原理讲解
-
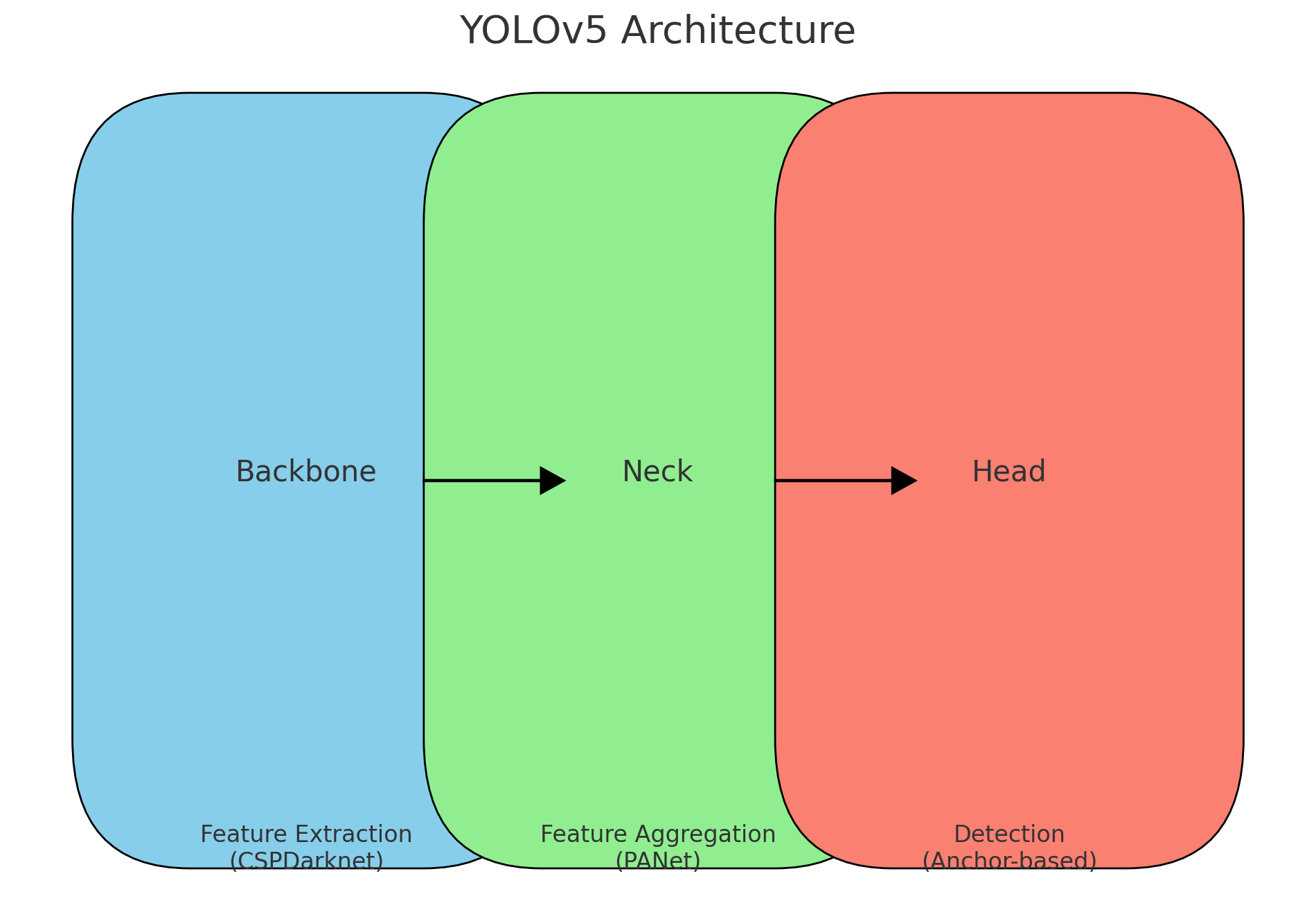
Backbone:特征提取网络,用于从输入图像中提取特征。YOLOv5使用的是CSPDarknet。
-
Neck:特征融合层,用于融合不同尺度的特征。YOLOv5采用的是PANet(Path Aggregation Network)。
-
Head:检测头,用于生成最终的检测结果,包括目标的类别和边界框。
详细流程
输入图像
输入图像被调整到统一的尺寸(如640x640像素),并进行归一化处理。
Backbone(特征提取)
Backbone部分采用CSPDarknet,该网络通过多个卷积层和残差块,从图像中提取出多层次的特征。
Neck(特征融合)
Neck部分使用了PANet,结合了不同层次的特征,通过上采样和下采样操作,使得高层特征和低层特征有效融合,从而提高了检测效果。
Head(检测头)
Head部分采用了YOLOv5的检测头,分为三个尺度(大、中、小),每个尺度负责检测不同大小的目标。每个尺度上的每个位置会预测一个锚框,并给出该框的类别概率和边界框偏移量。
损失函数
YOLOv5的损失函数由三部分组成:
-
边界框回归损失:用于衡量预测边界框与真实边界框的差异,通常使用GIoU或DIoU损失。
-
置信度损失:用于衡量是否存在目标的置信度差异。
-
类别损失:用于衡量预测类别与真实类别的差异,通常使用交叉熵损失。
训练和推理
训练
训练过程中,模型通过前向传播计算输出,通过损失函数计算误差,再通过反向传播更新模型参数。YOLOv5采用了数据增强技术,如随机裁剪、颜色抖动等,提升模型的鲁棒性。
推理
推理过程中,输入图像经过模型后,输出检测结果。通过NMS(非极大值抑制)处理,去除冗余的检测框,只保留置信度最高的框。
优势与改进
YOLOv5相比于之前版本和其他目标检测模型,具有以下优势:
-
高效:能在保持高精度的同时,实现实时检测。
-
简洁:模型架构简洁,易于理解和实现。
-
灵活:支持多种输入尺寸,能够检测多尺度目标。
-
增强训练:采用了更好的数据增强和损失函数,提高了模型性能。