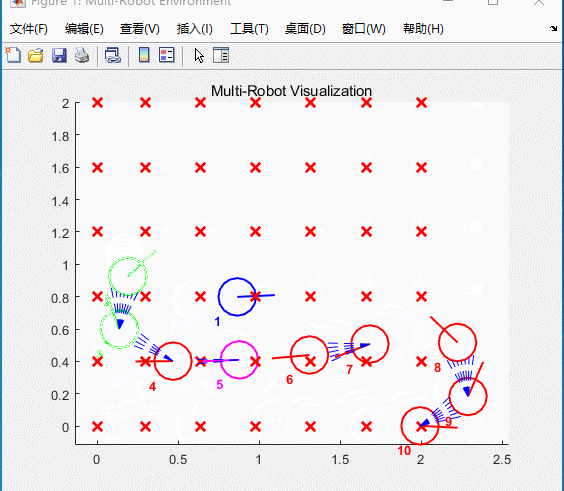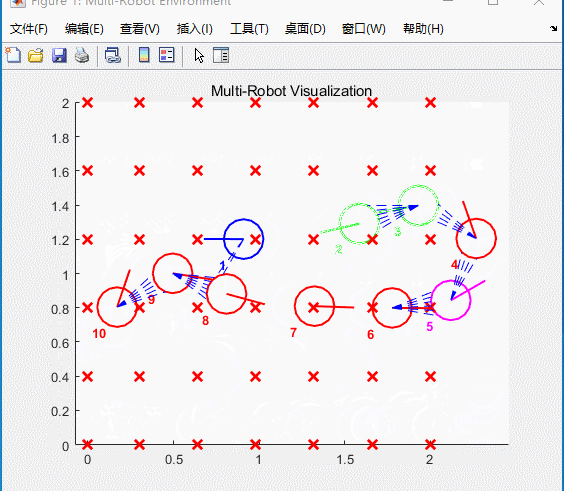
图5 仿真结果
小车将会按照航点依次运动,类似“贪吃蛇”
一键生成ROS代码
- 首先在
b10_wp_snake.slx文件中开发,完成想要的仿真效果,然后保存 - 打开
c10_wp_snake.slx文件,将b10_wp_snake.slx文件中开发的部分同等在c10_wp_snake.slx文件中修改。
注意
- 该功能不建议直接复制
- 建议用户直接使用提供的模板
c10_wp_snake.slx进行二次开发- 有关matlab开发文件说明,详见matlab文件说明
- 在编译代码之前,确保启动了
rosinit - 然后在菜单栏上的
ROS--Deploy to Remote Device。如图1所示
图1 生成ROS代码配置
- 然后点击菜单栏上的
ROS--Build Model--Build Model一键生成ROS代码,如图2所示
图2 生成ROS代码
-
等待编译完成以后,将会看到生成的压缩包文件
-
将生成的 ROS 代码复制到Linux系统中,并解压至
kk-robot-swarm/src/swarm/下,然后编译整个工作空间即可。
队形变换仿真
本教程将会引导读者完成 队形变换仿真 的演示。在使用此功能之前,确保已经完成了 仿真系统搭建
- 打开matlabR20021b,在命令行中输入
rosinit,启动ROS Master节点
rosinit
此时将会弹出ROS master 的窗口,不要关闭。最小化即可。 如图1所示:
图1 rosinit
提示
在某些电脑环境中,即使按照仿真系统搭建步骤完成搭建,在运行
rosinit时,可能会出现Cannot connect to ROS master at http://localhost:11311. Check the specified address or hostname字样。解决的办法是,将
rosinit命令改为,rosinit("ip",端口)。如下图所示:解决办法
- 打开
kk-robot-swarm/src/matlab/formation/b6_formation.slx文件,如图2所示。
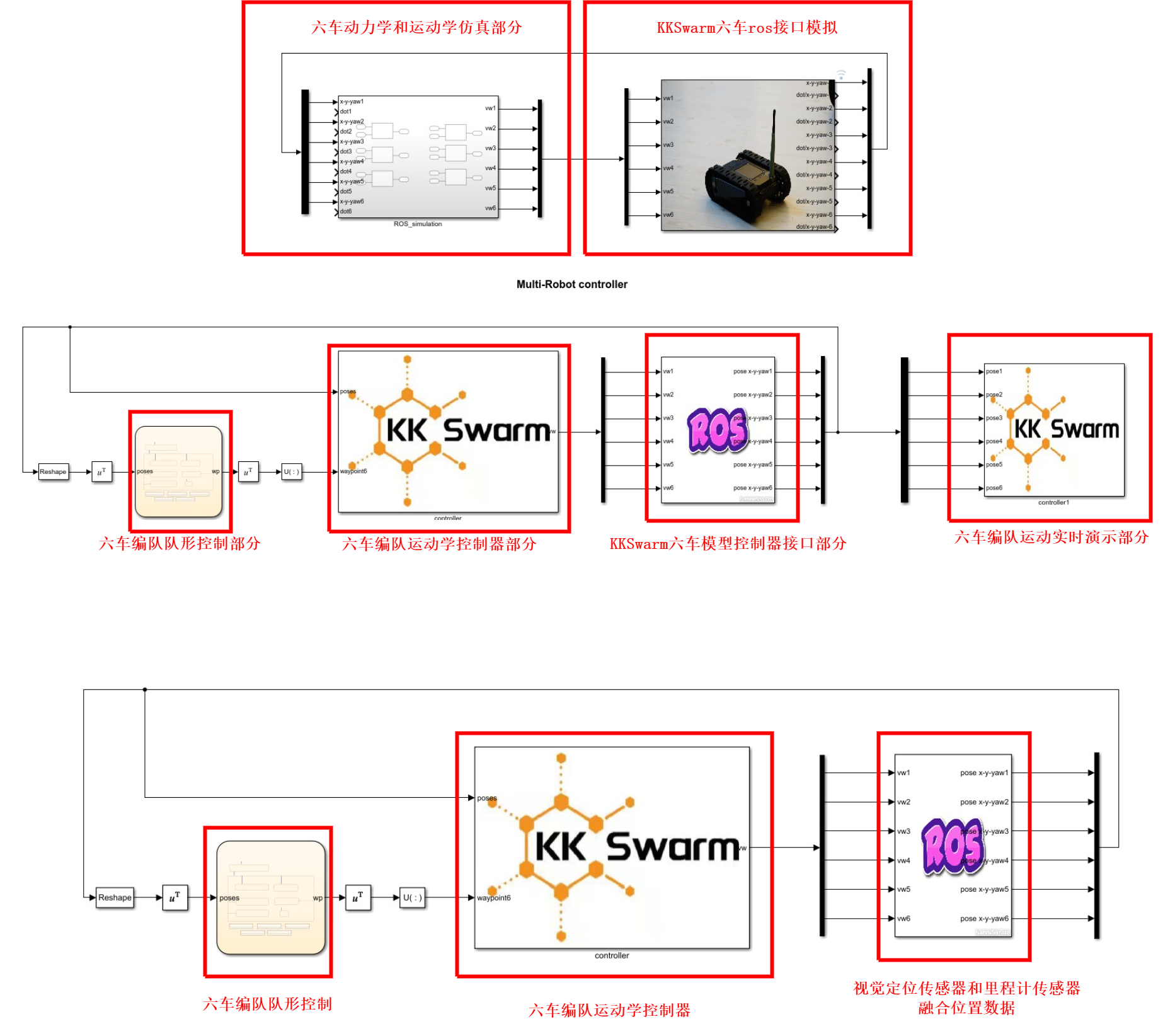
图2 b6_formation
- 接着点击菜单栏上的
仿真--运行。启动仿真
图4 b6_formation Sim
- 等待编译完成,系统将会运行仿真。如图4所示:
图5 仿真结果
集群将会按照给定的队形进行循环变化
二次开发参数说明
此 Demo 采用的是 simulink 的 stateflow 来进行多车编队的队形切换。其主要控制模块如下:
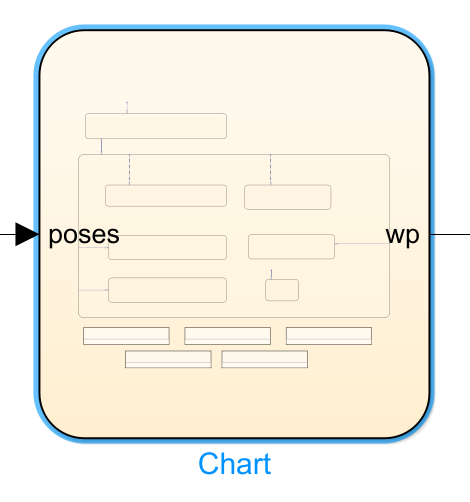
主要控制模块
双击进入以后,可以看到队形切换的逻辑。如下图所示:
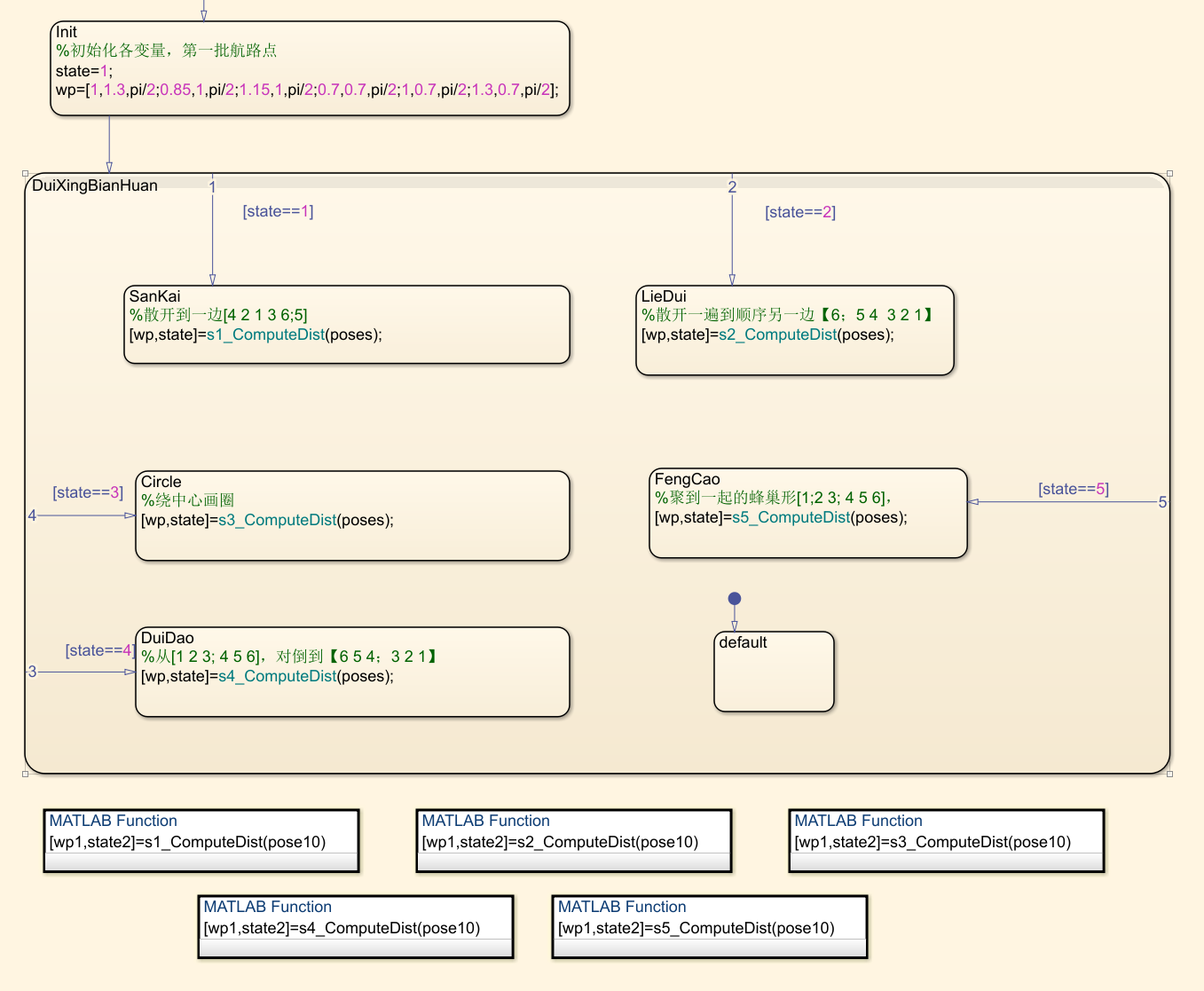
控制逻辑图
整体规划了5种队形,分别对应状态 state==1~5。 Statefow 按照状态顺序每个采样周期执行一个状态,在每个状态中会调用该状态的对应队形的航路点生成函数,这样每个采样周期都会更新一次航路点,如何到达航路点由运动学控制器负责解算,航路点生成函数负责解算当前航路点状态是否完成,完成就给出下一个航路点或者切换到下一个状态。
这种状态转移架构可以很方便进行线性扩充。详细算法参见各个航路点生成函数 [wp,state]=sn_ComputeDist(poses) 模块
一键生成ROS代码
- 首先在
b6_formation.slx文件中开发,完成想要的仿真效果,然后保存 - 打开
c6_formation.slx文件,将b6_formation.slx文件中开发的部分同等在c6_formation.slx文件中修改。
注意
- 该功能不建议直接复制
- 建议用户直接使用提供的模板
c6_formation.slx进行二次开发- 有关matlab开发文件说明,详见matlab文件说明
- 在编译代码之前,确保启动了
rosinit - 然后在菜单栏上的
ROS--Deploy to Remote Device。如图1所示
图3 生成ROS代码配置
- 然后点击菜单栏上的
ROS--Build Model--Build Model一键生成ROS代码,如图2所示
图3 生成ROS代码
-
等待编译完成以后,将会看到生成的压缩包文件
-
将生成的 ROS 代码复制到Linux系统中,并解压至
kk-robot-swarm/src/swarm/下,然后编译整个工作空间即可。
算法原理综述
基于深度强化学习的跟车策略学习方法
一、强化学习基本原理
1.1 什么是强化学习
强化学习旨在学习如何做,即如何根据情况采取动作,从而实现数值奖励信号最大化。学习者不会接到动作指令,而是必须自行尝试发现回报最高的动作方案。
—Sutton and Barto,强化学习导论
1.2 强化学习与传统控制的关系
强化学习 (RL) 已成功地训练计算机程序在游戏中击败全球最厉害的人类玩家。在状态和动作空间较大、环境信息不完善并且短期动作的长期回报不确定的游戏中,这些程序可以找出最佳动作。
图1-1 人机大战
在为真实系统设计控制器的过程中,工程师面临同样的挑战,如控制机器人走路或自动驾驶汽车。

图1-2 机器人走路

图1-3 自动驾驶
1.2.1 控制目标
从广义上而言,控制系统的目标是确定正确的系统输入(动作),从而生成期望的系统行为。在反馈控制系统中,控制器使用状态观测提高性能并修正随机干扰。工程师描述被控对象和环境模型,运用反馈信号,设计控制器,从而满足系统需求。以上概念表述十分简单;然而,倘若系统难以建模、高度非线性或者状态和动作空间较大,则很难实现控制目标。
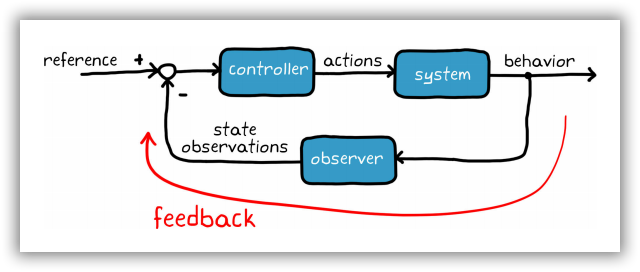
图1-4 传统的控制器设计示意图
1.2.2 控制问题
为了理解此类难题对控制设计问题造成的进一步后果,不妨设想一下开发步行机器人控制系统的场景。要控制机器人(即系统),可能需要命令数十台电机操控四肢的各个关节。每一项命令是一个可执行的动作。系统状态观测量有多种来源,包括摄像机视觉传感器、加速度计、陀螺仪及各电机的编码器。
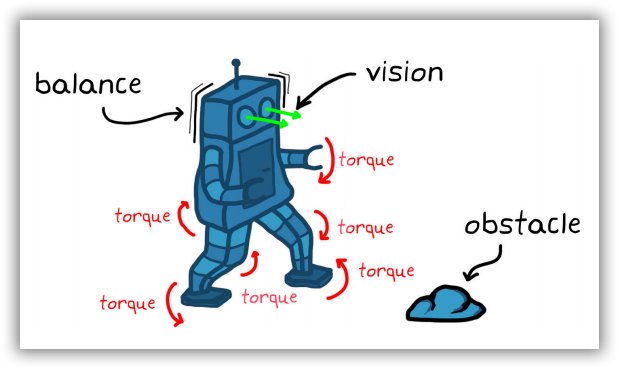
图1-5 行走机器人的控制问题
控制器必须满足多项要求:
• 确定适当的电机扭矩组合,确保机器人正常步行并保持躯体平衡。
• 需要在避开多种随机障碍物的环境下操作。
• 抗干扰,如阵风。
控制系统设计不仅要满足上述要求,还需满足其他附加条件,比如在陡峭的山坡或冰块上行走时保持平衡。
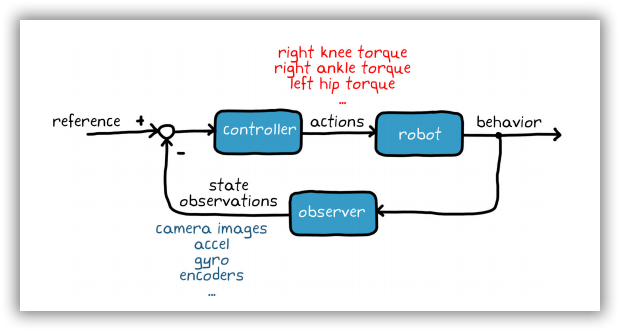
图1-6 行走机器人控制器需要考虑的问题
1.2.3 传统的控制方案
通常,解决此类问题的最佳方法是将问题分解成为若干部分,逐个击破。
如图1-7所示,我们可以构建一个提取摄像机图像特征的流程。例如,障碍物的位置和类型,或者机器人在全局参照系中所处的位置。综合运用这些状态与其他传感器传回的处理后的观测值,完成全状态估测。 估算的状态值和参考值将反馈给控制器,其中很可能包含多个嵌套控制回路。外部环路负责管理高级机器人行为(如保持平衡),内部环路用于管理低级行为和各个作动器。
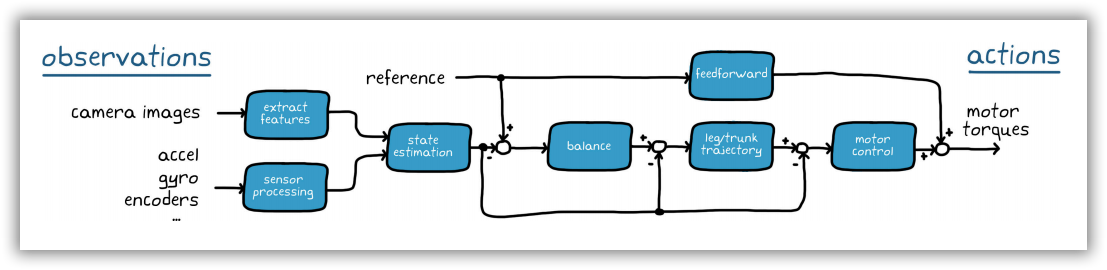
图1-7 行走机器人的控制器设计方案
这种控制方案要求各环路之间相互交互,使得设计和调优变得异常困难。同时,确定最佳的环路构造和问题分解也并不轻松。
1.2.4 强化学习的控制方案
如果不是尝试单独设计每一个组件,而是设想一下将其全部塞进一个函数里, 由该函数负责接收所有观察结果并直接输出低级动作。 毋庸置疑,这可以简化系统方块图,但这个函数会是怎样的结构?我们该如何设计这个函数呢?创建一个单一的大函数比构建由分段子组件构成的控制系统,看起来难度要大;不过,强化学习可以帮助我们达成目标。
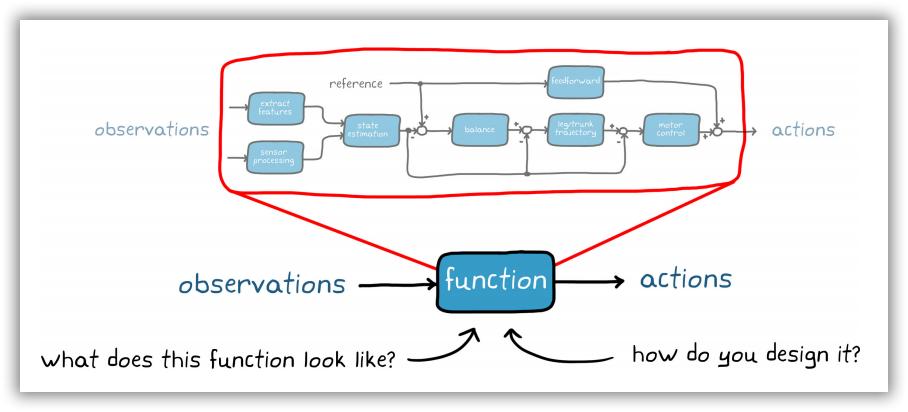
图1-8 基于强化学习的行走机器人控制器设计方案
1.3 强化学习的基本原理与流程
1.3.1 强化学习的基本原理
与传统监督学习与无监督学习不同,强化学习采用动态环境数据,其目标并不是对数据进行分类或标注,而是确定生成最优结果的最佳动作序列,通过一个所谓的智能体(agent)来探索环境、与环境交互并从环境中学习。
智能体中有一个函数可接收状态观测量(输入),并将其映射到动作集(输出)。也就是前面提到过的单一函数,它将取代控制系统的所有独立子组件。在RL 命名法中,此函数称之为策略。策略根据一组给定的观测量决定要采取的动作。
以步行机器人为例,观察结果是指每个关节的角度、机器人躯干的加速度和角速度,以及视觉传感器采集的成千上万个像素点。策略将根据所有这些观测量,输出电机指令,使机器人移动四肢。随后,环境将生成奖励,向代理反映特定作动器指令组合的效果。如果机器人能够保持直立并继续行走,对应的奖励则将高于机器人摔倒时的奖励。
如果可以设计出一项完美的策略,针对观察到的每一种状态向适当的作动器发出适当的指令,那么目标就达成了。因此,强化学习算法应运而生。它可以根据已采取的动作、环境状态观测量以及获得的奖励值来改变策略。智能体的目标是使用强化学习算法学习最佳环境交互策略;这样一来,无论在任何状态下,智能体都能始终采取最优动作——即长期奖励最丰厚的动作。
强化学习的目标与控制问题相似,只不过方法不同,使用不同的术语表示相同的概念。 通过这两种方法,我们希望确定正确的系统输入,从而让系统产生期望的行为。 我们的目的在于判断如何设计策略(或控制器),从而将环境(或被控对象)的状态观测量映射到最佳动作(作动器指令)。 状态反馈信号是指环境观察结果,参考信号则内置到奖励函数和环境观测量中。
1.3.2 强化学习的基本流程
如图1-9所示,强化学习一般涉及到五个步骤,分别是建立环境,设计奖励信号,研究策略表示方法、设计训练算法,验证部署。其中,我们需要一个环境,供智能体开展学习,需要选择环境里应该有什么,是虚拟的仿真环境还是真实的物理环境; 需要考虑最终想要智能体做什么工作,并设计奖励函数, 激励智能体实现目标;需要选择一种表示策略的方法,思考如何构造参数和逻辑,由此构成智能体的决策部分;需要选择一种算法来训练智能体,争取找到最优的策略参数;需要在实地部署该策略并验证结果, 从而利用该策略。
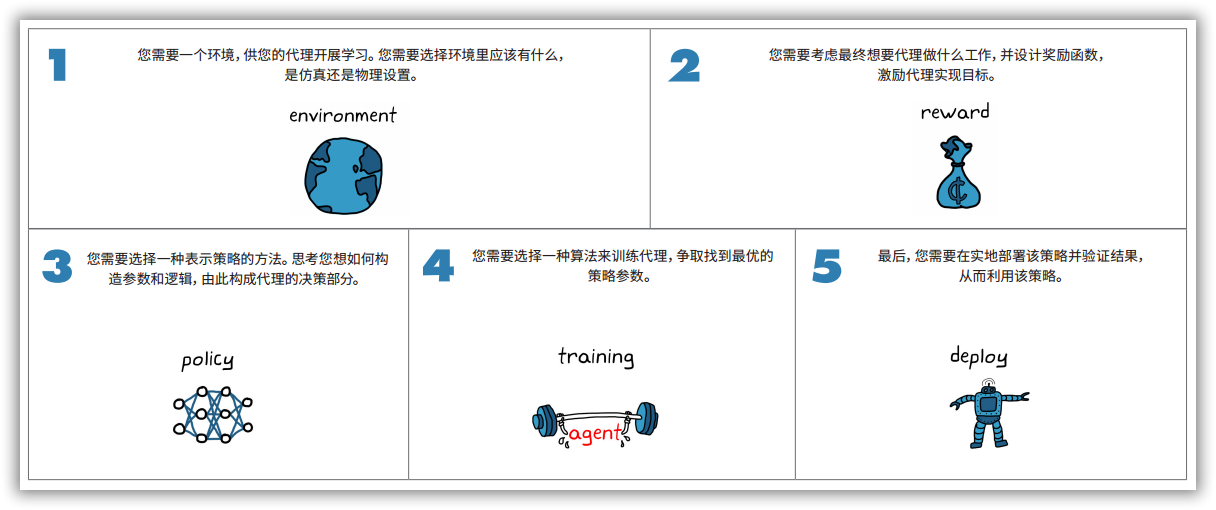
图1-9 强化学习的基本流程
二、跟车问题描述
跟车问题是指通过控制车辆自身的转向角度和速度,与领头车保持一定的安全距离,跟随领头车行驶。跟车问题在学术领域被称为路径跟随问题,目前该问题有很多解决方法,如模型预测控制方法,感兴趣的朋友可以参考软件Matlab提供的路径跟随控制系统。在这里,我们采用当前人工智能最为流行的深度强化学习方法来解决该问题。
2.1 马尔科夫决策过程
针对路径跟随问题,可以采用马尔科夫决策过程进行描述,即用四元组$E=<S,A,P,R>$,$E$为当前的路径跟随环境,$S$为路径跟随小车观测外部环境的状态空间,$A$为路径跟随小车的动作空间,$P$为状态转移函数,$R$为奖励函数。在某一时刻$t$,路径跟随小车agent观测外部环境的状态记为$s_t$,根据所学习的跟车策略$\pi(s_t)$输出动作$a_t$,并从外部环境获取即时奖励$r_t=R(s_t,a_t)$。
如图2-1所示,给出了路径跟随示意图。其中,领头车为蓝色小车,跟随车为黄色小车,$e_1$、$e_2$为领头车与跟随车的横向偏移距离和纵向偏移距离,$d_{rel}$为领头车与跟随车的偏移距离,$\theta_{yaw1}$、$\theta_{yaw2}$为领头车和跟随车的绝对航向角(与$x$轴的夹角,按逆时针旋转为正方向)。跟随车需要与领头车保持一定的纵向偏移距离和速度,同时横向偏移距离不能过大,才能保证较好的路径跟随效果。

图2-1 路径跟随示意图
2.2 状态空间设计
在状态空间设计中,我们认为领头车与跟随车的相对位置$(\Delta{x},\Delta{y})$、相对航向角$\Delta{\theta}$、横向偏移距离$e_1$、纵向偏移距离$e_2$、跟随车的线速度$V_{ego}$以及参考速度$V_{ref}$与线速度之差$e_V$、横向偏移距离变化率$\dot{e}1$和相对航向角变化率${\Delta}\dot{\theta}$,这些因素都会对路径跟随效果有一定影响。其中,跟随车的参考速度$V{ref}$主要根据领头车的线速度$V_{lead}$、预设的跟随车线速度$V_{set}$以及领头车与跟随车的安全距离$d_{safe}$进行计算,而将安全距离$d_{safe}$定义成与跟随车线速度有关的线性函数,即$d_{safe}=t_{gap}*V_{ego}+d_{default}$,$t_{gap}$、$d_{default}$分别为常量。当$d_{safe}-d_{rel}>0$时,取领头车线速度和跟随车预设线速度的最小值,反之,取随车预设得线速度,故跟随车的参考速度$V_{ref}$可以看成是领头车与跟随车的安全距离$d_{safe}$的映射函数。 $$ V_{ref}=\left{\begin{array}{}min(V_{lead},V_{set}) & d_{safe}-d_{rel}>0\V_{set}, & d_{safe}-d_{rel}{\leq}0\end{array}\right. $$
由此,跟随车的状态空间可采用九元组进行表示,即$<\Delta{x},\Delta{y},\Delta{\theta},V_{ego},e_V,e_1,e_2,\dot{e}_1,{\Delta}\dot{\theta}>$
2.3 奖励函数设计
在强化学习算法中,奖励函数设计是极其重要的一环,它可以将任务目标具体化、数值化,奖励函数设计的好坏直接体现了其对任务逻辑的理解深度,决定了智能体最终能否学到期望的行为策略,从而影响算法的收敛速度和最终性能。
为了保证较好的路径跟随效果,需要对以下几个方面进行考虑:
- 跟随车的参考速度$V_{ref}$与线速度$V_ego$之差$e_v$不能太大;
- 领头车与跟随车的横向漂移距离$e_1$不能太大;
- 跟随车上一次角速度$w_{t-1}$和线速度$v_{t-1}$控制量幅度不能太大;
- 领头车与跟随车的横向和纵向漂移距离较大时,将受到惩罚。
根据上述情况,路径跟随的奖励函数设计为:
$r_t=-0.1e_v^2-0.1e_1^2-0.1\omega_{t-1}^2-0.5v_{t-1}-10F_t+M_t+2H_t$
其中,$e_v$为前车与后车的纵向速度差(m/s),$e_v=V_{ref}-V_{ego}$;当领头车与跟随车的横向和纵向漂移距离较大时,$F_t=1$,否则,$F_t=0$;当$e_v^2<1$时,$M_t=1$,否则,$M_t=0$;当$e_1^2<0.01$时,$H_t=1$,否则,$H_t=0$;
2.4 动作空间设计
在路径跟随环境中,车辆采用的是双轮差速模型,其控制变量主要有线速度和角速度。为保证车辆控制的平滑性和稳定性,将线速度和角速度按照连续动作进行设计。
三、跟车仿真环境搭建
详见 仿真系统搭建
3.2 基于Simulink的跟车仿真环境
3.2.1 车辆模型
在路径跟随环境中,领头车和跟随车的运动模型将采用Matlab提供的双轮差速模型,该模型主要模拟位置矢量$q=[x,y,\theta]^T$、运动速度矢量$u=[v,w]^T$($w$为瞬时角速度、$v$为瞬时线速度),两个矢量的关系如下式所示。 $$ \dot{q}=S\cdot{u} $$ 其中,$S=\left[ \begin{array}{l} cos\theta & 0 \ sin\theta & 0 \ 0 & 1 \end{array} \right]$。该模型的输入为运动速度矢量(线速度与角速度),输出为位置矢量,可以根据速度的变化得到小车模型下一时刻的位置。
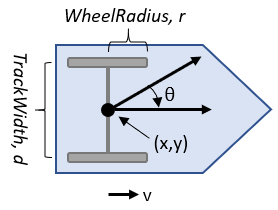
图3-23 双轮差速模型
关于车辆模型,Matlab提供了基本参数:
- 车轮半径wheel radius:车轮的半径将影响运动时的速度与位置关系,默认为0.05;
- 车轮速度范围wheel speed range:线速度和角速度的范围,默认为负无穷到正无穷;
- 轮距track width:两轮之间的距离,默认为0.2;
- 控制方式vehicle inputs:matlab提供了两种,一是Wheel Speeds,即输入左右轮的速度;二是Vehicle Speed Heading Rate,即输入线速度和角速度。
3.2.2 领头车机动控制模型
Matlab除了提供3.2.1节所述的双轮差速模型,还提供了controller Pure Pursuit控制器,该控制器能够实现车辆按照预设的航路点运动。如图3-24所示,根据路径跟随环境的需要,在指定区域设置四个航路点,领头车将沿着四个航路点循环往复运动,跟随车将按照领头车的运动轨迹跟随。
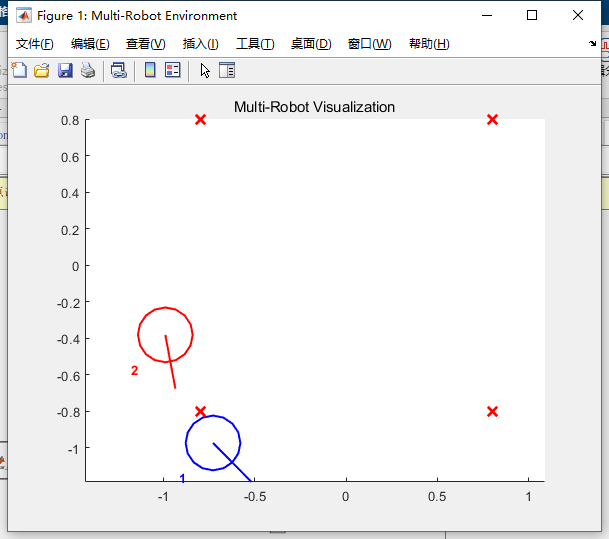
图3-24 领头车的四个航路点
3.2.3 跟车的状态输入、奖励计算与动作输出
3.2.3.1 状态输入
根据3.2节的状态空间设计,提供强化学习算法所需要的状态输入,示例代码如下:
function observation = get_obs(x1,x2,y1,y2,lateral_rel_dist, longitudinal_rel_dist,
yaw1, yaw2, leader_linear_vel, ego_linear_vel, ...
yaw_delta_former, lateral_rel_dist_former)
% 状态空间
% 输入
% longitudinal_rel_dist 领头车与跟随车的纵向相对距离
% lateral_rel_dist 领头车与跟随车的横向相对距离
% yaw_delta 领头车与跟随车的航向角偏差
% ego_linear_vel 跟随车的线速度
% e_v 跟随车的参考速度与线速度之差
% lateral_rel_dist_dot 领头车与跟随车的横向相对距离变化率
% yaw_delta_dot 领头车与跟随车的航向角偏差变化率
% 计算领头车与跟随车的相对位置
x_delta = x1 - x2;
y_delta = y1 - y2;
% 计算领头车与跟随车的绝对航向角之差
yaw_delta = yaw1-yaw2;
% 计算跟随车的横向偏移距离变化率和相对航向角变化率
lateral_rel_dist_dot = lateral_rel_dist - lateral_rel_dist_former;
yaw_delta_dot = yaw_delta - yaw_delta_former;
% 计算跟随车的参考速度与线速度之差
v_ref = get_ref_velocity(leader_linear_vel, ...
ego_linear_vel, longitudinal_rel_dist);
e_v = v_ref - ego_linear_vel;
observation = [x_delta, y_delta, longitudinal_rel_dist,e_v, ego_linear_vel, ...
lateral_rel_dist, lateral_rel_dist_dot, yaw_delta, yaw_delta_dot];
end
3.2.3.2 奖励计算
根据3.3节的奖励函数设计,计算跟随车在跟随过程中的即时奖励,示例代码如下:
function reward = reward_calc(e_v, lateral_rel_dist, ego_linear_vel,... ego_omega_vel, last_ego_omega_vel, isDone)
% e_v 跟随车参考速度与线速度之差
% lateral_rel_dist 领头车与跟随车的横向相对距离
% ego_linear_vel 跟随车的线速度
% ego_omega_vel 跟随车的角速度
% last_ego_omega_vel 跟随车上一次的角速度
% isDone 判断仿真是否终止 0表示仿真继续 1表示仿真终止
F_t = 0.0;
M_t = 0.0;
H_t = 0.0;
delta_omega = 0.0;
e_v_square = e_v * e_v;
lateral_rel_dist_square = lateral_rel_dist * lateral_rel_dist;
if isDone==1
F_t = 1.0;
end
if e_v_square < 1.0
M_t = 1.0;
end
if lateral_rel_dist_square<0.01
H_t = 1.0;
end
if sim_step >= 2
delta_omega = ego_omega_vel - last_ego_omega_vel;
end
reward = -0.1*e_v_square - 0.1*ego_linear_vel*ego_linear_vel- ... 0.1*lateral_rel_dist_square - 0.5*ego_omega_vel*ego_omega_vel -...
0.4*delta_omega*delta_omega - 10.0*F_t + M_t + + 2.0*H_t;
end
3.2.3.3 动作输出
在路径跟随环境中,跟随车的线速度控制在0.15-0.25m/s范围内,角速度控制在-1.0~1.0rad/s范围内,强化学习算法采用连续类型的控制量控制跟随车运动。如图所示,给出了跟随车的线速度和角速度的限幅范围。
3.2.4 仿真环境终止条件
当出现以下三种情况时,仿真将终止:
-
跟随车与领头车发生碰撞
-
跟随车与领头车的横向偏移距离超出阈值
-
跟随车与领头车的纵向偏移距离超出阈值
其示例代码如下:
function flag = EnvisDone(rel_dist, lateral_rel_dist, longitudinal_rel_dist, ego_linear_vel)
% avoid_dist 领头车与跟随车的碰撞距离
% max_lateral_rel_dist 跟车的横向最大偏移距离
% max_longitudinal_rel_dist 跟车的纵向最大偏移距离
flag = 0;
avoid_dist = 0.3;
min_ego_linear_vel = 0.12;
max_lateral_rel_dist= 0.7;
max_longitudinal_rel_dist = 1.0;
if rel_dist <= avoid_dist
flag = 1;
end
if longitudinal_rel_dist >= max_longitudinal_rel_dist
flag = 1;
end
if abs(lateral_rel_dist) >= max_lateral_rel_dist
flag = 1;
end
end
如图3-25所示,我们在Simulink仿真环境中创建了领头车、跟随车、信号处理模块。其中,领头车的信号处理模块主要负责其运动控制,即绕四个航路点循环往复运动;跟随车的信号处理模块主要负责为强化学习算法提供输入,如状态值、奖励值和仿真结束条件等。
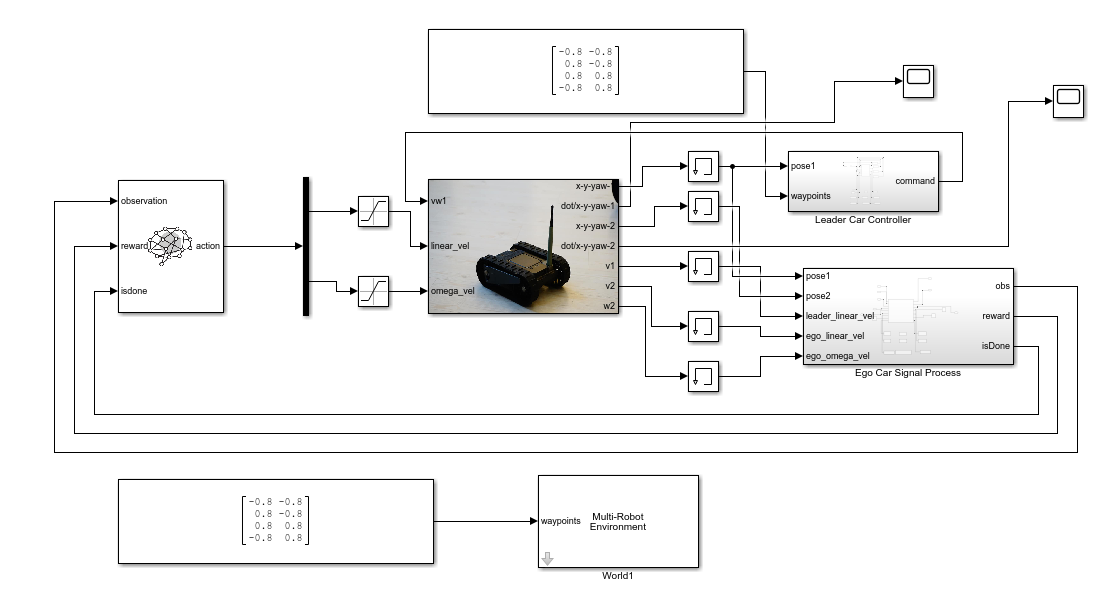
图3-25 基于Simulink的路径跟随环境
四、跟车控制器训练与部署
在Matlab软件的Reinforcement Learning Toolbox™中, 提供了DQN、PPO、SAC 、DDPG和TD3 等经典的强化学习算法,结合这些算法进行策略训练,可以为复杂应用(如资源分配、机器人和自主系统)实现控制器和决策算法。其中,TD3算法是解决连续动作空间的一类强化学习算法,在路径跟随问题中,车辆的控制量(线速度和角速度)也是连续值,符合TD3算法应用的条件。
4.1 TD3训练算法
TD3算法被称为双重延迟深度确定性策略梯度(Twin Delayed Deep Deterministic Policy Gradient,TD3),它是在深度确定性策略梯度(DDPG)算法发展而来的。
4.1.1 网络结构
如图4-1所示,TD3算法的网络结构有6个。其中,Actor网络输入是状态,输出是动作。Critic网络输入是状态和动作,输出是对应的$Q$值。Actor网络的目的是根据状态 $s_t$ ,能够输出使得$Q(s_t,a_t)$最大的动作$a_t$,这个$a_t$越能使$Q(s_t,a_t)$大,就说明网络训练地越好。Critic网络的目的是根据状态动作对$(s_t,a_t)$能够输出其动作值$Q(s_t,a_t)$ ,这个$Q$值越精确,就说明网络训练地越好。
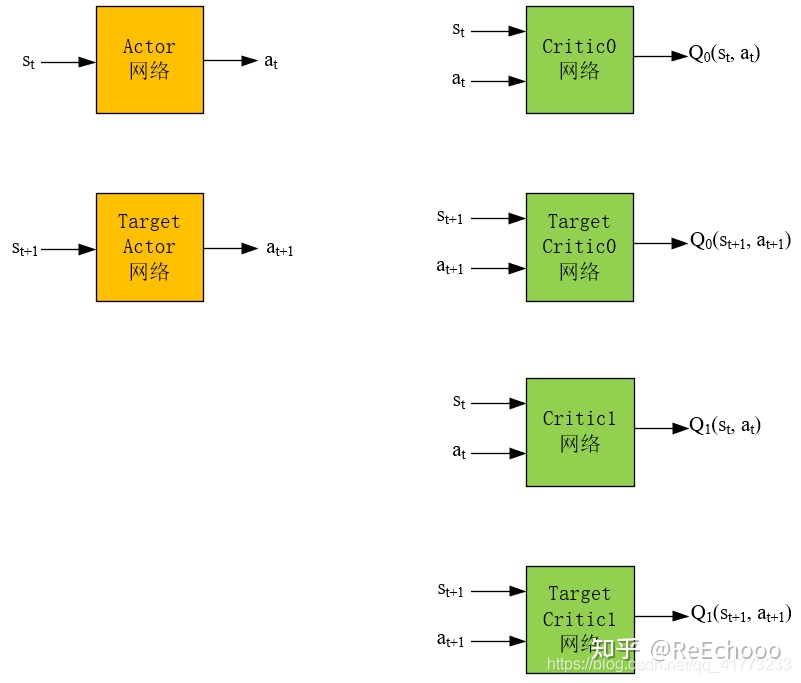
图4-1 TD3算法的网络结构
Actor网络和Target Actor网络的区别是,Actor网络是每步都会在经验池中更新,而Target Actor网络是隔一段时间将Actor的网络参数拷贝到Target Actor网络中,实现Target Actor网络的更新。这种“滞后”更新是为了保证在训练Actor网络时训练的稳定性。同样,Critic网络和Target Critic网络也是为了保证在训练Actor网络时训练的稳定性。
4.1.2 产生经验数据的过程
已知一个状态$s_0$,通过 actor网络得到动作$a'_0$ ,然后再加噪声$N$得到动作$a_0=a'_0+N$ (噪声是为了保证一定的探索,普通的高斯噪声即可),然后将$a_0$输入到环境中,得到$s_1$和$r_1$,这样就得到一个经验数据$(s_0,a_0,s_1,r_1)$ ,然后将经验数据放入经验池中。
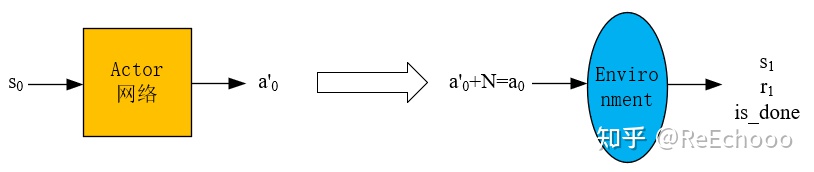
图4-2 Actor网络产生经验数据的过程
经验池 存在的意义是为了消除经验数据的相关性,因为强化学习中前后动作通常是强相关的,将其打散放入经验池中,在训练神经网络时,随机地从经验池中选出一批经验数据,这样能够使神经网络训练地更好。
4.1.3 Actor网络的更新过程
如图4-3所示,Actor网络的损失函数就是$-Q$,$-Q$越小越好,这个$-Q$则由Critic0网络得到。以经验数据$(s_0,a_0,s_1,r_1)$ 为例,将$s_0$输入到Actor网络中,得到预测的动作$a_{0_predict}$,直接将$s_0$和$a_{0_predict}$输入到Critic0网络中,得到$Q$值,然后将$-Q$作为损失函数,修正Actor网络。

图4-3 Actor网络的更新过程
值得注意的是,Actor网络是最重要的,因为它直接决定了智能体采取策略的好坏。想要训练出一个好的Actor网络,需要一个准确的Critic网络来评价它,因此 TD3的剩下5个网络 都是 为了创造 出一个 尽可能精确的Critic网络。
4.1.4 Critic网络的更新过程
Target Actor网络的目的是为了让Critic网络更容易稳定收敛,如果用频繁更新的Actor网络做下一步动作的预测,会导致Critic网络很难收敛, Target Critic网络的目的 与Target Actor网络的目的相同,也是想用一个更新不频繁的网络让Critic网络稳定收敛。
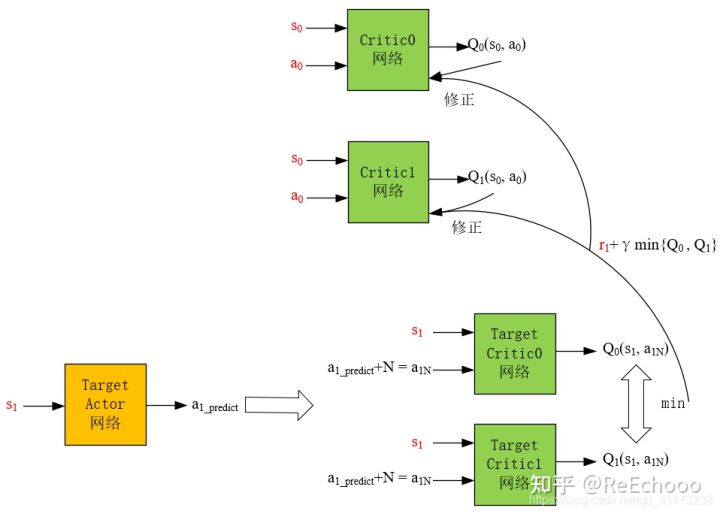
图4-4 Critic网络的更新过程
考虑到在实际的应用中,Critic网络总是过高的估计$Q$值,TD3算法采用两个网络对Q值进行估计,然后选择较小的那个,这样尽可能地 避免过高地估计$Q$值。为此,频繁更新的Critic网络也需要采用两个,用$r_{1}+\gamma * \min \left{Q_{0}\left(s_{1}, a_{1 N}\right), Q_{1}\left(s_{1}, a_{1 N}\right)\right}$来更新两个Critic网络,即用$r_{1}+\gamma * \min \left{Q_{0}\left(s_{1}, a_{1 N}\right), Q_{1}\left(s_{1}, a_{1 N}\right)\right}$分别与$Q_0(s_0,a_0)$和$Q_1(s_0,a_0)$做均方差,然后作为损失值对Critic网络进行梯度下降。
此外,为了鼓励智能体探索, 给Target Actor网络的预测动作**$a_{1_predict}$ **加了一个噪声$N$ ,变为动作$a_{1N}$ 之后,才作为两个Target Critic网络的输入,使得下一步的$Q$值更精确。
4.1.5 TD3算法的优点
一是 将一个Target Critic网络变为两个Target Critic网络,取两者较小的作为下一状态的Q值,从而避免Q值过高地被估计。
二是 对Target Actor 网络的输出进行了加噪声处理,从而使得Target Critic网络的预测输出Q值尽可能精确。
三是 采用了延迟软更新的方式去更新一个Target Actor 网络、两个Target Critic网络,以及采用延迟更新的方式更新Actor网络。
4.2 创建智能体
根据4.1节TD3算法的网络结构,在matlab脚本文件中创建相关的智能体,示例代码如下:
function agent = createPFCAgent(obsInfo,actInfo)
% obsInfo 状态空间信息
% actInfor 动作空间信息
% 获取状态空间和动作空间的维数
numObs = obsInfo.Dimension(1);
numAct = 2;
% 定义Critic网络
statePath1 = [
featureInputLayer(numObs,'Normalization','none','Name','observation')
fullyConnectedLayer(400,'Name','CriticStateFC1')
reluLayer('Name','CriticStateRelu1')
fullyConnectedLayer(300,'Name','CriticStateFC2')
];
actionPath1 = [
featureInputLayer(numAct,'Normalization','none','Name','action')
fullyConnectedLayer(300,'Name','CriticActionFC1')
];
commonPath1 = [
additionLayer(2,'Name','add')
reluLayer('Name','CriticCommonRelu1')
fullyConnectedLayer(1,'Name','CriticOutput')
];
criticNet = layerGraph(statePath1);
criticNet = addLayers(criticNet,actionPath1);
criticNet = addLayers(criticNet,commonPath1);
criticNet = connectLayers(criticNet,'CriticStateFC2','add/in1');
criticNet = connectLayers(criticNet,'CriticActionFC1','add/in2');
criticOptions = rlRepresentationOptions('Optimizer','adam','LearnRate',1e-3,...
'GradientThreshold',1,'L2RegularizationFactor',2e-4);
critic1 = rlQValueRepresentation(criticNet,obsInfo,actInfo,...
'Observation',{'observation'},'Action',{'action'},criticOptions);
critic2 = rlQValueRepresentation(criticNet,obsInfo,actInfo,...
'Observation',{'observation'},'Action',{'action'},criticOptions);
% 定义Actor网络
actorNet = [
featureInputLayer(numObs,'Normalization','none','Name','observation')
fullyConnectedLayer(400,'Name','ActorFC1')
reluLayer('Name','ActorRelu1')
fullyConnectedLayer(300,'Name','ActorFC2')
reluLayer('Name','ActorRelu2')
fullyConnectedLayer(numAct,'Name','ActorFC3')
tanhLayer('Name','ActorTanh1')
];
actorOptions = rlRepresentationOptions('Optimizer','adam','LearnRate',1e-3,...
'GradientThreshold',1,'L2RegularizationFactor',1e-5);
actor = rlDeterministicActorRepresentation(actorNet,obsInfo,actInfo,...
'Observation',{'observation'},'Action',{'ActorTanh1'},actorOptions);
% 设置TD3算法参数
agentOptions = rlTD3AgentOptions;
agentOptions.DiscountFactor = 0.99;
agentOptions.TargetSmoothFactor = 5e-3;
agentOptions.TargetPolicySmoothModel.Variance = 0.2;
agentOptions.TargetPolicySmoothModel.LowerLimit = -0.5;
agentOptions.TargetPolicySmoothModel.UpperLimit = 0.5;
% 创建内置TD3算法的智能体
agent = rlTD3Agent(actor,[critic1 critic2],agentOptions);
end
如图4-5所示,智能体定义完成后,在Simulink主菜单点击“库浏览器”按钮,在弹出窗口搜索栏输入“reinforcement learning”,找到"RL Agent"模块,通过鼠标将其拖入到Simulink的路径跟随环境中,双击"RL Agent"模块,在XXX文本框中填入智能体的名称,例如"agent"。

图4-5 RL Agent设置窗口
4.3 训练智能体
智能体创建完成,需要对智能体的训练环境进行配置,如随机种子、环境重置参数初始化、采样速率、仿真结束时间、最大训练回合数、单个回合的最大步长等。具体示例代码如下:
% 打开Simulink环境
mdl = "m2carRL";
open_system(mdl);
% 设置状态空间和动作空间信息
obsInfo = rlNumericSpec([9 1]);
actInfo = rlNumericSpec([2 1],'LowerLimit',[0.1; 1.0],'UpperLimit',[0.5; 1.0]);
% 创建内置强化学习算法的Simulink环境
blks = mdl + ["/RL Agent"];
env = rlSimulinkEnv(mdl,blks,obsInfo,actInfo);
% 设置环境重置时的初始化函数
env.ResetFcn = @onecarpfcResetFcn;
% 固定随机种子
rng(0);
% 创建智能体
agent = createPFCAgent(obsInfo,actInfo);
% 设置采样速率、仿真时间、最大回合数、单个回合最大步长数
Ts = 0.1;
Tf = 120;
maxepisodes = 30000;
maxsteps = ceil(Tf/Ts);
% 设置训练参数, 如并行训练模式、并行采集线程数、采集数据间隔等
trainingOpts = rlTrainingOptions(...
'MaxEpisodes',maxepisodes,...
'MaxStepsPerEpisode',maxsteps,...
'Verbose',false,...
'Plots','training-progress',...
'ScoreAveragingWindowLength',10);
trainingOpts.UseParallel = true;
trainingOpts.ParallelizationOptions.Mode = "async";
trainingOpts.ParallelizationOptions.DataToSendFromWorkers = "Experiences";
trainingOpts.ParallelizationOptions.StepsUntilDataIsSent = 32;
doTraining = true;
if doTraining
trainingStats = train(agent,env,trainingOpts);
else
load('one_car_pfc__td3_parallel.mat','agent');
end
% 保存训练结果
save('one_car_pfc__td3_parallel.mat', 'agent');
训练智能体的脚本文件编写完成后,点击脚本文件的菜单项“运行”按钮,即可开始训练智能体。如图4-6所示,训练过程中,matlab会自动启动情节管理器,在情节管理器窗口可以查看智能体的训练过程,如当前回合的奖励、近10个回合的平均奖励等。
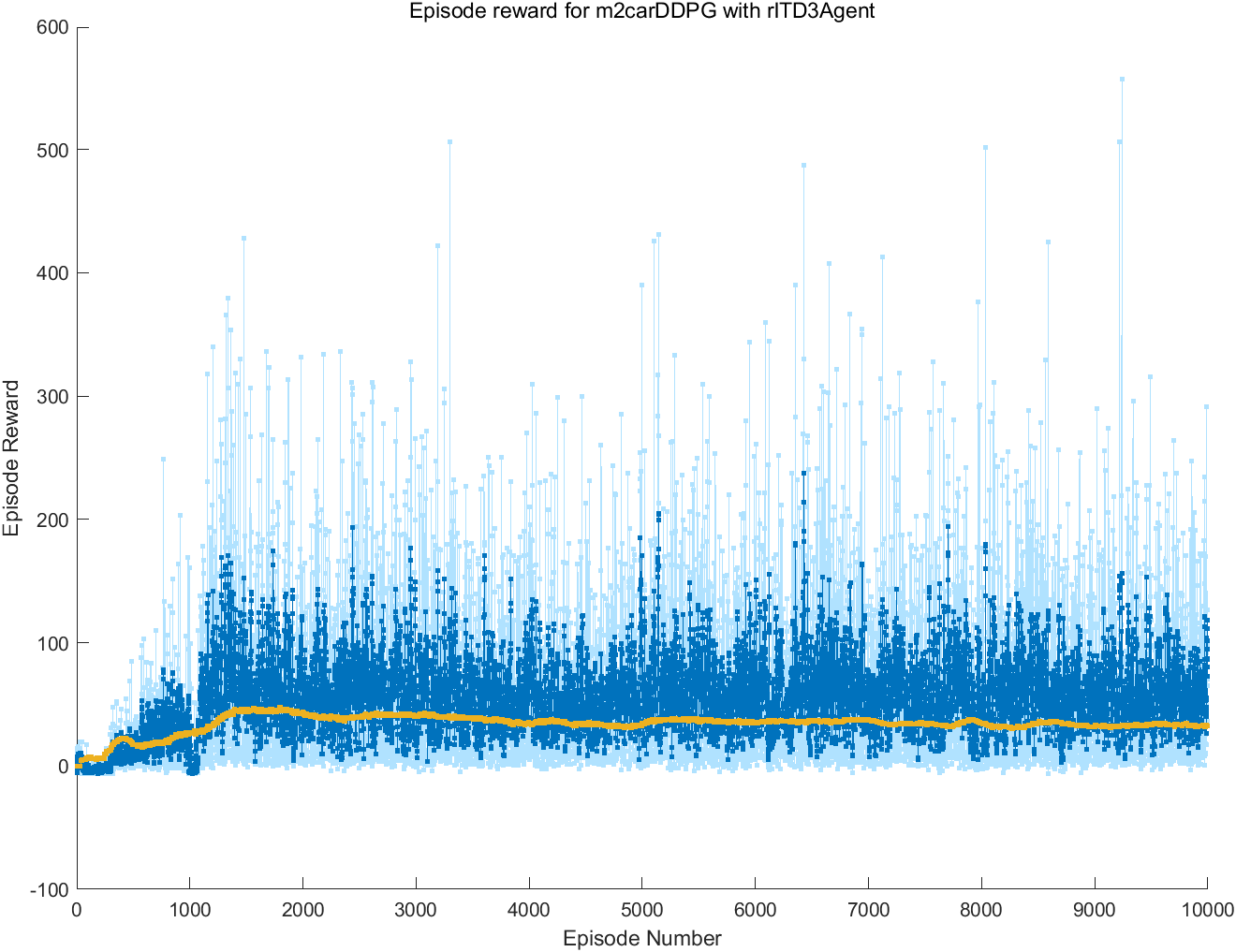
图4-6 情节管理器窗口
训练完成后,可对训练好的智能体进行效果检验,验证的示例代码如下:
% 加载智能体
load('one_car_pfc__td3_parallel.mat','agent');
% 创建验证的Simulink仿真环境
simOptions = rlSimulationOptions('MaxSteps',1200);
experience = sim(env,agent,simOptions);
totalReward = sum(experience.Reward)
4.4 部署智能体
将训练好的智能体部署到实际的虚拟环境或真实环境中,还需要利用matlab的代码生成器生成通用C++代码,供各类系统调用。具体示例代码如下:
load('one_car_pfc__td3_parallel.mat','agent');
generatePolicyFunction(agent, 'FunctionName', "PFC_Policy",'MATFileName',"PFC_Agent.mat");
如图4-7所示,matlab会自动生成PFC_Policy.m和PFC_Agent.mat两个文件,打开PFC_Policy.m文件,其代码内容如下:
function action1 = PFC_Policy(observation1)
%#codegen
% Reinforcement Learning Toolbox
% Generated on: 08-Mar-2022 21:07:29
action1 = localEvaluate(observation1);
end
%% Local Functions
function action1 = localEvaluate(observation1)
persistent policy
if isempty(policy)
policy = coder.loadDeepLearningNetwork('PFC_Agent.mat','policy');
end
observation1 = observation1(:)';
action1 = predict(policy, observation1);
end
图4-7 matlab自动生成的策略文件
可以按照正常脚本文件中的m函数调用即可
4.4.1 基于ROS的虚拟跟车环境
基于第3节所建立的Simulink跟车环境,可以建立类似的基于ROS虚拟跟车环境,利用ROS提供的发布/订阅通信机制实现车辆的控制。如图4-8所示,将matlab自动生成的策略脚本文件封装成控制器模块,供虚拟跟车环境使用,示例代码如下:
function action = one_car_pfc(obs)
action = PFC_Policy(obs);
action = double(action);
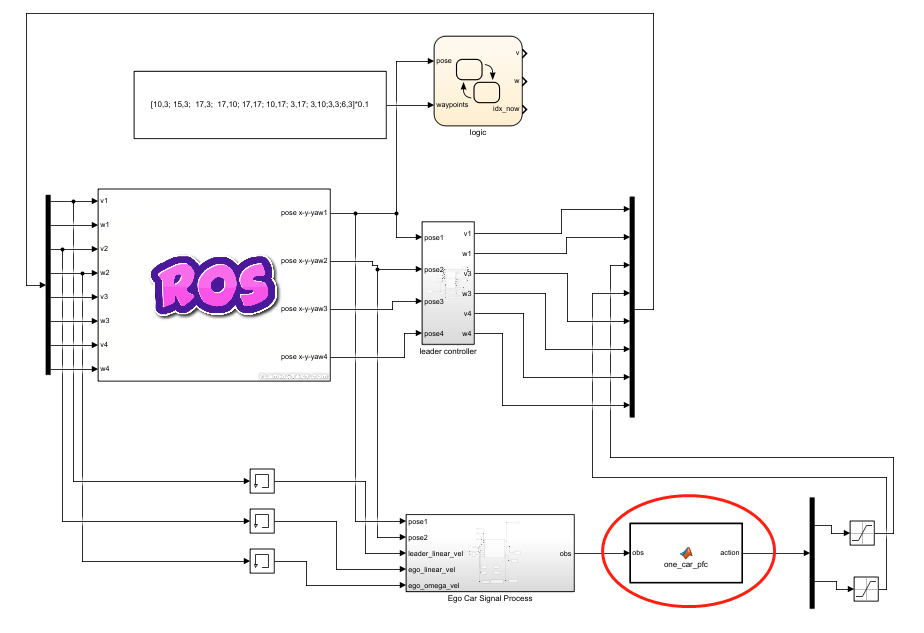
图4-8 基于ROS的路径跟随环境
若需要实现多车跟车效果,相邻的两辆车以前面为领头车、后面为跟随车。例如,环境中有4辆车时,2号车跟随1号车,3号车跟随2号车,4号车跟随3号车,依次类推。如图4-9所示,我们构建了基于ROS的4车路径跟随环境。
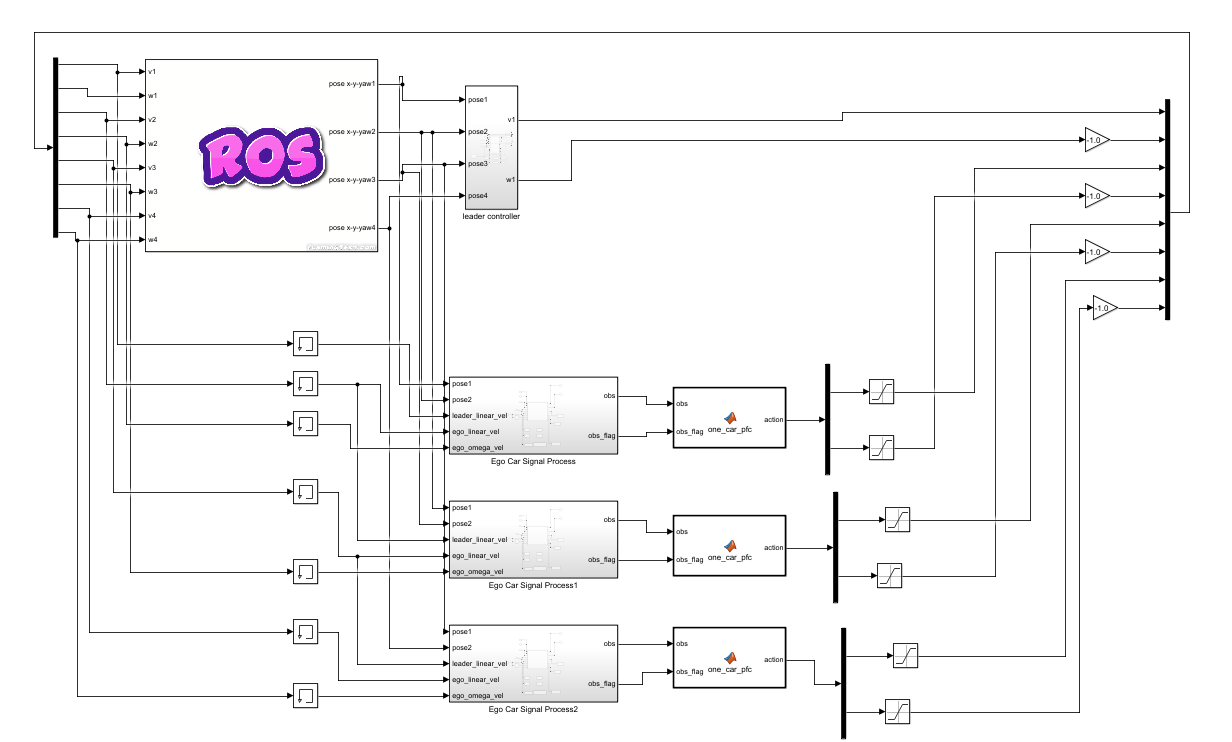
图4-9 基于ROS的多车路径跟随环境
4.4.2 基于ROS的真实跟车环境
若基于ROS的虚拟跟车环境完成后,即可使用真车测试跟车效果。matlab提供了sim2real的实现机制,可将Simulink的代码自动生成支持ROS的执行代码,具体操作步骤是:XXX
五、填坑指南
1. 神经网络输出变量的类型转换问题
matlab编译生成的神经网络模型,其输出类型是single,需要转换成doule类型,否则会报“This assignment writes a 'single' value into a 'double' type. Code generation does not support changing types through assignment. Check preceding assignments or input type specifications for type mismatches.”错误。解决办法详见4.4.1节代码第3行。
六、参考文献
机器人集群行为仿真与开发
1 什么是集群行为
集群行为的思想最早来源于自然界,主要指一些能力不高的个体在某种形式的配合下,表现出超过个体能力而得以“倍增”的生物现象,如自然界的鸟群、鱼群、蚁群和蜂群等,它能帮助生物躲避天敌、增加寻觅到食物的可能性等。近年来,生物、物理、社会学、计算机和控制领域的学者对自然界的集群行为产生了浓厚的兴趣,并积极从各自领域去探索集群行为产生的原因。
从系统观点看,集群行为具有适应性、鲁棒性、分散性和自组织性,可以从简单的局部规则涌现出协调的全局行为。

图1 自然界的经典集群行为
2 集群行为的数学模型——Boids模型
2.1 Boid是什么
1987年,克雷格•雷诺兹(Craig W. Reynolds)发表了一篇有关集群行为研究的论文,题为《Flocks, herds and schools: A distributed behavioral model》,他提出了一种可以模拟生物集群行为的模型,即Boid模型。Boid是bird-oid object词组的缩写,意为“类似鸟的事物”。在复杂性科学领域中,将克雷格提出的集群行为模型称为“Boids”,集群中的单个个体称为"Boid"。
2.2 Boids模型的基本原则
在自然界,动物集群没有一击而溃的弱点。鸟群迁徙时,即使几只鸟脱离了阵型,鸟群的总体动力学也不会变化。鸟群没有中心节点,没有自上而下的控制,但总体表现出受控的秩序,如图2所示。

图2 自然界的鸟群
克雷格的Boids模型正是以“自下而上的控制”为核心,提出了一个在二维或三维空间上模拟集群行为的模型,该模型要求集群的个体遵守三条基本原则:
- 分离(seperation):与邻域内的集群个体避免碰撞;
- 聚合(cohesion):与邻域内的集群个体保持紧凑;
- 对齐(alignment):与邻域内的集群个体速度保持一致。
将上述三条基本原则衍生的行为按照一定方式加权求和,集群即会出现秩序化的社会性行为,如图3所示。

图3 Boids模型仿真示意图
2.3 分离原则(Seperation)
分离原则是使一个集群个体能够与其附近的集群个体保持一定的间隔距离,从而避免发生碰撞,如图4所示。为了保持彼此分离,一个集群个体首先需要获得邻域内其它集群个体的位置信息。对于一个集群个体来言,每一个在其邻域范围内的集群个体与它之间都有一个排斥力,这个排斥力是与它们之间的距离成反比的。每一个集群个体所受到的排斥力是它邻域范围内其它集群个体对它的排斥力的累加。
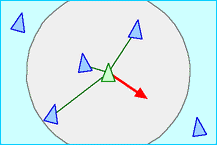
图4 分离原则示意图
按照图论的描述方法,集群内的每个个体 $i$ 都视为图中的一个节点 $V_i$ ,若集群个体 $i$ 可以感知到集群个体 $j$ 的位置和速度信息),则用边 $E_{ij}$ 表示它们存在关联,那么个体 $i$ 的邻近节点集合记为 $N_i={V_j{\in}V:(i,j){\in}E}$ 。分离原则的计算公式如下:
$$\mathbf{u}i^{sep}=\frac{\sum{n=1}^{|N_i|}||\mathbf{q}_i-\mathbf{q}_j||{\cdot}sgn(||\mathbf{q}i-\mathbf{q}j||,d{sep}|)}{\sum{n=1}^{|N_i|}sgn(||\mathbf{q}_i-\mathbf{q}j||,d{sep}|)}$$
$$sgn(x,a)=\left{\begin{array}{lr}1,{\quad}x{\leq}a\0,{\quad}x>a\end{array}\right.$$
其中:
- $\mathbf{u}_i^{sep}$ 为集群个体 $i$ 的分离原则控制量
- $\mathbf{q}_i$ 、 $\mathbf{q}_j$ 为集群个体 $i$ 、 $j$ 的位置
- $d_{sep}$ 为集群个体 $i$ 的排斥距离
- $|N_i|$ 为集群个体 $i$ 邻域内其它集群个体的数量
- $sgn$ 为符号函数。
2.4 聚合原则(cohesion)
聚合原则是使集群具有凝聚力,保持队列的紧凑,如图5 所示。为了能够产生聚合的集群行为,集群个体需要获得其邻域内其它集群个体的位置信息,并计算出邻域内集群个体位置的平均值,由此产生一个作用于该邻域内所有集群个体的吸引力,这样使得集群个体向平均位置方向运动。
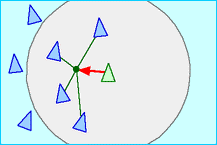
图5 分离原则示意图
聚合原则的计算公式如下:
$$\mathbf{u}i^{coh}=\frac{\sum{n=1}^{|N_i|}\mathbf{q}_j{\cdot}sgn(||\mathbf{q}i-\mathbf{q}j||,d{coh}|)}{\sum{n=1}^{|N_i|}sgn(||\mathbf{q}_i-\mathbf{q}j||,d{coh}|)}-\mathbf{q}_i$$
其中:
- $\mathbf{u}_i^{coh}$ 为集群个体 $i$ 的分离原则控制量
- $d_{coh}$ 为集群个体 $i$ 的聚合距离
- $sgn$ 为符号函数,函数意义同前。
2.5 对齐原则(alignment)
对齐原则使每个集群个体与其邻域内其他集群个体的速度保持一致。如图6 所示。为了能够实现速度一致,每个集群个体需要获得邻域内其它集群个体速度信息,计算出邻域内集群个体的平均速度。通过速度对齐,可以使得集群个体速度大小和方向与这个邻域内所有集群个体速度的平均值保持一致。
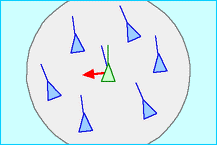
图6 对齐原则示意图
对齐原则的计算公式如下:
$$\mathbf{u}i^{ali}=\frac{\sum{n=1}^{|N_i|}\mathbf{p}_j{\cdot}sgn(||\mathbf{q}i-\mathbf{q}j||,d{ali}|)}{\sum{n=1}^{|N_i|}sgn(||\mathbf{q}_i-\mathbf{q}j||,d{ali}|)}$$
其中:
- $\mathbf{u}_i^{ali}$ 为集群个体 $i$ 的分离原则控制量
- $\mathbf{q}_j$ 为集群个体 $i$ 的速度
- $sgn$ 为符号函数,函数意义同前。
2.6 Boids数学模型
由于雷诺兹所提出的三条基本原则实际上是基于系统环境中集群个体的位置和速度来考虑的。假设有 $N$ 个集群个体在 $n$ 维的欧式空间中运行,则第 $i$ 个集群个体的二阶运动方程为:
$$\begin{array}{lr}\mathbf{\dot{q}}_i=\mathbf{p}_i\\mathbf{\dot{p}}_i=\mathbf{u}_i,i=1,...,N\end{array}$$
其中:
- $\mathbf{q}_i\in{\mathbf{R}^n}$ 代表集群个体 $i$ 的位置向量
- $\mathbf{p}_i\in{\mathbf{R}^n}$ 代表集群个体 $i$ 的速度矢量
- $\mathbf{u}_i\in{\mathbf{R}^n}$ 代表集群个体 $i$ 的控制输入(加速度)向量
根据雷诺兹所提出的三条基本原则,将 $\mathbf{u}_i^{sep}$ 、 $\mathbf{u}_i^{coh}$ 、 $\mathbf{u}_i^{ali}$ 三个控制量加权求和,输入到集群系统中即可实现集群行为,其控制量的计算公式如下:
$$ \mathbf{u}i=\omega{sep}\cdot\mathbf{u}i^{sep}+\omega{coh}\cdot\mathbf{u}i^{coh}+\omega{ali}\cdot\mathbf{u}_i^{ali} $$
其中: $\omega_{sep}$ 、 $\omega_{coh}$ 、 $\omega_{ali}$ 分别表示 $\mathbf{u}i^{sep}$ 、 $\mathbf{u}i^{coh}$ 、 $\mathbf{u}i^{ali}$ 控制量的权重,且 $\omega{sep},\omega{coh},\omega{ali}\geq0$ 。
3 Boids数学模型的改进
由于雷诺兹所提出的Boids数学模型初始条件(如初始位置和速度)任意选取的,可能会产生分裂现象。如图7所示,整个集群会被分成三个子集群,每个子集群的个体只能与其所在子集群内的个体交互,由此产生了分裂现象。在实际的机器人集群控制应用中,集群需要在有限空间(二维或三维)上运动,则要考虑边界避碰和障碍物避碰的情况。同时,整个机器人集群并不是漫无目的地机动,需要对其机动方向和速度加以引导。为此,我们在Boids数学模型的基础上,增加了边界避碰、障碍物避碰和领导者-跟随者三条原则。
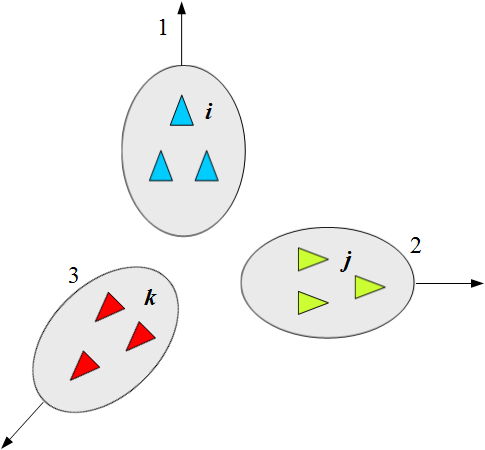
图7 分裂现象
3.1 触界反弹原则
触界反弹原则是每个集群个体与人为设置的虚拟边界保持一定的间隔距离,从而避免发生碰撞,如图8所示。当某个集群个体与虚拟边界的距离小于某个阈值 $d_{border}$ 时,会产生一个触界反弹的排斥力。
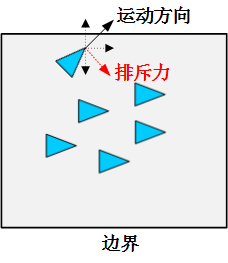
图8 边界避碰原则示意图
边界避碰原则的计算公式如下: $$ \mathbf{u_i^{border}}=k_1\cdot\mathbf{p}{border}\cdot{sgn(d{i,border},d_{border})} $$ 其中:
- $\mathbf{p}_{border}$ 表示集群个体在虚拟边界所产生的排斥力
- $d_{i,border}$ 表示集群个体 $i$ 与虚拟边界的距离
- $k_1$ 表示调节系数,且 $k_1<0$
- $sgn$ 为符号函数,函数意义同前。
3.2 障碍物避碰原则
障碍物避碰原则是每个集群个体与障碍物保持一定的间隔距离,从而避免发生碰撞,如图9所示。当某个集群个体与障碍物的距离小于某个阈值 $d_{obs}$ 时,会产生一个排斥力,这个排斥力是与它们之间的距离成反比。
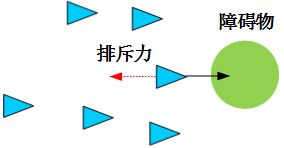
图9 障碍物避碰原则示意图
障碍物避碰原则的计算公式如下: $$ \mathbf{u}i^{obs}=k_2\cdot\sum{l=1}^{L}||\mathbf{q}_i-\mathbf{q}_l^{obs}||{\cdot}sgn(||\mathbf{q}_i-\mathbf{q}l^{obs}||,d{obs}) $$ 其中:
- $\mathbf{u}_i^{obs}$ 为集群个体 $i$ 的障碍物避碰原则控制量
- $\mathbf{q}_l^{obs}$ 为第 $l$ 个障碍物的位置
- $k_2$ 表示调节系数,且 $k_2<0$
- $sgn$为符号函数,函数意义同前。
3.3 领导者-跟随者原则
领导者-跟随者原则是在集群运动中加入引导信息,引导集群以期望的速度向某个目的地运动。根据该原则,可在集群内设置虚拟领导者或真实领导者(即指定某个集群个体为领导者,其它集群个体为跟随者)。引导信息分为两个部分,一是领导者的期望速度 $\mathbf{p}{leader}$ ,二是领导者的目的地位置 $\mathbf{q}{leader}$ ,其计算公式如下: $$ \mathbf{u}i^{leader}=c_1(\mathbf{q}{leader}-\mathbf{q}i)+c_2(\mathbf{p}{leader}-\mathbf{p}_i) $$ 其中:
- $\mathbf{u}_i^{leader}$ 为集群个体 $i$ 的领导者-跟随者原则控制量
- $c_1$ 、 $c_2$ 为调节系数,且 $c_1>0,c_2>0$
3.4 改进型Boids数学模型
在雷诺兹所提出的Boids数学模型基础上,综合边界避碰、障碍物避碰和领导者-跟随者三条原则,可以得到改进型的Boids数学模型,其控制量的计算公式如下: $$ \mathbf{u}i=\omega{sep}\cdot\mathbf{u}i^{sep}+\omega{coh}\cdot\mathbf{u}i^{coh}+\omega{ali}\cdot\mathbf{u}i^{ali}+\omega{border}\cdot\mathbf{u}i^{border}+\omega{obs}\cdot\mathbf{u}i^{obs}+\omega{leader}\cdot\mathbf{u}_i^{leader} $$ 其中:
- $\omega_{border}$ 、 $\omega_{obs}$ 、 $\omega_{leader}$ 分别表示 $\mathbf{u}i^{border}$ 、 $\mathbf{u}i^{obs}$ 、 $\mathbf{u}i^{leader}$ 控制量的权重,且 $\omega{border},\omega{obs},\omega{leader}\geq0$ , $\omega_{sep}$ 、 $\omega_{coh}$ 、 $\omega_{ali}$ 符号意义同前。
4 机器人集群行为开发
机器人集群的设计灵感来源于自然界的自组织系统,例如社交昆虫、鱼类或鸟群,它们都是基于简单本地交互规则的涌现性群体行为。为此,我们基于雷诺兹所提出的的Boids数学模型,构建比单个机器人更加鲁棒、更强容错和更高灵活的系统,并且能够更好地调整自身行为来适应环境变化。
4.1 集群行为仿真开发流程
我们将机器人集群抽象为复杂系统,每个集群机器人都是复杂系统的智能个体,智能个体不仅能感知物理环境,还能感知同伴的活动,最后根据这些信息决定如何移动。在仿真建模过程中,可以利用形式最为简单的粒子系统进行模拟。一般情况下,用简单的图形或者点表示粒子,每个粒子的移动方式遵循牛顿第二定律,粒子之间可以进行简单的信息交互(如接收同伴的位置和速度信息),但交互能力有限制,不能与所有同伴进行交互。
具体的仿真开发流程如图10所示,智能个体主要由信息交互、控制和机动三大核心模块构成,信息交互模块主要获取其它智能个体的位置和速度信息,并将该信息传递给控制模块,控制模块主要根据集群控制算法计算得到智能个体关于线速度和角速度的控制量,并将控制量信息传递给机动模块,智能个体按照牛顿第二定律进行移动,输出关于位置和速度的运动状态信息,并将该信息传递给其它智能个体的信息交互模块。
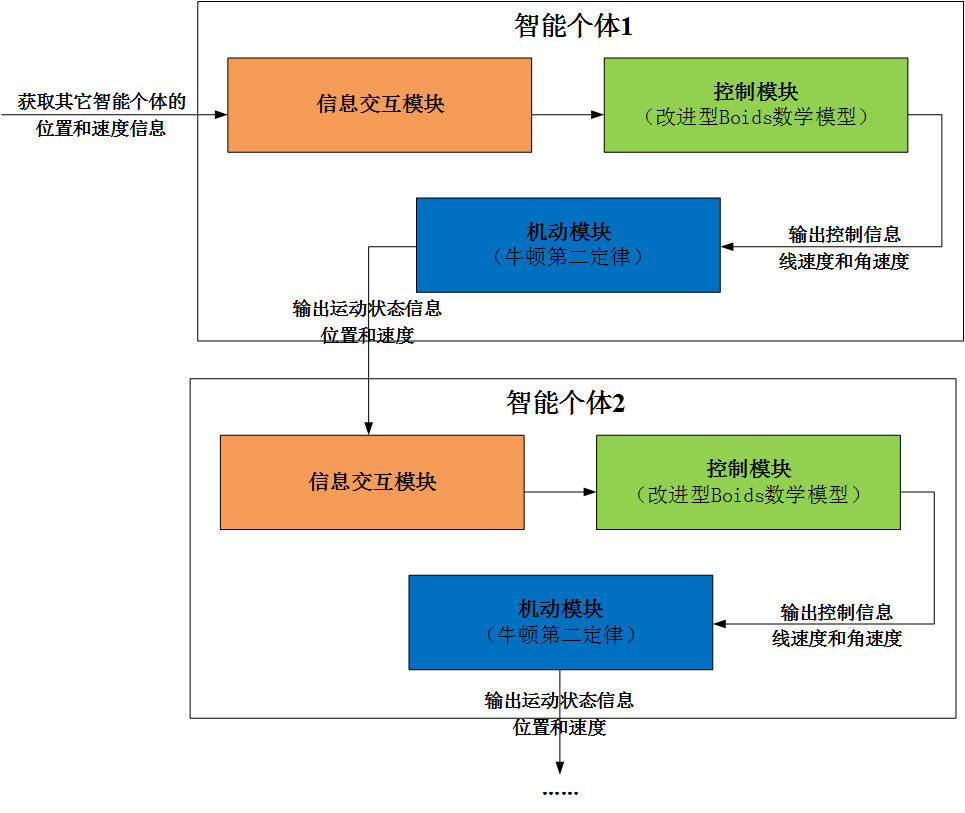
图10 仿真开发流程示意图
4.2 集群行为控制示例代码
集群控制函数主要实现改进型Boids数学模型的功能,根据自身和其它智能个体的运动状态信息计算其在下一个仿真步长的运动控制量。
4.2.1 分离原则
示例代码如下:
function steer = separate(boid_id, boids_num, flock_pos, sep_dist, boid_maxspeed)
steer = [0.0, 0.0];
count = 0;
this_boid_loc = flock_pos(:,boid_id);
for i=1:boids_num
if boid_id==i
continue;
end
other_boid_loc = flock_pos(:,i);
d = vec_dist(this_boid_loc', other_boid_loc');
if d>0 && d < sep_dist
diff = this_boid_loc'- other_boid_loc';
diff = vec_normalize(diff);
diff = diff*(1.0/d);
steer = steer + diff;
count = count + 1;
end
end
if count>0
steer = steer * (1.0/count);
end
if vec_mag(steer)>0
steer = vec_normalize(steer);
steer = steer * boid_maxspeed;
end
end
4.3 聚合原则
示例代码如下:
function steer = cohesion(boid_id, boids_num, flock_pos, coh_dist, boid_maxspeed)
steer = [0.0, 0.0];
count = 0;
this_boid_loc = flock_pos(:,boid_id);
for i=1:boids_num
if boid_id==i
continue;
end
other_boid_loc = flock_pos(:,i);
d = vec_dist(this_boid_loc', other_boid_loc');
if d>0 && d < coh_dist
steer = steer + other_boid_loc';
count = count + 1;
end
end
if count>0
steer = steer * (1.0/count);
steer = seek(steer, this_boid_loc', boid_maxspeed);
end
end
4.4 对齐原则
示例代码如下:
function steer = align(boid_id, boids_num, flock_pos, flock_vel, coh_dist, boid_maxspeed)
steer = [0.0, 0.0];
count = 0;
this_boid_loc = flock_pos(:,boid_id);
for i=1:boids_num
if boid_id==i
continue;
end
other_boid_loc = flock_pos(:,i);
d = vec_dist(this_boid_loc', other_boid_loc');
if d>0 && d < coh_dist
steer = steer + flock_vel(:,i)';
count = count + 1;
end
end
if count>0
steer = steer*(1.0/count);
steer = vec_normalize(steer);
steer = steer * boid_maxspeed;
end
end
4.5 触界反弹原则
示例代码如下:
function [steer, current_this_boid_flag,flock_avoid_vel] = border_fear(boid_id, second_paras, x,y , vx,vy, flock_avoid_vel, flock_border_flag, avoid_border_dist, boid_maxspeed)
x_low = second_paras(1) + avoid_border_dist;
x_high = second_paras(2) - avoid_border_dist;
y_low = second_paras(3) + avoid_border_dist;
y_high = second_paras(4) - avoid_border_dist;
current_this_boid_flag = is_in_border(x, y, x_low, x_high, y_low, y_high);
if current_this_boid_flag == 0
steer = [0.0, 0.0];
else
old_this_boid_flag = flock_border_flag(boid_id);
this_boid_avoid_vel = flock_avoid_vel(:, boid_id)';
if old_this_boid_flag>0 && current_this_boid_flag>0 && old_this_boid_flag~=current_this_boid_flag
this_boid_avoid_vel = [0.0, 0.0];
% 鍙宠竟鐣?
if x >= x_high
if vx>=0
vx = -vx;
end
end
% 宸﹁竟鐣?
if x <= x_low
if vx < 0
vx = -vx;
end
end
% 涓婅竟鐣?
if y >= y_high
if vy >=0
vy = -vy;
end
end
% 涓嬭竟鐣?
if y <= y_low
if vy < 0
vy = -vy;
end
end
this_boid_avoid_vel = [vx, vy];
flock_avoid_vel(1, boid_id) = vx;
flock_avoid_vel(2, boid_id) = vy;
end
steer = this_boid_avoid_vel;
if vec_mag(steer)>0
steer = vec_normalize(steer);
steer = steer * boid_maxspeed;
else
steer = [0.0, 0.0];
end
end
end
4.6 避障原则
示例代码如下:
function desired = obstacle_fear(boid_id, flock_pos, obstacle_num, ob_pos, avoid_obs_dist, boid_maxspeed)
steer = [0.0, 0.0];
desired = [0.0, 0.0];
count = 0;
this_boid_loc = flock_pos(:,boid_id)';
for i=1:obstacle_num
this_ob_loc = ob_pos(:,i)';
steer = this_boid_loc - this_ob_loc;
if vec_mag(steer) <= (0.15 + avoid_obs_dist)
desired = desired + steer
count = count + 1;
end
end
if count > 0
desired = vec_normalize(desired);
desired = desired * boid_maxspeed;
end
end
4.7 领导者-跟随者原则
示例代码如下:
function [steer,new_waypt_id] = virtual_leader(boid_id, wp_ids, flock_pos, waypoint_num, waypoints, boid_maxspeed)
steer = [0.0, 0.0];
this_boid_loc = flock_pos(:, boid_id)';
new_waypt_id = set_waypoint(boid_id, wp_ids, flock_pos, waypoint_num, waypoints);
curr_waypt = waypoints(:,new_waypt_id)';
steer = curr_waypt - this_boid_loc;
if vec_mag(steer) > 0
steer = vec_normalize(steer);
steer = steer * boid_maxspeed;
end
end
参考文献
[1]Flocks, herds and schools: A distributed behavioral model
[2]Daniel Shiffman. 代码本色$\cdot$用编程模拟自然系统[M].人民邮电出版社,2021:218-269.
[3]苏厚胜
[4]Swarm Robotics: Past, Present, and Future
pure_pursuit算法原理
Pure Pursuit是一种几何跟踪控制算法,也被称为纯跟踪控制算法。该算法最早由R. Wallace在1985年提出,其思想是基于当前车辆的后轮中心位置(车辆质心),在参考路径上向$l_d$称为前视距离)的距离匹配一个预瞄点,车辆以一定角度全速向次预瞄点行驶。
假设车辆后轮中心可以按照一定的转弯半径𝑅行驶至该预瞄点,然后根据前视距离$l_d$、转弯半径𝑅、车辆坐标系下预瞄点的朝向角𝛼之间的几何关系来计算前轮转角$\delta$
pp算法模型
如上图所示,在三角形OAC中,根据正弦定理可得: $$\frac{l_d}{\sin{\left(2\alpha\right)}}=\frac{R}{\sin{\left(\frac{\pi}{2}-\alpha\right)}}$$
化简得: $$R=\frac{l_d}{2\sin{\left(\alpha\right)}}$$
根据车辆的运动学方程,有: $$\delta=\tan^{-1}{\frac{L}{R}}$$
所以,前轮转角为: $$\delta=\tan^{-1}{\frac{2L\sin{\left(\alpha\right)}}{l_d}}$$
定义横向误差为后轮中心位置和预瞄点在横向上的误差,如上图中的$e_y$ $$e_y=l_d\sin{\left(\alpha\right)}$$
$$sin{\left(\alpha\right)}=\frac{e_y}{l_d}$$
当前轮转角很小是,横向误差可以近似为 $$\delta=\frac{2L}{{l_d}}\sin{\left(\alpha\right)}$$
另外对于非ackerman底盘,尤其是前后轮差距不是很大的底盘(双轮差速加万向轮),L可以与最大速度v_近似。
$$\delta=\frac{2{v_-}{e_y}}{{l_d}^2}$$
即只要确定了$l_d$,就确定了转向角
基于以上原理,算法步骤为:
1.确定车辆位置和目标点,进行坐标系转换
2.确定转向角$\delta$
3.发布速度指令,全速追踪,更新车辆位置
以下给出非ackerman底盘的pure pursuit算法核心部分具体代码:
if (!goal_reached_) {
// We are tracking.
ROS_INFO("goal_reached_");
// Compute linear velocity.
// Right now,this is not very smart :)
v_ = copysign(v_max_, v_); // max linear speed
// Compute the angular velocity.
// Lateral error is the y-value of the lookahead point (in base_link
// frame)
double yt = lookahead_.transform.translation.y;
double ld_2 = ld_ * ld_;
// v_可以与L近似,此处为核心代码
cmd_vel_.angular.z = (-1) * std::min(2 * v_ / ld_2 * yt, w_max_);
// Set linear velocity for tracking.
cmd_vel_.linear.x = v_;
ROS_INFO("here if");
} else {
// We are at the goal!
// Stop the vehicle
// The lookahead target is at our current pose.
lookahead_.transform = geometry_msgs::Transform();
lookahead_.transform.rotation.w = 1.0;
// Stop moving.
cmd_vel_.linear.x = 0.0;
cmd_vel_.angular.z = 0.0;
}
// Publish the lookahead target transform.
lookahead_.header.stamp = ros::Time::now();
tf_broadcaster_.sendTransform(lookahead_);
// Publish the velocities
pub_vel_.publish(cmd_vel_);
参考链接
https://www.mathworks.com/help/robotics/ug/pure-pursuit-controller.html
二次开发综述
KKSWARM项目为用户提供了二次开发手册以及各种配置。您可以根据需要,阅读以下内容
软件环境安装
综述
本教程将会引导读者如何在Linux系统下搭建 KKSWARM 项目所需要的环境。
提示
- 如果您是购买过本产品的用户,可以忽略此内容
- 为了节省开发人员的时间和提高开发人员的效率。阿木实验室提供已经制作好的镜像,该镜像包含下面所有的内容。点击系统镜像下载 下载即可。
- 有能力和精力的用户可以根据下面步骤自行搭建环境
Ubuntu安装
ROS安装
ROS版本选择 Melodic
ROS安装参考: ROS官方教程
补充:官方教程第1.3步 Set up your keys 的命令修改为
sudo apt-key adv --keyserver 'hkp://keyserver.ubuntu.com:80' --recv-key C1CF6E31E6BADE8868B172B4F42ED6FBAB17C654
相机驱动安装
- 进入海康威视官网,选择
机器视觉工业相机客户端MVS V2.1.0(Linux)进行下载
注意
根据实际情况,版本可能有小更新。选择
机器视觉工业相机客户端MVS V2.1.x (Linux)。本项目使用的是 2.1.0版本。(您也可以点击这里下载 2.1.0版本 )
-
下载完成以后,解压。解压后将会显示适应各种架构的计算机的压缩包。这里选择
MVS-2.1.0_x86_64_20201228.tar.gz这个压缩包进行安装。 -
解压第2步选择的压缩包
tar -xvzf MVS-2.1.0_x86_64_20201228.tar.gz cd MVS-2.1.0_x86_64_20201228 sudo bash setup.sh相机驱动将会安装在
/opt/MVS中启动相机界面的命令为
cd /opt/MVS/bin ./MVS.sh界面如图1所示:
图1 相机启动界面
相机驱动的动态链接库路径为
/opt/MVS/lib/64相机驱动头文件路径为
/opt/MVS/include/ -
安装完毕后,将海康威视的动态库加入到系统动态库中。否则程序将无法运行。
cd /etc/ld.so.conf.d sudo vim hik.conf ## 如果不会vim,则输入 sudo gedit hik.conf #在第一行加入相机驱动的动态链接库路径 /opt/MVS/lib/64 sudo ldconfig # 刷新配置
警告
第4步很重要
KKswarm安装
git clone https://github.com/kkswarm/kk-robot-swarm
Apriltag以及apritag_ros安装
KKSWARM 项目采用的标签家族是 Tag36h11,尺寸是7cm。 详情见 doc/apritags1-50.pdf。您也可以通过软件自动生成该家族标签。详情点击通过openmv生成apriltag标签
Apriltag依赖安装
sudo apt install python3-pip
pip3 install numpy
Apriltag安装
cd ~/kk-robot-swarm/
git clone https://github.com/AprilRobotics/apriltag.git
cd apriltag
mkdir build
cmake ..
make -j4
sudo make install
- Apriltag相关头文件将会被安装在
/usr/local/include/apriltag - Apriltag相关的库将会被安装在
/usr/local/lib/ - 有关Apriltag的相关信息,可以访问其GitHub项目主页获取更多信息
apriltag_ros安装
KKSWARM 项目针对 apriltag_ros 这个功能包做了二次开发和修改
为了提升研发效率,已经将修改后的集成到代码中,当用户克隆 KKSWARM 项目的时候,会将修改后的 apriltag_ros 一并下载。
编译
cd ~/kk-robot-swarm
catkin_make
添加环境变量
echo "source ~/kk-robot-swarm/devel/setup.bash" >> ~/.bashrc
source ~/.bashrc
至此,整个 KKSWARM 项目的软件环境安装完毕。
相机校准
KKSWARM定位系统依赖于相机,因此,相机参数内参校准将会影响到后续的定位系统的精度
注意
虽然相机在给到用户手中是进行过校准的。但是由于用户实际使用场地和发货前测试场地不一定完全相同。因此建议用户在拿到相机后,自行进行校准一次
前期准备
相机校准需要用到以下环境和物品:
- 海康威视相机驱动Linux版本(软件环境安装)
- 完成场地搭建工作
- 准备棋盘格校准工具
- 安装校准所需工具
sudo apt intstall ros-melodic-camera_calibration
具体操作步骤
注意
- 由于该相机镜头是一个可变焦距镜头,因此在校准前。 务必固定好焦距,再进行校准。
- 校准将会在完成场地搭建的基础上进行校准
- 校准时,建议两个人配合完成
- 将相机固定在龙门架上,然后将相机接入MINI主机
- 打开终端,输入命令:
cd /opt/MVS/bin
./MVS.sh
此时将会启动海康威视相机的客户端界面,如图1所示:
图1 相机启动界面
- 根据图2的操作,连接相机
图2 连接相机
- 相机连接以后,需要进行调节相机的焦距。相机镜头有两个旋钮,通过旋转不同的旋钮使得在图像采集界面出现的图像是 清晰可见 以及 亮度合适 的画面。
警告
调节焦距需要使用家庭便携梯子,或者桌子等。请注意安全!防止跌落摔伤
- 待焦距固定以后,开始校准相机
- 打开终端,输入命令,启动
roscoreroscore - 打开终端,输入命令,启动相机节点
rosrun camtoros camtoros - 打开终端,输入命令,启动相机校准节点
rosrun camera_calibration cameracalibrator.py --size 6x4 --square 0.037 image:=/hik_camera/image_raw
如图3所示:
图3 相机校准程序
- 将棋盘格放置在镜头正下方,然后开始
左右、上下、倾斜等动作进行缓慢移动。直到右边的按钮变亮即可,如图4所示:
图4 相机校准完成
注意
尽可能让棋盘格离相机近一点,方便检测。如果位置太低,会出现无法检测的情况
- 点击 图4 中的
CALIBEATE按钮,程序将会自动进行校准。等校准完成以后,终端将会输出校准信息,如图5所示
图5 相机校准结果
- 点击
SAVE按钮,将信息保存下来,同时终端将会输出保持位置的信息。如图6所示

图6 相机校准结果保存位置
- 打开终端,输入命令
mkdir ~/calb
cp /tmp/calibrationdata.tar.gz ~/calb
cd ~/calb
tar -xzvf calibrationdata.tar.gz
- 在解压中的文件中,找到名为
ost.yaml的文件,该文件包含相机校准的参数。将该文件重命名为caminfo.yaml放到kk-robot-swarm/src/camtoros/config/文件夹下。
注意
该操作将会覆盖发货测试时的相机参数,建议先将原来的文件重命名为
caminfo.yaml.back再进行复制操作
- 打开复制后的文件
caminfo.yaml,将文件内的参数修改为如下所示:
...
camera_name: hik_camera
...
distortion_model: radtan
通信协议
本教程将会引导读者了解 KKswarm 项目,上位机(迷你主机)和小车之间的通信协议以及相关的内容。
提示
上行和下行协议的解析均在
kk-robot-swarm/src/tcp_communication/src/tcpDriverNode.cpp文件中
上行协议
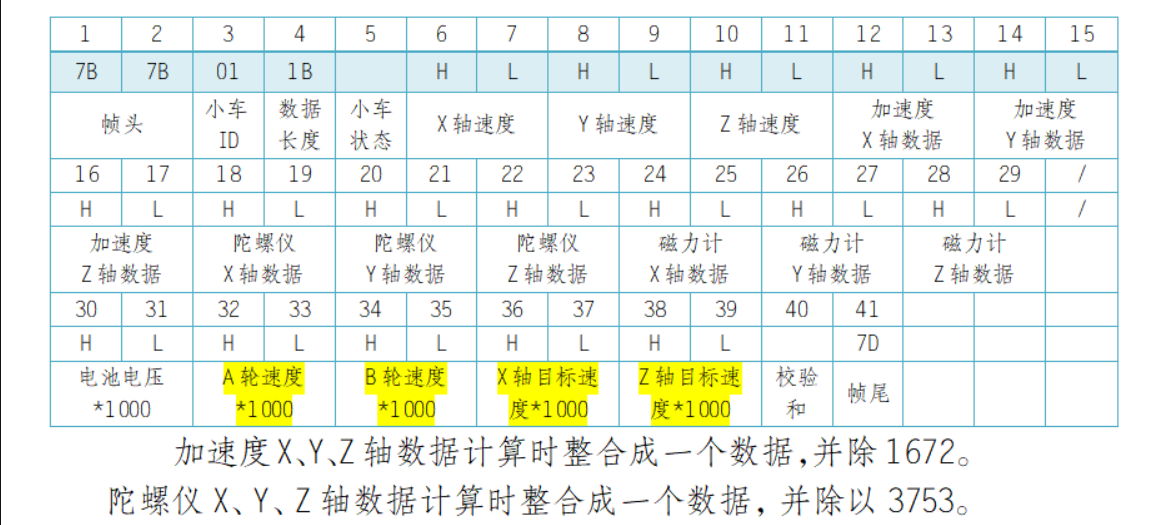
上行协议,指小车发送给上位机的数据。包含了小车ID、小车电量、小车的线速度、角速度等信息。
上行协议解析相关代码见 tcpDriverNode.cpp 文件中的函数 void parsingUpProtocol(int connfd, unsigned char buff[],int size)内容
下行协议

下行协议,指上位机发送给下位机的数据。主要是控制小车的线速度和角速度。
下行协议解析相关代码见 tcpDriverNode.cpp 文件中的函数 velReceviveCallBack(const geometry_msgs::Twist::ConstPtr &msgs, int id)内容
定位系统
定位系统简介
KKSWARM定位系统采用摄像头和二维码的方式获取小车的位置和方向信息。通过垂直悬挂的摄像机采集场地中贴有二维码的小车,获取其位置和方向数据,同时将数据传入到整个系统之中。供其他功能包使用。
定位系统功能包
定位系统相关功能包如下:
-
camtoros:该功能包为海康威视工业相机的ROS驱动-
发布话题:
-
/hik_camera/image_raw [sensor_msgs/Image]
原始图像数据
-
/hik_camera/camera_info [sensor_msgs/CameraInfo]
相机内外参数
-
-
-
apriltag_ros- 发布话题:
-
/tag_detections [apriltag_ros/AprilTagDetectionArray]
标签检测
-
/tag_detections_image [sensor_msgs/Image]
检测到标签的图像数据
-
/tf
坐标变换数据
-
- 订阅话题:
-
/hik_camera/image_raw [sensor_msgs/Image]
-
/hik_camera/camera_info [sensor_msgs/CameraInfo]
-
- 发布话题:
-
global_vision:定位系统主要功能包。用于发布图像定位数据-
发布话题:(x表示小车编号)
-
/robot_x/cmd_vel [geometry_msgs/Twist]
每一辆小车的速度
-
/robot_x/pose [nav_msgs/Odometry]
每一辆小车的位置
-
-
订阅话题:
-
/tf
坐标变换数据
-
/comm [kkswarm_msgs/Carstate]
小车状态信息
-
-
-
tcp_communication:TCP通信功能包。用于获取上层和底层直接的通信- 发布话题:
-
/comm [kkswarm_msgs/Carstate]
小车状态信息
-
- 订阅话题:
-
/robot_1/cmd_vel [geometry_msgs/Twist]
-
/robot_2/cmd_vel
-
...
-
/robot_10/cmd_vel
每一辆小车的速度,默认是10辆小车。单位:m/s
-
- 发布话题:
定位系统数据流向图
定位系统数据流向图
WIFI配置
本教程将会引导读者如何配置 路由器以及小车WIFI
提示
- 本内容作仅仅针对想要进行二次开发和自定义的用户
- 如果在使用途中存在IP冲突,可以根据以下内容修改
- 以下内容在用户拿到手里后已经配置完毕,如非必要,切勿修改
注意
整个
KKSWARM项目使用的路由器 均不连接至公网 ,即路由器仅仅提供局域网。
配置路由器
提示
参考路由器包装内部的使用手册,这里做简单摘要。
-
将路由器开机,同时打开一台电脑,将电脑连接至
KK_Swarm_Server网络。输入密码为22222222 -
此时浏览器将会自动打开路由器的配置界面,如果没有。则手动打开浏览器,输入
http://router.asus.com,进入配置界面。然后在配置界面输入登录名称为:
KK_Swarm_Server密码为:
22222222如图2所示:
图2 WIFI登录界面
注意
- 上面的配置并非是华硕路由器出厂设置,这是在发货测试前的配置。目的是为了让用户做到开箱即用。
- 如果您想要自定义WIFI名称和密码,可以在上述界面进行设置,抑或是将路由器恢复出厂设置后自行按照路由器使用手册进行配置
- 同时,如果您自定义了WiFi名称和路由器,相应的,要对每辆小车的WIFI进行设置。具体见本文后续内容
设置固定IP
KKSWARM 的迷你主机的固定IP为:192.168.50.100。用户可以根据实际需要,进行修改。修改方法如下:
-
首先将迷你主机连接至
KK_Swarm_Server网络 -
依次打开
设置--WIFI--KK_Swarm_Server 网络旁边的齿轮符号--IPV4--Manual如图3所示
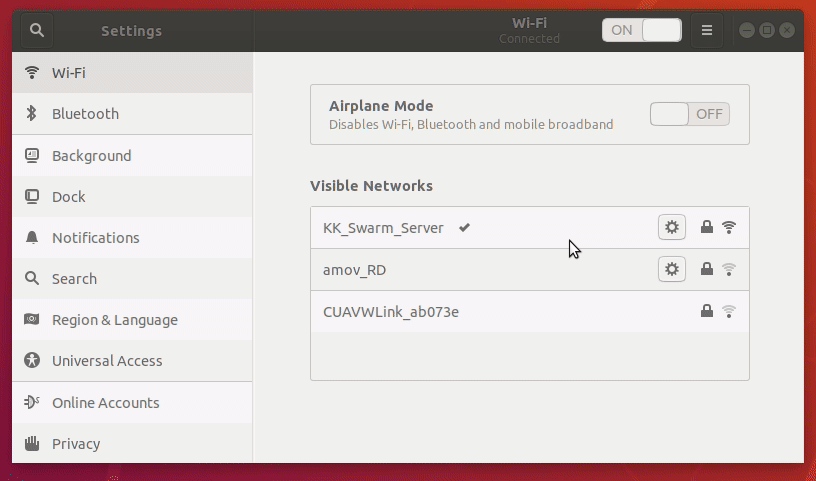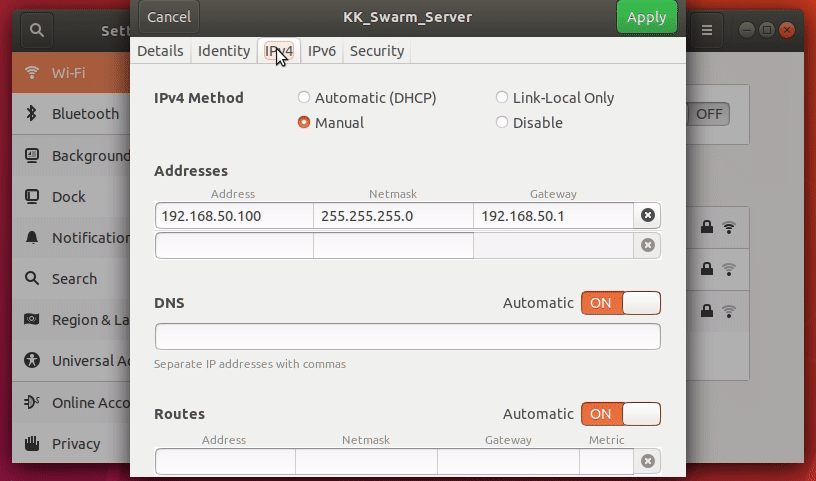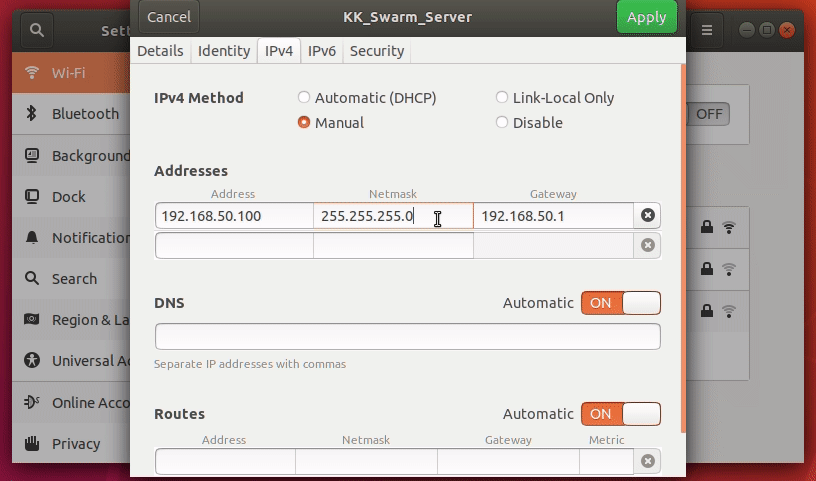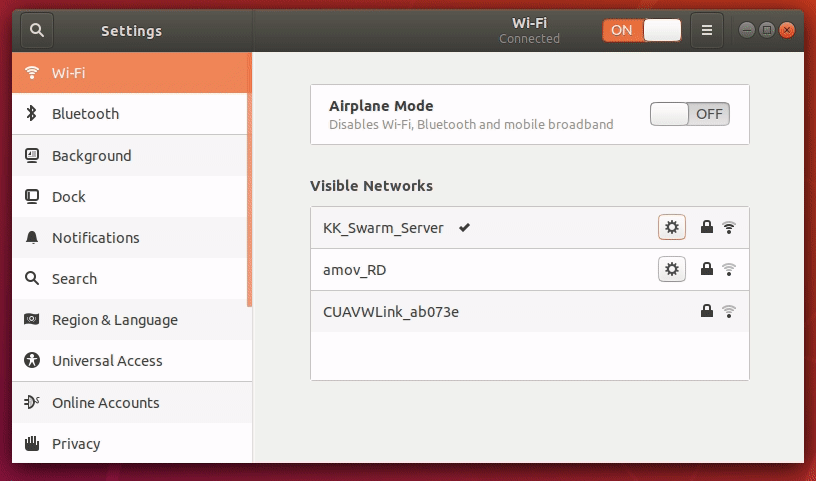
图3 配置MINI主机的固定IP
警告
小车WIFI在出厂的时候已经配置好并且经过测试,如非必要,请勿修改!
配置小车WIFI模块
这里以 7 号小车为例
图4 安装串口驱动
- 然后将小车外壳打开,取下WiFi模块,安装在WIFI模块配置地板上,并将地板通电。
- 将用TTL转USB线连接地板,如图5所示:

图5 连接底板
注意
- 底板的
TX应该与TTL模块的RX连接;底板的RX应该与TTL模块的TX连接- 底板
TX和RX的位置在RS485字样的中间
- 然后打开串口配置软件,连接至将波特率设置为
115200,点击连接。如图6所示:
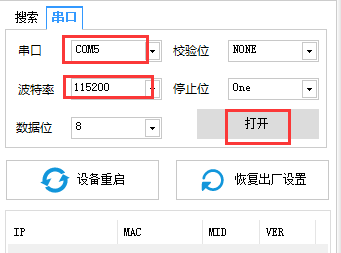
图6 串口连接
提示
COMx由系统分配,这里为COM5
- 点击
模式选择,将工作模式设置为STA,数据传输模式设置为Through。然后点击配置该页使其生效。如图7所示:
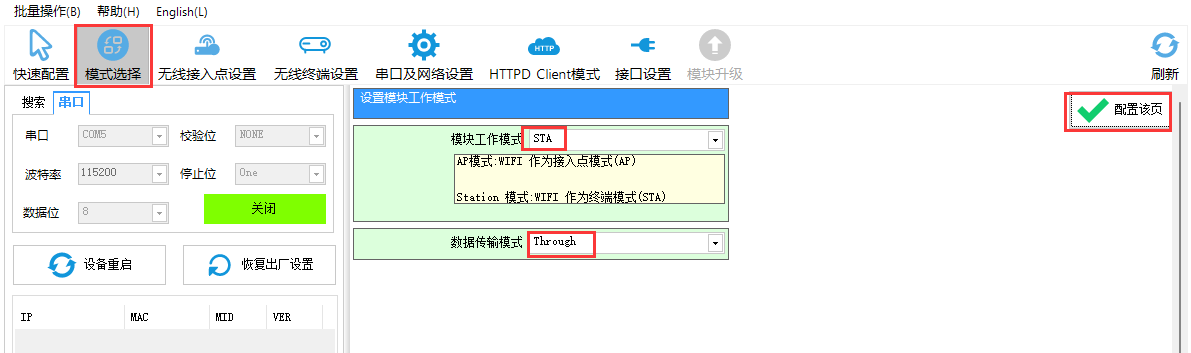
图7 工作模式
- 点击
无线终端设置,点击 搜索 按钮,找到刚才设置的路由器的WIFI名称,同时输入密码。接着将该模块的IP地址设置为固定IP。然后点击配置该页使其生效
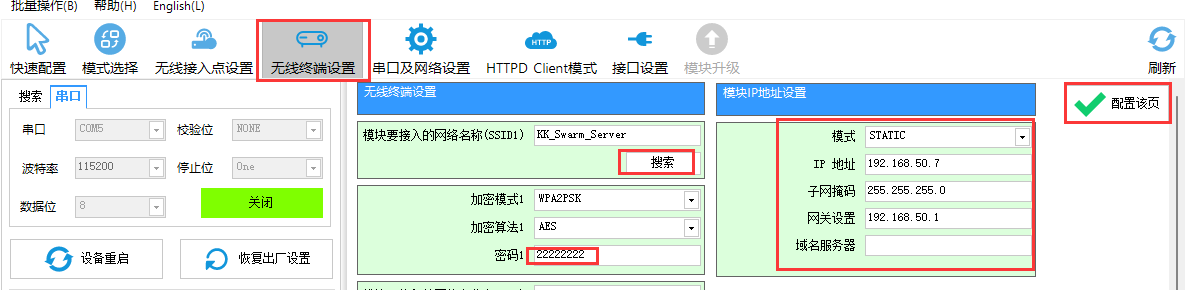
图8 无线终端设置
提示
这里说明一下IP和小车的关系:
- 小车WIFI模块和小车本身 不是强绑定,设定固定IP是为了方便查询小车连接状况和检查通信状况。您可以可以设置为动态IP
- 由于MINI主机的IP是
192.168.50.100,因此,每辆小车的固定IP为192.168.50.x,其中x为小车编号。这里为7号小车,故设置IP为192.168.50.17- 再次强调,固定小车IP为 可选项,可以设置为动态IP。
- 点击
串口及网络设置,务必按照图9红框所选设置。设置完成后,点击配置该页使其生效
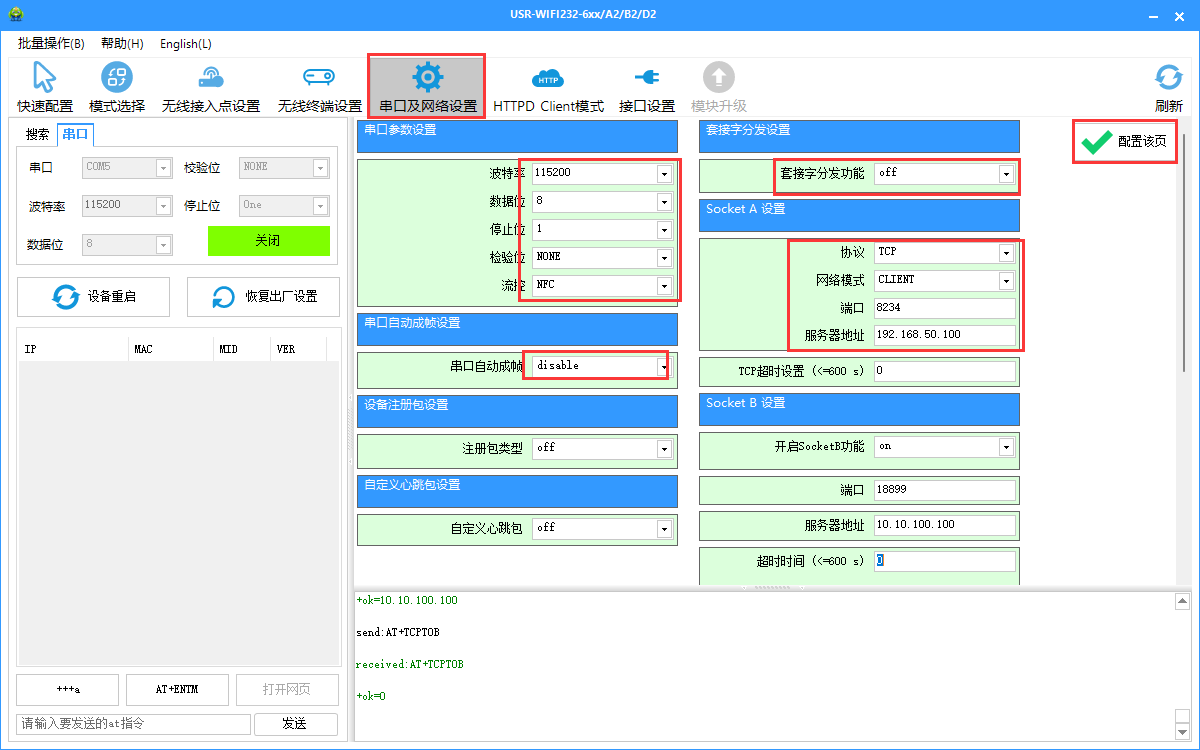
图9 串口及网络设置
- 在软件的左下角命令行处,输入命令
AT+FUARTTE=fast并点击 发送,如图10所示:
图10 发送指令
-
点击
设备重启完成配置 -
将 WIFI 模块重新安装在小车上
-
打开MINI主机的终端,输入命令:
roscore
- 打开终端,输入命令
rosrun tcp_communication tcpDriverNode
等待小车连接,如图11所示:
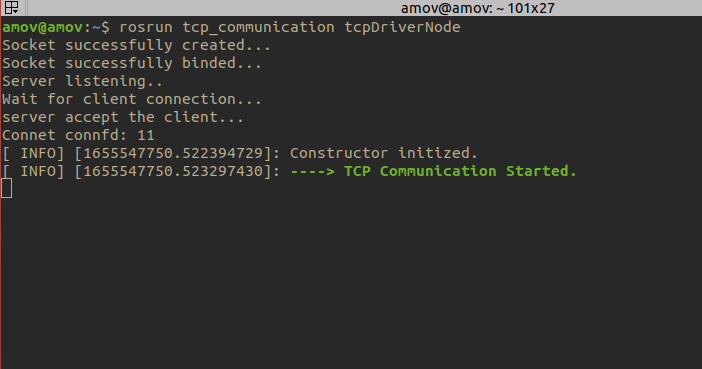
图11 连接成功
- 打开终端,输入命令
ping 192.168.50.17
观察是否连接成功。或者进入路由器的后台网址 http://router.asus.com 查看是否连接成功。如图12所示:
- 打开终端,启动键盘控制节点
python2 ~/kk-robot-swarm/swarm_control.py
通过键盘控制,观察小车是否收到控制指令。如果收到,表示WIFI配置成功。如果失败,请尝试从新开始设置
底层固件
本教程将会引导读者如何 上传小车底层固件 所需要的环境。
点击下方链接,进入下载界面。然后选择相应的小车固件下载即可。 固件下载
提示
选择相应的固件,鼠标右键点击,选择将 链接另存为,下载
硬件接口
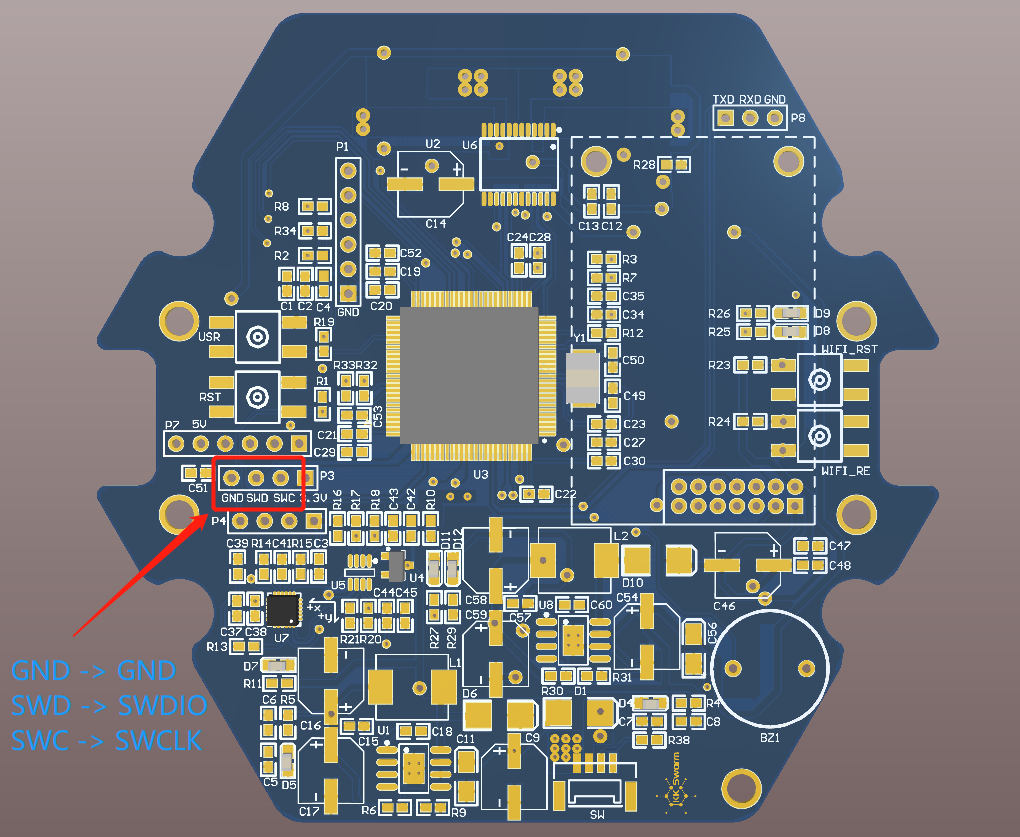
硬件接口图
如上图所示,红色框部分为驱动板下载口。
将STL设备一端按照 GND - GND, SWDIO - SWD, SWCLK - SWC 连接,另一端连接在电脑上。 同时打开小车电源。
下载STM32 ST-LINK Utility
点击这里下载安装 STM32 ST-LINK Utility 软件,或者前往 官方网站
下载安装完成以后,打开软件。如下图所示:点击菜单栏上的 Target -- Connect 连接到底板
连接底层驱动板
连接底层驱动板
加载相应小车的固件
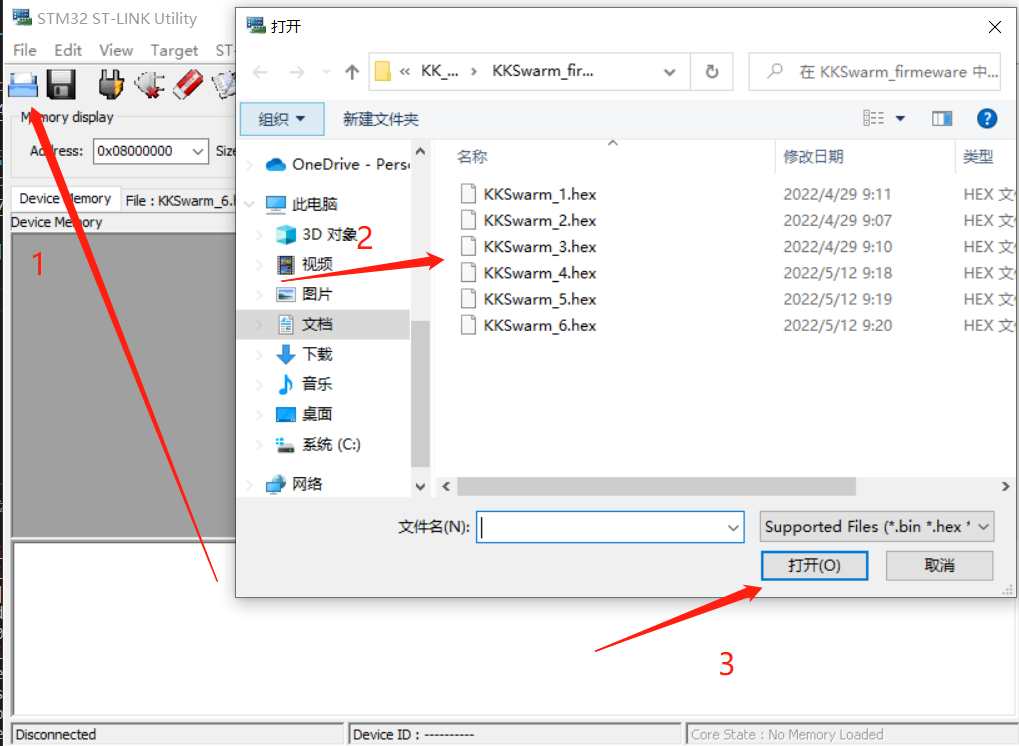
加载对应固件
上传程序
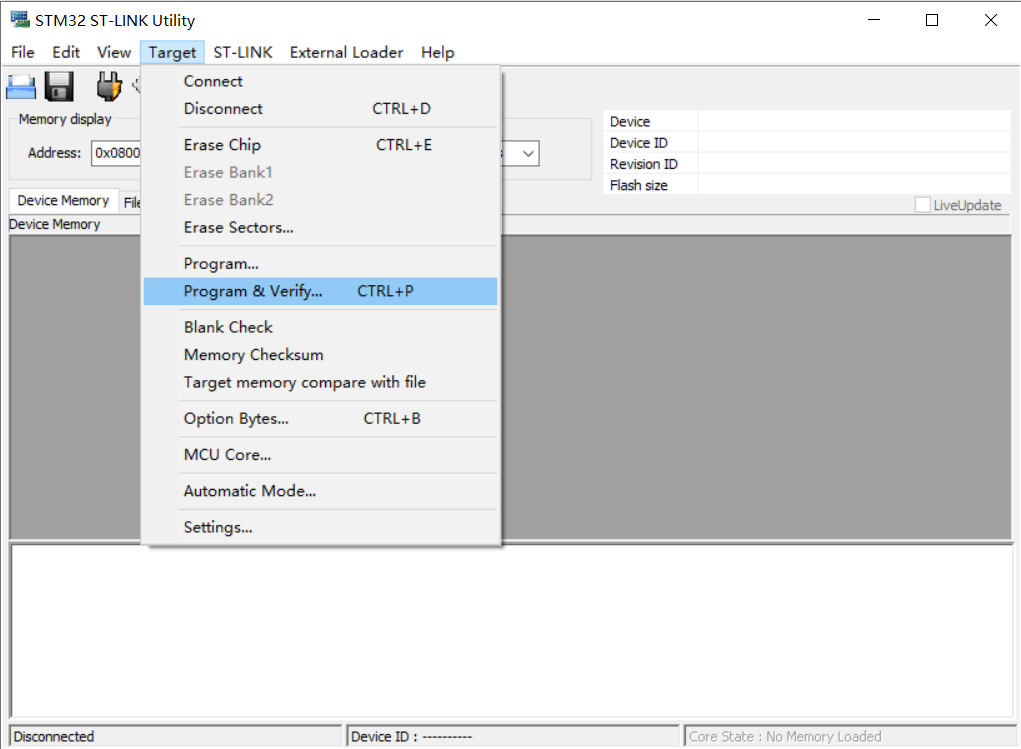
上传程序
在弹出的对话框中点击 start 开始上传,如下图所示:
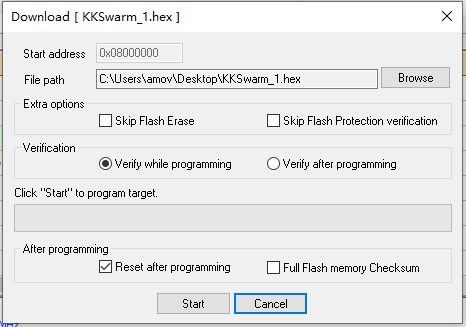
开始上传程序
上传完毕后,会看到软件出现如下提示。此时拔掉ST-LINK即可。
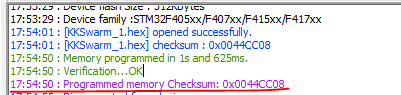
上传成功
数据采集
KKSWARM的一个特点是可以实现matlab仿真和ROS的无缝过渡。因此,可以在真车上用 rosbag 采集相关数据,然后将数据放在matlba中进行解析,从而生成对应的速度、位置等的图像,从而进行分析。
数据采集简介
采集数据的思路和流程如下:首先使用 rosbag;然后运行相关程序;接着系统将会自动记录相关数据;等待数据采集完成以后,关闭 rosbag;最后将数据包放在matlab下解析即可。
图1 rosbag数据采集流程
对于KKSWARM项目来说,在ROS下需要采集的数据有(以单车为例)
- /robot_1/pose
- /robot_1/cmd_vel
- /comm
具体操作步骤
以下操作均在Ubuntu环境下进行,以1号小车为例
- 将1号小车开机,等待连接至网络
- 根据 单车航点跟随 步骤启动单车航点
- 新开一个终端,输入命令
rosbag record /comm /robot_1/pose /robot_1/cmd_vel -o robot_1_waypoint.bag开始记录数据 - 等待程序执行完毕
- 关闭
rosbag
关于 rosbag 的详细介绍和使用,点击 rosbag,获取更多信息
数据解析
提示
点击这里下载示例bag,robot_1_waypoint.bag
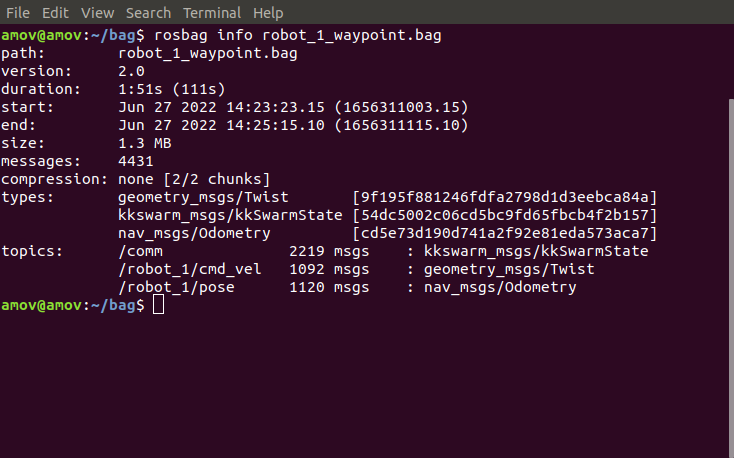
bag info
rosbag 命令行会将相关数据记录为一个 xxx.bag 文件,将文件拷贝至Windows下,再使用matlab进行解析即可。具体操作步骤如下
- 打开matlab
- 将读取rosbag的matlab代码和rosbag包放置在 同一路径下
- 打开
kk-robot-swarm/src/matlab/Read_Rosbag.mmatlab代码 - 将代码第二行
bagPath='robot_1_waypoint.bag';改为自己的bag包名称 - 点击菜单栏上的运行
- 此时将会弹出相应的分析窗口,如下图所示:
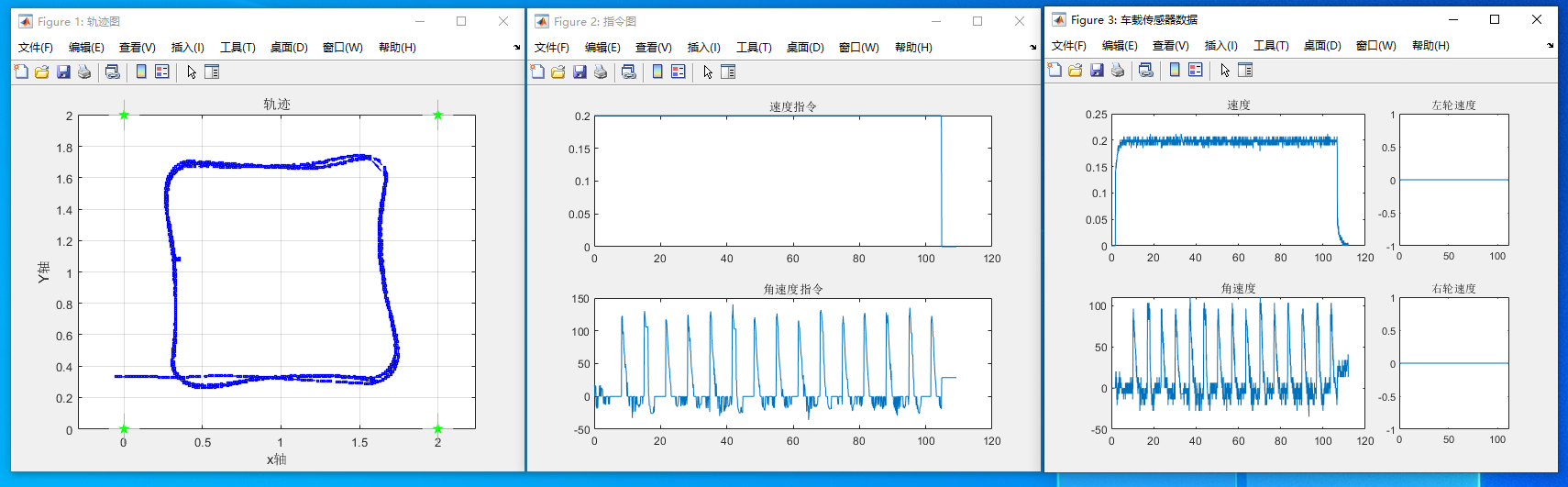
数据分析